分类问题的评价指标
一、logistic regression
logistic regression也叫做对数几率回归。虽然名字是回归,但是不同于linear regression,logistic regression是一种分类学习方法。
同时在深度神经网络中,有一种线性层的输出也叫做logistic,他是被输入到激活函数中的输入如下图所示。

Softmax和sigmoid的输出不同,sigmoid输出的是每一个种类成为
二、分类算法的评价指标 <分类算法评价指标详解 - 知乎>
首先,机器学习分类任务的常用评价指标:混淆矩阵(Confuse Matrix)、准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 Score、P-R曲线(Precision-Recall Curve)、ROC、AUC。
混淆矩阵:每行显示样本预测到的值,列显示标签的值。针对一个二分类问题,可以将其分为四种
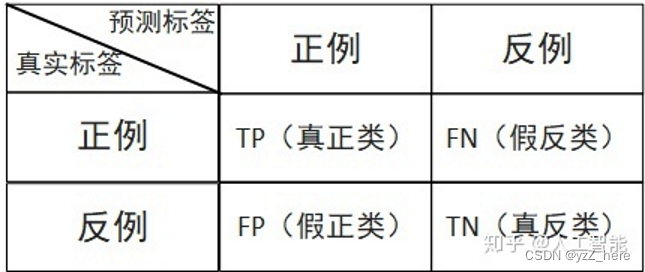
TP:True Positive 表示真的正类
TN:True Negative 真的负类
FP:False Positive 假的正类
FN:False Negative 假的负类 这些都可以从混淆矩阵中得出。
1.准确率 Accuracy
Acc=(TP+TN)/(TP+TN+FP+FN)
预测结果中的所有预测争取的类别比左右的预测结果。即混淆矩阵对角元素和所有元素的比值。
准确率有一个缺点,就是数据的样本不均衡,这个指标是不能评价模型的性能优劣的。
假如一个测试集有正样本99个,负样本1个。模型把所有的样本都预测为正样本,那么模型的Accuracy为99%,看评价指标,模型的效果很好,但实际上模型没有任何预测能力。
2.精确度precision
在模型预测为正样本的结果中,真正是正样本所占的百分比,具体公式如下:
Pre = TP / (TP+TF)
在预测为正样本的结果中,真的正样品的占比。
3.召回率recall
在实际正样本中,预测为真的正样本占所有正样本的比值
Recall= TP / (TP+TN)
4.F1 sore
Recall和precision之间会有一个此消彼长的关系,如果要兼顾二者,就需要F1 Score,F1 Score是一种调和平均数。
F1 Score = (2*Pre*Recall)/ (Pre+Recall)
同时还有一种,P-R曲线(precision -Recall)描述精确率和召回率变化。

模型与坐标轴围成的面积越大,则模型的性能越好。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
线性回归模型和logistic回归模型
