目录自动清洗
文章目录
- 前言
- 一、需求分析
- 二、操作步骤详解(标准章节)
- 1. 提取文章目录
- 2. 更改保存目录.txt
- 3. 二级标题前面加4个空格
- 4. 在章字和节字后面添加一个空格
- 5. 在页码前面加上=>符号
- 6. 代码完全体
- 三、进阶一(有章无节+小数二级标题)
- 1. 二级标题前面加4个空格
- 2. 在标题里面添加一个空格
- 3. 在页码前面加上=>符号
- 4. 去除=>符号和汉字之间的冗余符号
- 5. 删除空行
- 6. 代码完全体
- 7. 进阶说明
- 拓展与补充
- 1. content = file.read() 与 lines = file.readlines() 读取文件的区别
- 总结
前言
为了巩固所学的知识,作者尝试着开始发布一些学习笔记类的博客,方便日后回顾。当然,如果能帮到一些萌新进行新技术的学习那也是极好的。作者菜菜一枚,文章中如果有记录错误,欢迎读者朋友们批评指正。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)
一、需求分析

1. 这是一个标准的章节目录,我们需要保留目录的前两级标题,也就是包含章和节字的标题
2. 需要在二级标题所在行最前面空4个格子,一级标题不用
3. 需要在章和节字的后面加上一个空格
4. 需要在页码前面加上=>符号
5. 示例效果如下:

二、操作步骤详解(标准章节)
1. 提取文章目录
1. 图片识别文字提取文章目录
http://183.62.34.62:8004/docs#/defaul/text_detection_text_system_analysis_menus__post
2. 使用方法
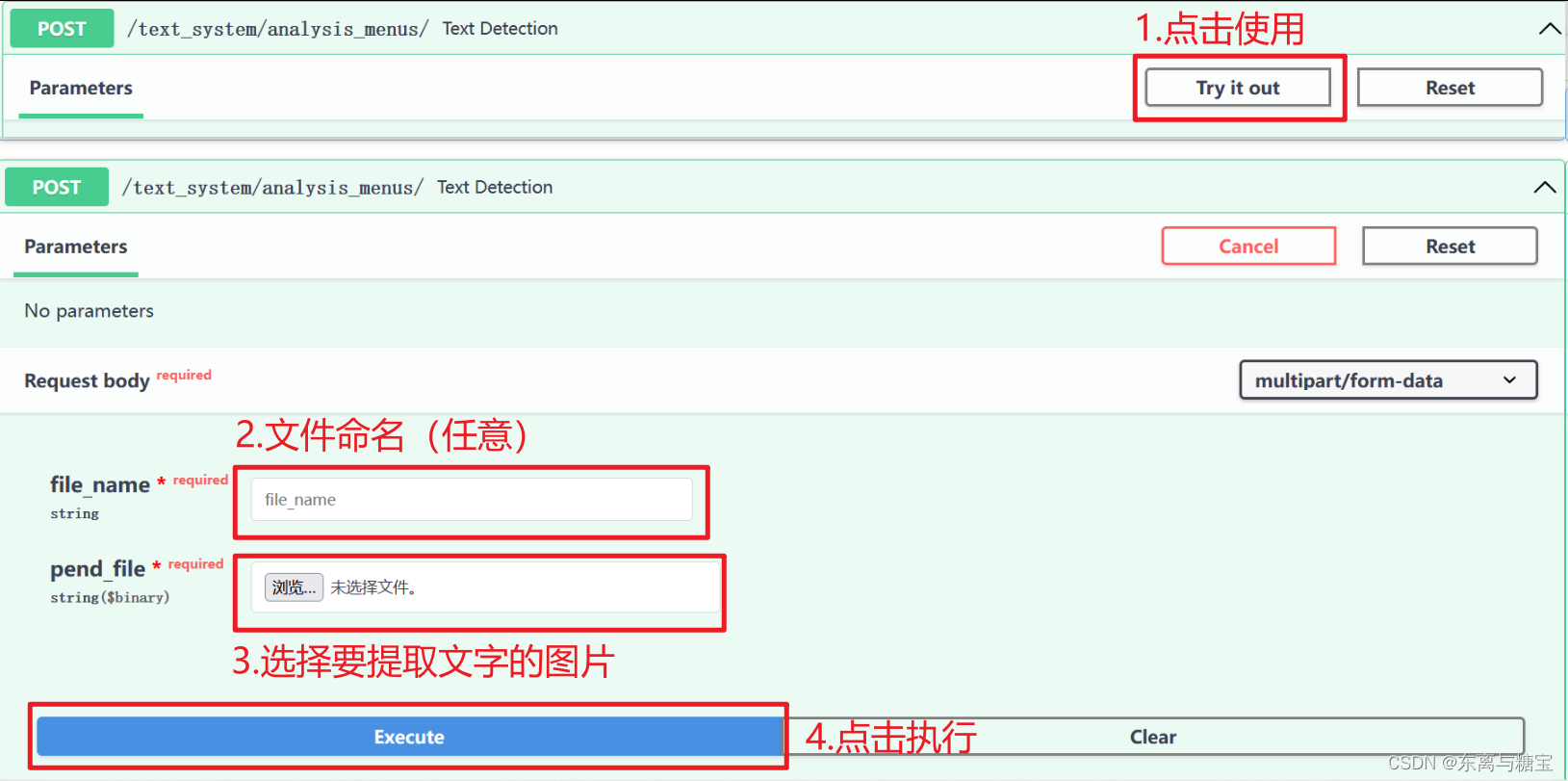
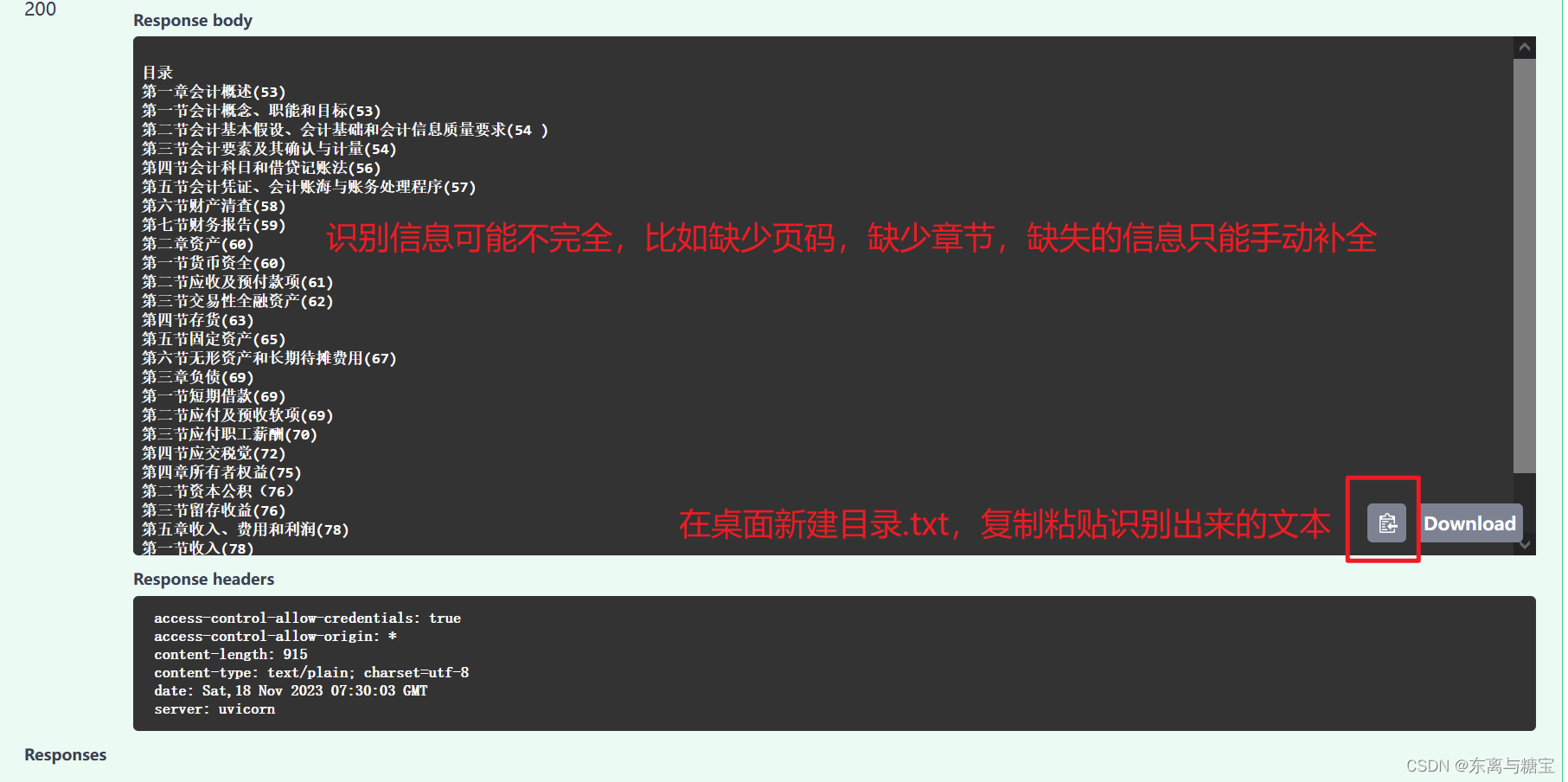
3. 识别示例
2. 更改保存目录.txt
你可以使用Python中的open函数来打开文件,read方法读取文件内容,然后对内容进行修改,最后使用write方法将修改后的内容写回文件。以下是一个简单的例子:
import os
# 获取桌面路径
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
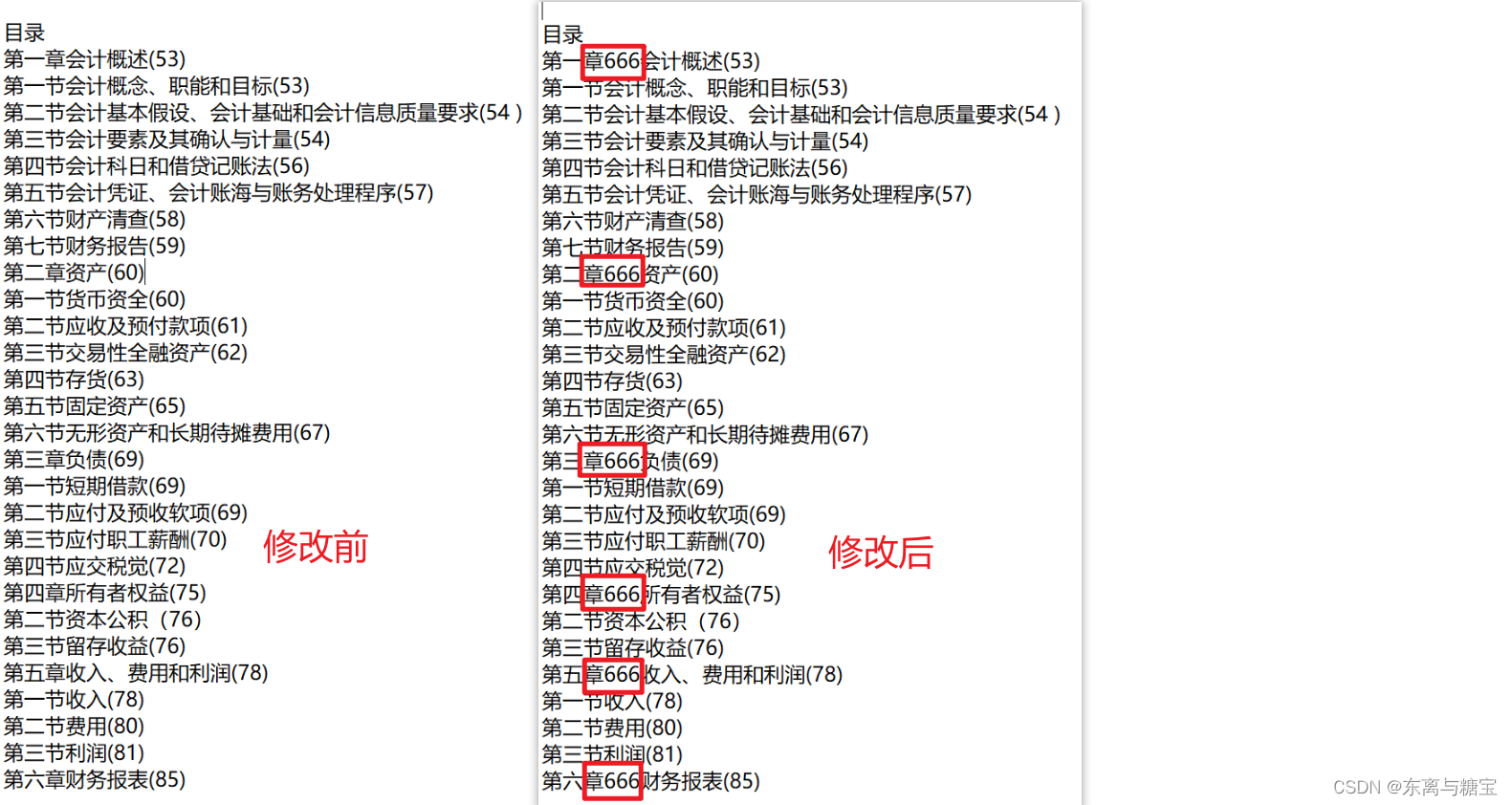
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()# 修改内容(这里只是一个简单的例子)
modified_content = content.replace('章', '章666')# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.write(modified_content)
请确保你有足够的权限读取和写入文件。此外,这只是一个简单的例子,如果需要进行更复杂的操作,可以使用正则表达式或其他处理方式来实现。
3. 二级标题前面加4个空格
# 去除空格line = line.replace(" ", "")if '节' in line:# 二级标题添加4个空格line = ' ' * 4 + line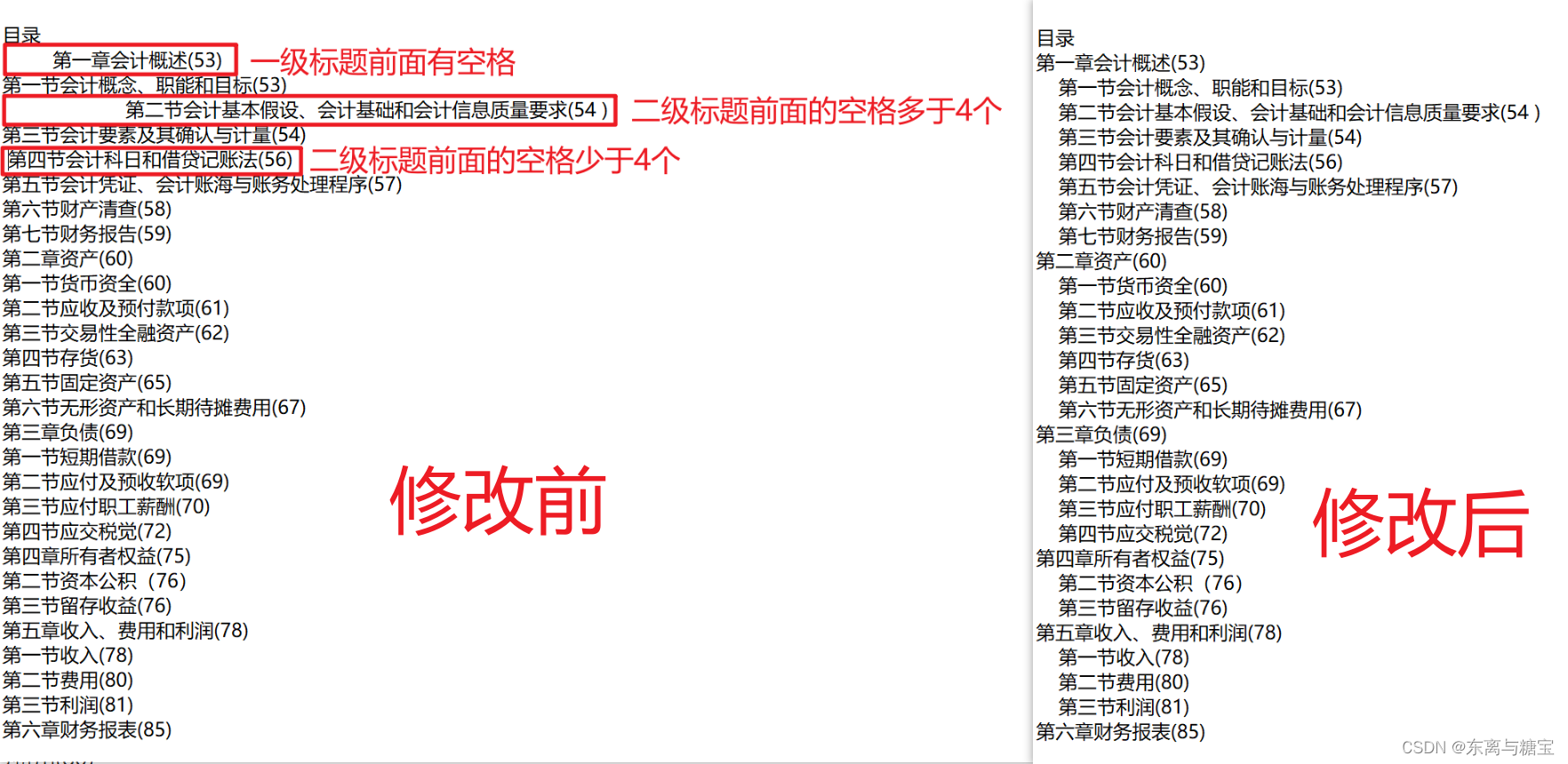
lstrip(' ') 是 Python 字符串方法,用于删除字符串开头(左侧)的指定字符。在这里,' ' 表示空格字符。
4. 在章字和节字后面添加一个空格
# 使用正则表达式在'章'或'节'后面添加一个空格line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)
5. 在页码前面加上=>符号
# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括空格)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)line = line.replace(" ", "")# 确保每行只有一个 =>if '=>' not in line:# 在每行数字前加上 =>line = re.sub(r'(\d+)', r'=>\1', line)
6. 代码完全体
# 获取桌面路径
import os
import redesktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:lines = file.readlines()modified_lines = []
for line in lines:# 去除空格line = line.replace(" ", "")# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在每行数字前加上 =>line = re.sub(r'(\d+)', r'=>\1', line)# 使用正则表达式在'章'或'节'后面添加一个空格line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)if '节' in line:# 二级标题添加4个空格line = ' ' * 4 + linemodified_lines.append(line)
# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.writelines(modified_lines)# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()print(content)三、进阶一(有章无节+小数二级标题)

1. 二级标题前面加4个空格
如果章字不在行内,则初步认定他为二级标题
# 去除空格line = line.replace(" ", "")if '章' not in line:# 二级标题添加4个空格line = ' ' * 4 + line
2. 在标题里面添加一个空格
# 使用正则表达式在'章'或'节'后面添加一个空格,仅在后面没有空格的情况下line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)# 在小数点后添加空格line = re.sub(r'(\.\d)', r'\1 ', line)
3. 在页码前面加上=>符号
# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在页码数字前添加 =>(只在行尾)line = re.sub(r'(\d+)$', r'=>\1', line)
4. 去除=>符号和汉字之间的冗余符号
# 去除中文汉字和'=>整体符号左边的冗余符号pattern = r'([\u4e00-\u9fff]+)[^\w\s]+=>'line = re.sub(pattern, r'\1=>', line)
5. 删除空行
# 去除空格line = line.replace(" ", "")if len(line) == 1:continue
6. 代码完全体
# 获取桌面路径
import os
import redesktop_path = os.path.join(os.path.expanduser("~"), "Desktop")# 目标文件路径
file_path = os.path.join(desktop_path, "目录.txt")# 打开文件并读取内容
with open(file_path, 'r', encoding='utf-8') as file:lines = file.readlines()modified_lines = []
for line in lines:# 去除空格line = line.replace(" ", "")# 使用正则表达式在'章'或'节'后面添加一个空格,仅在后面没有空格的情况下line = re.sub(r'(章|节)(?![ ])', r'\1 ', line)# 在小数点后添加空格line = re.sub(r'(\.\d)', r'\1 ', line)if '章' not in line:# 二级标题添加4个空格line = ' ' * 4 + line# 匹配并去除最外层的英文括号pattern_en = r'\(([\d\s]+)\)'line = re.sub(pattern_en, r'\1', line)# 匹配并去除最外层的中文括号及其内部内容(包括除数字和空格以外的字符)pattern = r'(([^)]+))'line = re.sub(pattern, r'\1', line)# 确保每行只有一个 =>if '=>' not in line:# 在页码数字前添加 =>(只在行尾)line = re.sub(r'(\d+)$', r'=>\1', line)modified_lines.append(line)
# 将修改后的内容写回文件
with open(file_path, 'w', encoding='utf-8') as file:file.writelines(modified_lines)# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:content = file.read()print(content)7. 进阶说明
1. 兼容标准章节版本
2. 章和章之间识别为第二级目录
3. 只在标题末尾页码数字添加=>符号
4. 去除箭头和汉字之间识别出来的冗余符号
5. 去除空行
拓展与补充
1. content = file.read() 与 lines = file.readlines() 读取文件的区别
在 Python 中,file.read() 和 file.readlines() 两者可以在同一个文件句柄中使用,但是要注意的是,file.read() 会读取整个文件内容为一个字符串,而 file.readlines() 会读取整个文件内容并将每一行作为一个字符串放入列表中
如果你使用了 file.read(),那么之后再使用 file.readlines() 将不会得到任何内容,因为文件指针已经在文件的末尾。如果需要再次读取文件,你可以使用 file.seek(0) 将文件指针重新定位到文件的开头
以下是一个演示的例子:
# 使用 file.read()
with open('example.txt', 'r', encoding='utf-8') as file:content = file.read()print(content)# 使用 file.readlines(),注意在上面使用了 file.read() 之后,需要重新打开文件或者使用 file.seek(0)
with open('example.txt', 'r', encoding='utf-8') as file:file.seek(0)lines = file.readlines()print(lines)
总的来说,两者是可以在同一个文件句柄中使用的,只是需要注意文件指针的位置。
总结
欢迎各位留言交流以及批评指正,如果文章对您有帮助或者觉得作者写的还不错可以点一下关注,点赞,收藏支持一下。
(博客的参考源码可以在我主页的资源里找到,如果在学习的过程中有什么疑问欢迎大家在评论区向我提出)