CSDN每日一题学习训练——Python版(简化路径,不同的二叉搜索树)
版本说明
当前版本号[20231116]。
| 版本 | 修改说明 |
|---|---|
| 20231116 | 初版 |
目录
文章目录
- 版本说明
- 目录
- 简化路径
- 题目
- 解题思路
- 代码思路
- 参考代码
- 不同的二叉搜索树
- 题目
- 解题思路
- 代码思路
- 参考代码
简化路径
题目
给你一个字符串 path ,表示指向某一文件或目录的 Unix 风格 绝对路径 (以 ‘/’ 开头),请你将其转化为更加简洁的规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (…) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。任意多个连续的斜杠(即,‘//’)都被视为单个斜杠 ‘/’ 。 对于此问题,任何其他格式的点(例如,‘…’)均被视为文件/目录名称。
请注意,返回的 规范路径 必须遵循下述格式:
始终以斜杠 ‘/’ 开头。
两个目录名之间必须只有一个斜杠 ‘/’ 。
最后一个目录名(如果存在)不能 以 ‘/’ 结尾。
此外,路径仅包含从根目录到目标文件或目录的路径上的目录(即,不含 ‘.’ 或 ‘…’)。
返回简化后得到的 规范路径 。
示例 1:
输入:path = “/home/”
输出:“/home”
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:path = “/…/”
输出:“/”
解释:从根目录向上一级是不可行的,因为根目录是你可以到达的最高级。
示例 3:
输入:path = “/home//foo/”
输出:“/home/foo”
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:path = “/a/./b/…/…/c/”
输出:“/c”
提示:
1 <= path.length <= 3000
path 由英文字母,数字,‘.’,‘/’ 或 ‘_’ 组成。
path 是一个有效的 Unix 风格绝对路径。
解题思路
解题思路:
- 创建一个空列表 result,用于存储简化后的路径。
- 将输入的路径字符串 path 按照斜杠 ‘/’ 进行分割,得到一个列表 plist。
- 遍历 plist 中的每个元素 pos。
- 如果 pos 不为空,则进行以下判断:
- 如果 pos 等于 ‘…’,表示需要返回上一级目录。尝试从 result 中弹出最后一个元素(即返回上一级目录)。如果 result 为空,则将其重置为空列表。
- 如果 pos 不等于 ‘.’,表示当前目录或文件名有效。将其添加到 result 列表中。
- 如果 pos 不为空,则进行以下判断:
- 使用 join() 方法将 result 列表中的元素用斜杠 ‘/’ 连接起来,并在前面加上一个斜杠作为根目录。
- 返回简化后的规范路径。
代码思路
-
先定义了一个名为
Solution的类,并在其中实现了一个名为simplifyPath的方法。该方法接受一个字符串类型的参数path,表示要简化的文件路径。def simplifyPath(self, path): -
在方法内部,首先定义了一个空列表
result,用于存储简化后的路径。然后,使用split('/')方法将输入的路径按照斜杠分割成一个列表plist,其中每个元素表示路径中的一个目录或文件名。result = [] # 初始化结果列表plist = path.split('/') # 将路径按照斜杠分割成列表 -
接下来,使用一个循环遍历
plist中的每个元素。如果当前元素不为空,则进行以下判断: -
-
如果当前元素为
..,表示需要返回上一级目录。此时,尝试从result中弹出最后一个元素(即返回上一级目录)。如果result为空,则将其重置为空列表。for pos in plist: # 遍历列表中的每个元素if pos: # 如果元素不为空if pos == '..': # 如果元素为'..',表示返回上一级目录try:result.pop() # 弹出结果列表中最后一个元素except:result = [] # 如果结果列表为空,则将其重置为空列表 -
如果当前元素不为
.,表示当前目录或文件名有效。将其添加到result列表中。elif pos != '.': # 如果元素不为'.',表示当前目录result.append(pos) # 将当前目录添加到结果列表中
-
-
最后,使用
join()方法将result列表中的元素用斜杠连接起来,并在前面加上一个斜杠作为根目录。最终返回简化后的路径。return '/' + '/'.join(result) # 将结果列表中的元素用斜杠连接起来,并在前面加上一个斜杠作为根目录 -
在代码的最后,创建了一个
Solution类的实例s,并调用其simplifyPath方法,传入一个示例路径/home/,并将结果打印输出。
s = Solution() # 创建Solution类的实例
print(s.simplifyPath(path="/home/")) # 调用simplifyPath方法,传入路径参数,并打印结果
参考代码
这段代码主要是使用栈来处理路径中的目录和文件名。
class Solution(object):def simplifyPath(self, path):""":type path: str:rtype: str"""result = []plist = path.split('/')for pos in plist:if pos:if pos == '..':try:result.pop()except:result = []elif pos != '.':result.append(pos)return '/'+'/'.join(result)
# %%
s = Solution()
print(s.simplifyPath(path = "/home/"))
不同的二叉搜索树
题目
给你一个整数 n ,求恰由 n 个节点组成且节点值从 1 到 n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:
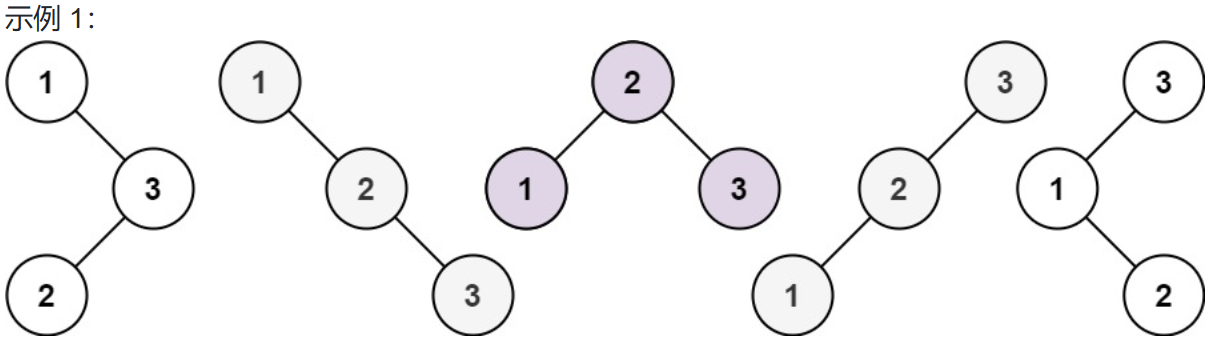
输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
提示:
1 <= n <= 19
解题思路
-
这个问题可以使用动态规划来解决。我们可以定义一个数组dp,其中dp[i]表示由i个节点组成的二叉搜索树的种数。根据题目要求,我们可以得到以下状态转移方程:
dp[i] = Σ(dp[j-1] * dp[i-j]) (j=1,2,...,i) -
这个方程的含义是,对于每个节点i,它有左子树和右子树,左子树的节点数为j-1,右子树的节点数为i-j。因此,我们需要遍历所有可能的j值,计算出对应的二叉搜索树的种数,并将它们累加起来。
代码思路
-
初始化一个长度为n+1的动态规划数组dp,初始值为0。
# 初始化动态规划数组,长度为n+1,初始值为0dp = [0] * (n + 1) -
当节点数为0时,只有一种可能,即空树,所以将dp[0]设为1。
-
当节点数为1时,只有一种可能,即只有一个节点的树,所以将dp[1]设为1。
# 当节点数为0时,只有一种可能,即空树dp[0] = 1# 当节点数为1时,只有一种可能,即只有一个节点的树dp[1] = 1 -
从第2个节点开始遍历到第n个节点,对于每个节点level,遍历所有可能的根节点root。
# 从第2个节点开始遍历到第n个节点for level in range(2, n + 1):# 对于每个节点,遍历所有可能的根节点for root in range(1, level + 1): -
根据组合数公式,计算当前节点数下,以root为根节点的二叉搜索树的数量。具体计算公式为:dp[level] += dp[level - root] * dp[root - 1]。
# 根据组合数公式,计算当前节点数下,以root为根节点的二叉搜索树的数量dp[level] += dp[level - root] * dp[root - 1] -
返回给定节点数下的二叉搜索树数量,即dp[n]。
# 返回给定节点数下的二叉搜索树数量return dp[n] -
创建Solution对象s,并调用numTrees方法,传入节点数n=3,计算节点数为3的二叉搜索树数量,并打印结果。
# 创建Solution对象
s = Solution()
# 调用numTrees方法,计算节点数为3的二叉搜索树数量,并打印结果
print(s.numTrees(n = 3))参考代码
这段代码是一个计算给定节点数的二叉搜索树数量的函数。它使用了动态规划的方法,通过遍历每个节点和所有可能的根节点,计算出以当前节点为根节点的二叉搜索树的数量。最后返回给定节点数下的二叉搜索树数量。
class Solution(object):def numTrees(self, n):""":type n: int:rtype: int"""dp = [0] * (n + 1)dp[0] = 1dp[1] = 1for level in range(2, n + 1):for root in range(1, level + 1):dp[level] += dp[level - root] * dp[root - 1]return dp[n]
# %%
s = Solution()
print(s.numTrees(n = 3))