ElasticSearch 增删改查操作
本文主要是介绍 ElasticSearch 的文档增删改查和批量操作,同时会介绍一些 REST API 返回状态码的具体含义。
我们先来看下这个表:

这个表包含了 Index、Create、Read、Update、Delete 这五种方法,我们先来看下 CRUD 操作的 HTTP 请求都长什么样子?
首先是提供一个 HTTP 的 method,后面是索引名字,在 7.0 之后所以的 Type 都用 _doc 表示,后面是文档 id。
再简单了解了 CURD 操作的 HTTP 请求后,那么让我们先来了解下如何创建文档:
1 创建文档

Create 支持两种方式,一种是指定文档 id 创建文档,像上面这张图就是;另一种是通过调用 post /users/_doc 去让 ES 自动生成文档 id。
自己指定文档 id创建文档,需要考虑 id 的均衡性,避免产生分配不均衡的问题。ES 的 hash 函数会确保文档 id 被均匀分配到不同的分片。
当我们执行刚才的命令,可以返回如下结果:

其中 _version 每一次操作,都会 + 1,它是一个锁的机制,当并行修改文档的时候,更新的版本号比文档当前的版本号小时就会报错,不允许做修改。
创建文档时,如果索引不存在,ES 会自动创建对应的 index 和 type。
接下来看下另一种创建文档的方式,不指定 id 创建文档,HTTP 请求也变为了 POST,具体的请求如下:

返回的结果如下:

Index 和 Create 区别为:如果文档不存在,就索引新的文档,否则现有文档就会被删除,新的文档被索引,版本信息 _version + 1。
2 查询文档
Get 方法比较简单,只需要 Get 索引名称/_doc/文档 id,通过执行这个命令就可以知道文档的具体信息了。

当执行这条语句后会返回 HTTP 200,具体返回结果如下:

其中 _index 为索引,_type 为类型,_id 为文档 id,_version 为版本信息,_source 存储了文档的完整原始数据。
当查询的文档 id 不存在的时候,会返回 HTTP 404,且 found 为 false,具体结果如下:

2 更新文档
Update 方法采用 HTTP POST,在请求体中必须指明 doc,在把具体文档提供在 HTTP 的 body 里。Update 和 Index 方法不同,Update 方法不会删除原来的文档,而是实现真正的数据更新。
比如在原来的文档 id 为 1 的文档上增加字段,具体请求如下:

执行后,版本信息 _version + 1,让我们再去查询下该文档:

可以看到,新增字段已经成功了。
3 删除文档
Delete 方法也很简单,Delete 索引名称/_doc/文档 id 就可以了,在这里就不再做代码演示了。
在介绍完文档的基本 CRUD 操作后,让我们来看看批量操作吧:
4 Bulk API
在一个 REST 请求中,重新建立网络开销是十分损耗性能的,因此 ES 提供 Bulk API,支持在一次 API 调用中,对不同的索引进行操作,从而减少网络传输开销,提升写入速率。
它支持 Index、Create、Update、Delete 四种类型操作,可以在 URI 中指定索引,也可以在请求的方法体中进行。
同时多条操作中如果其中有一条失败,也不会影响其他的操作,并且返回的结果包括每一条操作执行的结果。
比如输入如下代码:
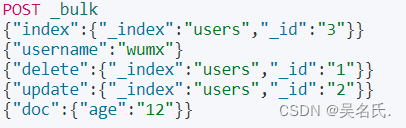
当我们执行命令后,结果如下:
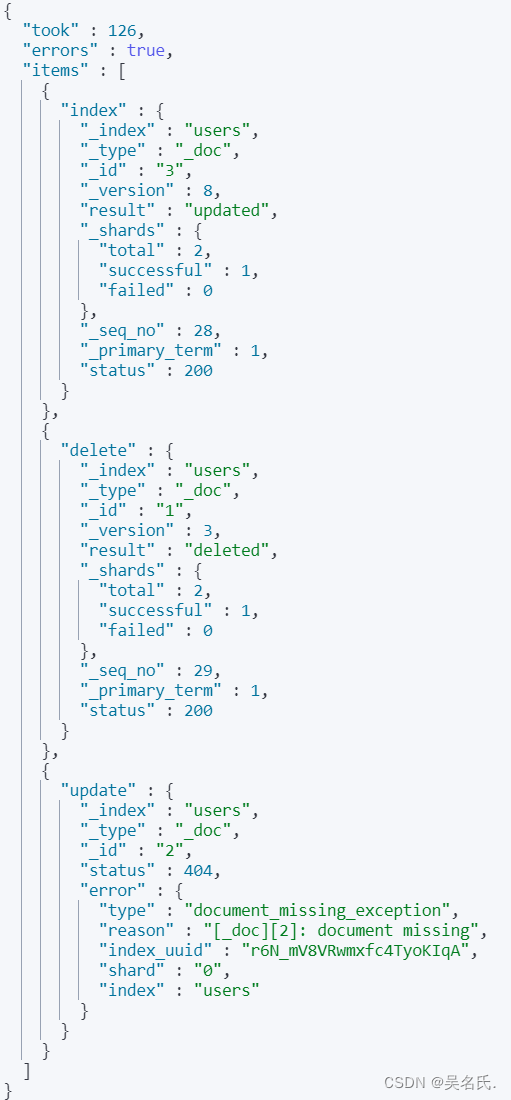
took 表示消耗了 93 毫秒,errors 为 true 表示在这些操作中错误发生,发现是 update 操作发生了错误,id 为 2 的文档不存在,所以报错了。
在使用 Bulk API 的时候,当 errors 为 true 时,需要把错误的操作修改掉,防止存到 ES 的数据有缺失。
5 批量查询文档
批量查询需要指明要查询文档的 id,可以在一个 _mget 操作里查询不同索引的数据,可以减少网络连接所产生的开销,提高性能。
下面我们来实际操作下,输入以下代码执行,就可以得到文档 id 为 1,3 的数据。

运行结果如下:
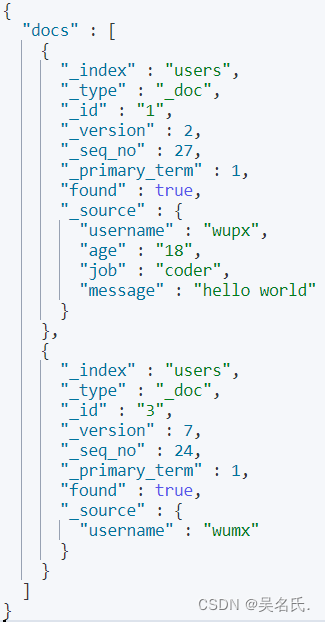
在介绍完文档的一些操作,最后让我们看下 REST API 常见错误返回有哪些吧!
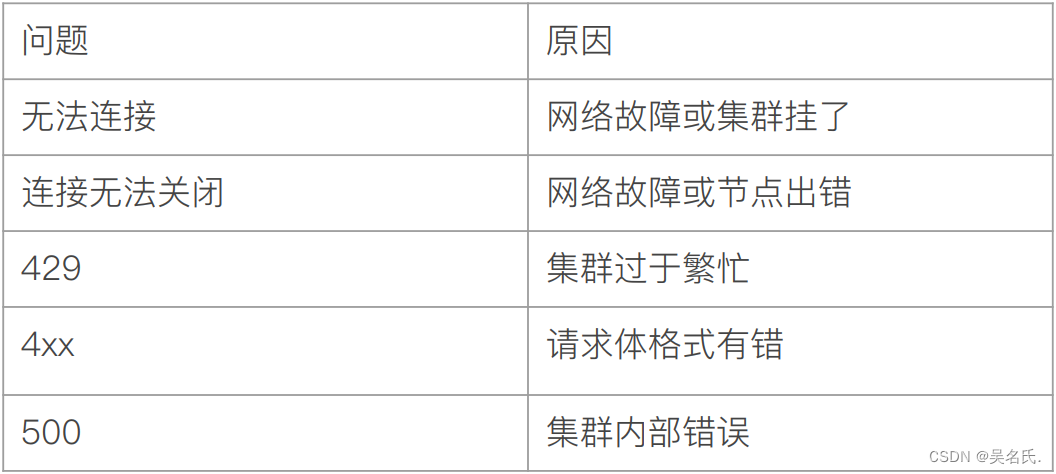
6 REST API 常见错误返回
刚才在演示中,当查询文档 id 不存在的时候就会报 404 错误,而且 ES 还有各种各样的返回,下面通过一个表格了解下:
7 总结
本文主要介绍了文档的 CRUD 操作,还有 Bulk API、_mget API,这些批量操作可以提高 API 调用性能,但是不要一次发送过多数据,也有可能会对 ES 集群产生过大的压力,导致性能有所下降。一般建议是 1000-5000 个文档,如果你的文档很大,可以适当减少队列,大小建议是 5-15 MB,默认不能超过 100 M。