数据结构哈希表(散列)Hash,手写实现(图文推导)
目录
一、介绍
二、哈希数据结构
三、✍️实现哈希散列
1. 哈希碰撞💥
2. 拉链寻址⛓️
3. 开放寻址⏩
4. 合并散列
一、介绍
哈希表,也被称为散列表,是一种重要的数据结构。它通过将关键字映射到一个表中的位置来直接访问记录,以此加快查找速度。这种映射函数被称为散列函数。哈希表的历史可以追溯到上个世纪 50 年代,由美国计算机科学家拉宾·珀尔(Rabin Pearl)和罗伯特·韦伯(Robert Weiss)发明。自那时以来,哈希表已经成为了计算机科学和编程中不可或缺的一部分,广泛应用于各种领域。
二、哈希数据结构
在计算机中,数据的存储结构主要有两种:数组和链表。数组的优势是长度固定,每个下标都指向唯一的一个值,但同时也存在长度固定的缺点。哈希表则是一种介于数组和链表之间,能够动态调整大小的数据结构。
- 使用数组存放元素,都是按照顺序存放的,当需要获取某个元素的时候,则需要对数组进行遍历,获取到指定的值,时间复杂度是 O(n)。
- 哈希表的主要优点在于它可以提供快速的插入操作和查找操作,无论哈希表中含有多少条数据,插入和查找的时间复杂度都是为 O(1),这一特性使得哈希表在处理大量数据时具有很高的效率。

三、✍️实现哈希散列
源码地址:hash_table
1. 哈希碰撞💥
说明:通过模拟简单 HashMap 实现,去掉拉链寻址等设计,验证元素索引位置的碰撞。
public class HashMap01<K, V> implements Map<K, V> {private Logger logger = LoggerFactory.getLogger(HashMap01.class);private Object[] tab = new Object[8];@Overridepublic void put(K key, V value) {int idx = key.hashCode() & (tab.length - 1);tab[idx] = value;}@Overridepublic V get(K key) {int idx = key.hashCode() & (tab.length - 1);return (V) tab[idx];}
}
- HashMap01 的实现只是通过哈希计算出的下标,散列存放到固定的数组内。那么这样当发生元素下标碰撞时,原有的元素就会被新的元素替换掉,即哈希碰撞。
测试
@Test
public void test_hashMap01() {Map<String, String> map = new HashMap01<>();map.put("01", "小火龙");map.put("04", "火爆猴");logger.info("碰撞前 key:{} value:{}","01",map.get("01"));// 模拟下标碰撞map.put("09","可达鸭");map.put("12","呆呆兽");logger.info("碰撞后 key:{} value:{}","01",map.get("01"));
}
10:50:36.662 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞前 key:01 value:小火龙
10:50:36.666 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞后 key:01 value:呆呆兽- 通过测试结果可以看到,碰撞前 map.get("01") 的值是 "小火龙",两次下标索引碰撞后存放的值则是 "呆呆兽"
- 这也就是使用哈希散列必须解决的一个问题,无论是在已知元素数量的情况下,通过扩容数组长度解决,还是把碰撞的元素通过链表存放,都是可以的。
2. 拉链寻址⛓️
说明:既然我们没法控制元素不碰撞,但我们可以对碰撞后的元素进行管理。比如像 HashMap 中拉链法一样,把碰撞的元素存放到链表上。这里我们就来简化实现一下。
public class HashMap02ByZipper<K, V> implements Map<K, V> {private LinkedList<Node<K, V>>[] tab = new LinkedList[8];@Overridepublic void put(K key, V value) {int idx = key.hashCode() & (tab.length - 1);if (tab[idx] == null) {tab[idx] = new LinkedList<>();tab[idx].add(new Node<>(key, value));} else {tab[idx].add(new Node<>(key, value));}}@Overridepublic V get(K key) {int idx = key.hashCode() & (tab.length - 1);for (Node<K, V> kvNode : tab[idx]) {if (key.equals(kvNode.getKey())) {return kvNode.getValue();}}return null;}static class Node<K, V> {final K key;V value;public Node(K key, V value) {this.key = key;this.value = value;}public K getKey() {return key;}public V getValue() {return value;}}
}
- 因为元素在存放到哈希桶上时,可能发生下标索引膨胀,所以这里我们把每一个元素都设定成一个 Node 节点,这些节点通过 LinkedList 链表关联,也可以通过 Node 节点构建出链表 next 元素即可。
- 那么这时候在发生元素碰撞,相同位置的元素就都被存放到链表上了,获取的时候需要对存放多个元素的链表进行遍历获取。
测试
@Test
public void test_hashMap02() {Map<String, String> map = new HashMap02ByZipper<>();map.put("01", "小火龙");map.put("04", "火爆猴");logger.info("碰撞前 key:{} value:{}","01",map.get("01"));// 模拟下标碰撞map.put("09","可达鸭");map.put("12","呆呆兽");logger.info("碰撞后 key:{} value:{}","01",map.get("01"));
}
12:19:15.505 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞前 key:01 value:小火龙
12:19:15.509 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞后 key:01 value:小火龙- 前后获取 "01" 位置元素都是 "小火龙" ,元素没有被替换,因为相同索引位置的元素放到链表上去了。
3. 开放寻址⏩
说明:除了对哈希桶上碰撞的索引元素进行拉链存放,还有不引入新的额外的数据结构,只是在哈希桶上存放碰撞元素的方式。它叫开放寻址,也就是 ThreaLocal 中运用斐波那契散列+开放寻址的处理方式。
public class HashMap03ByOpenAddressing<K, V> implements Map<K, V> {private final Node<K, V>[] tab = new Node[8];@Overridepublic void put(K key, V value) {int idx = key.hashCode() & (tab.length - 1);if (tab[idx] == null) {tab[idx] = new Node<>(key, value);} else {for (int i = idx; i < tab.length; i++) {if (tab[i] == null) {tab[i] = new Node<>(key, value);break;}}}}@Overridepublic V get(K key) {int idx = key.hashCode() & (tab.length - 1);for (int i = idx; i < tab.length; i++) {// 在开放寻址法中,如果tab[i]为null,则表示该位置没有存储任何元素,因此不需要进行后续的比较操作if (tab[i] != null && tab[i].key == key) {return tab[i].value;}}return null;}static class Node<K, V> {final K key;V value;public Node(K key, V value) {this.key = key;this.value = value;}}
}
- 开放寻址的设计会对碰撞的元素,寻找哈希桶上新的位置,这个位置从当前碰撞位置开始向后寻找,直到找到空的位置存放。
- 在 ThreadLocal 的实现中会使用斐波那契散列、索引计算累加、启发式清理、探测式清理等操作,以保证尽可能少的碰撞。
测试
@Test
public void test_hashMap03() {Map<String, String> map = new HashMap03ByOpenAddressing<>();map.put("01", "小火龙");map.put("04", "火爆猴");logger.info("碰撞前 key:{} value:{}","01",map.get("01"));// 模拟下标碰撞map.put("09","可达鸭");map.put("12","呆呆兽");logger.info("碰撞后 key:{} value:{}","01",map.get("01"));
}
15:57:33.310 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞前 key:01 value:小火龙
15:57:33.313 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞后 key:01 value:小火龙
15:57:33.313 [main] INFO com.pjp.hash_table.test.HashTableTest - 数据结构:HashMap{tab=[null,{"key":"01","value":"小火龙"},{"key":"09","value":"可达鸭"},{"key":"12","value":"呆呆兽"},{"key":"04","value":"火爆猴"},null,null,null]}- 通过测试结果可以看到,开放寻址对碰撞元素的寻址存放,也是可用解决哈希索引冲突问题的。
4. 合并散列
说明:合并散列是开放寻址和单独链接的混合,碰撞的节点在哈希表中链接。此算法适合固定📌分配内存的哈希桶,通过存放元素时识别哈希桶上的最大空槽位来解决合并哈希中的冲突。
public class HashMap04ByCoalescedHashing<K, V> implements Map<K, V> {private final Node<K, V>[] tab = new Node[8];@Overridepublic void put(K key, V value) {int idx = key.hashCode() & (tab.length - 1);if (tab[idx] == null) {tab[idx] = new Node<>(key, value);}int cursor = tab.length - 1;while (tab[cursor] != null && tab[cursor].key != key) {--cursor;}tab[cursor] = new Node<>(key, value);// 将被碰撞的节点指这个新节点// while 是为了处理被碰撞节点已经指向了节点,将被碰撞节点指向的节点指向新节点while (tab[idx].idxOfNext != 0) {idx = tab[idx].idxOfNext;}tab[idx].idxOfNext = cursor;}@Overridepublic V get(K key) {int idx = key.hashCode() & (tab.length - 1);while (tab[idx] != null && tab[idx].key != key) {idx = tab[idx].idxOfNext;}if (tab[idx] == null) {return null;}return tab[idx].value;}static class Node<K, V> {final K key;V value;int idxOfNext;public Node(K key, V value) {this.key = key;this.value = value;}public K getKey() {return key;}public V getValue() {return value;}public int getIdxOfNext() {return idxOfNext;}public void setIdxOfNext(int idxOfNext) {this.idxOfNext = idxOfNext;}}@Overridepublic String toString() {return "HashMap{" +"tab=" + JSON.toJSONString(tab) +'}';}
}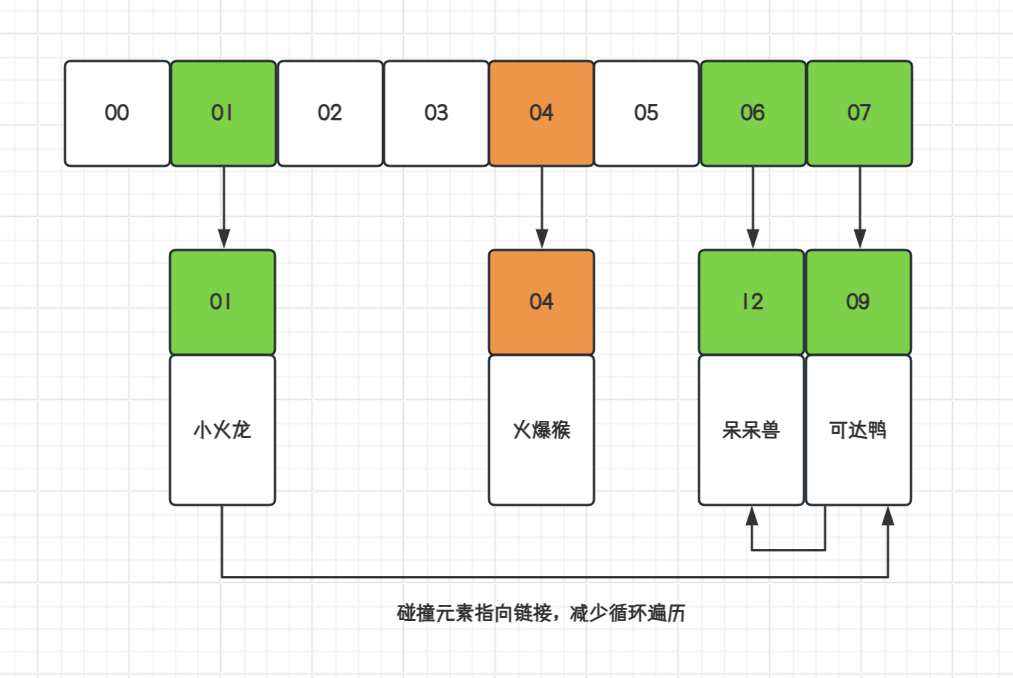
- 合并散列的最大目的在于将碰撞元素链接起来,避免因为需要寻找碰撞元素所发生的循环遍历。也就是A、B元素存放时发生碰撞,那么在找到A元素的时候可以很快的索引到B元素所在的位置。
同上面测试
15:57:53.650 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞前 key:01 value:小火龙
15:57:53.654 [main] INFO com.pjp.hash_table.test.HashTableTest - 碰撞后 key:01 value:小火龙
15:57:53.654 [main] INFO com.pjp.hash_table.test.HashTableTest - 数据结构:HashMap{tab=[null,{"idxOfNext":7,"key":"01","value":"小火龙"},null,{"idxOfNext":0,"key":"12","value":"呆呆兽"},{"idxOfNext":6,"key":"04","value":"火爆猴"},{"idxOfNext":3,"key":"09","value":"可达鸭"},{"idxOfNext":0,"key":"04","value":"火爆猴"},{"idxOfNext":5,"key":"01","value":"小火龙"}]}- 相对于直接使用开放寻址,这样的挂在链路指向的方式,可以提升索引的性能。因为在实际的数据存储上,元素的下一个位置不一定空元素,可能已经被其他元素占据,这样就增加了索引的次数。所以使用直接指向地址的方式,会更好的提高索引性能。