hadoop 大数据集群环境配置 配置hadoop配置文件 hadoop(七)
1. 虚拟机的三台机器分别以hdfs 存储, mapreduce计算,yarn调度三个方面进行集群配置
hadoop 版本3.3.4
官网:Hadoop – Apache Hadoop 3.3.6
jdk 1.8
三台机器尾号为:22, 23, 24。(没有用hadoop102, 103,104,我改为了hadoop22,hadoop23,hadoop24)

2. 配置22机器core-site.xml
cd $HADOOP_HOME/etc/hadoop
vi core-site.xml
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop22:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
</configuration>3. 配置22机器得hdfs-site.xml
<configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop22:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop24:9868</value></property>
</configuration>4. 配置22机器的yarn-site.xml
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop23</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>5.配置22机器的mapred-site.xml
<configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>6. 配置22机器workers文件:
hadoop22
hadoop23
hadoop24注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
7.脚本发送到23,24机器:
xsync /opt/module/hadoop-3.3.4/etc/hadoop
8. 分别去23,24机器检查下是否发送成功。上述修改的文件是否是修改过的数据:

9. 如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
生成机器id:
hdfs namenode -format10. 启动hdfs
# 例如我的路径/opt/module/hadoop-3.3.4/etc/hadoop
# 在hadoop文件下,前面你自己的路径/etc/hadoop/
# 输入命令
sbin/start-dfs.sh11. 在配置了ResourceManager的节点(hadoop23)启动YARN
sbin/start-yarn.sh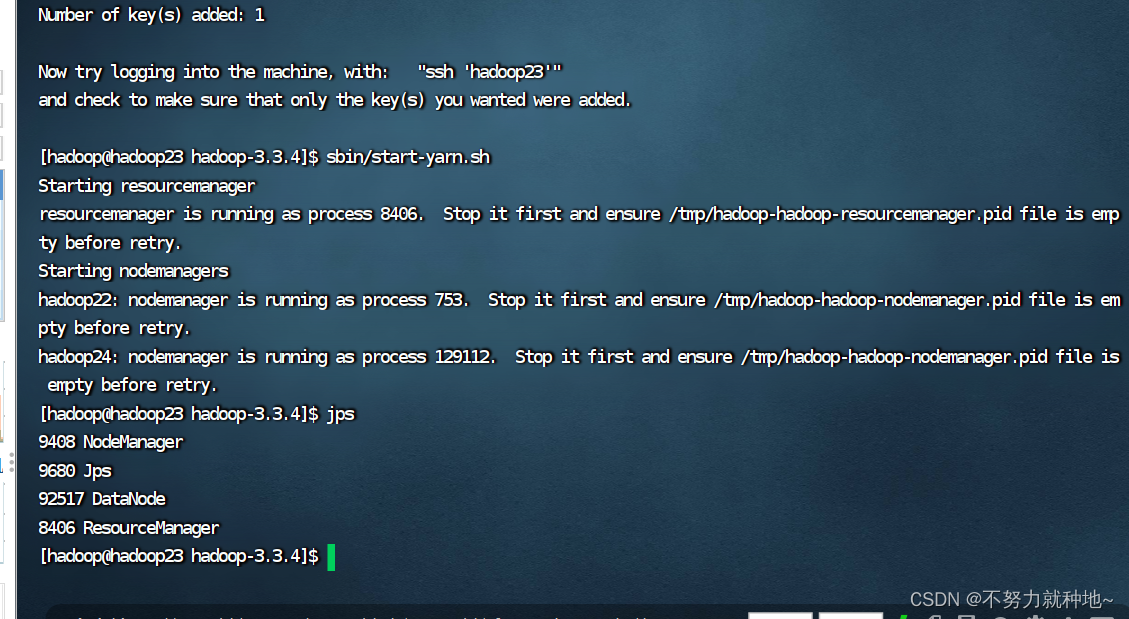
12. 如果启动失败,我是三台机器都删除了data,logs数据。重新从9步,重新生成机器id数据
比对配置文件是否错误,再次重新启动。即可解决~!