一文简单聊聊protobuf
目录
基本介绍
原理
同类对比
为什么要使用protobuf?
基本介绍
protobuf的全称是Protocol Buffer,是Google提供的一种数据序列化协议。Protocol Buffers 是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化,很适合做数据存储或 RPC 数据交换格式。它可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
结构化数据是最为常见和熟悉的数据形态,它由明确定义的信息组成,并以高度组织化的表格或数据库进行存储和管理。正如字面上表达的,就是带有一定结构的数据。比如电话簿上有很多记录数据,每条记录包含姓名、ID、邮件、电话等,这种结构重复出现。
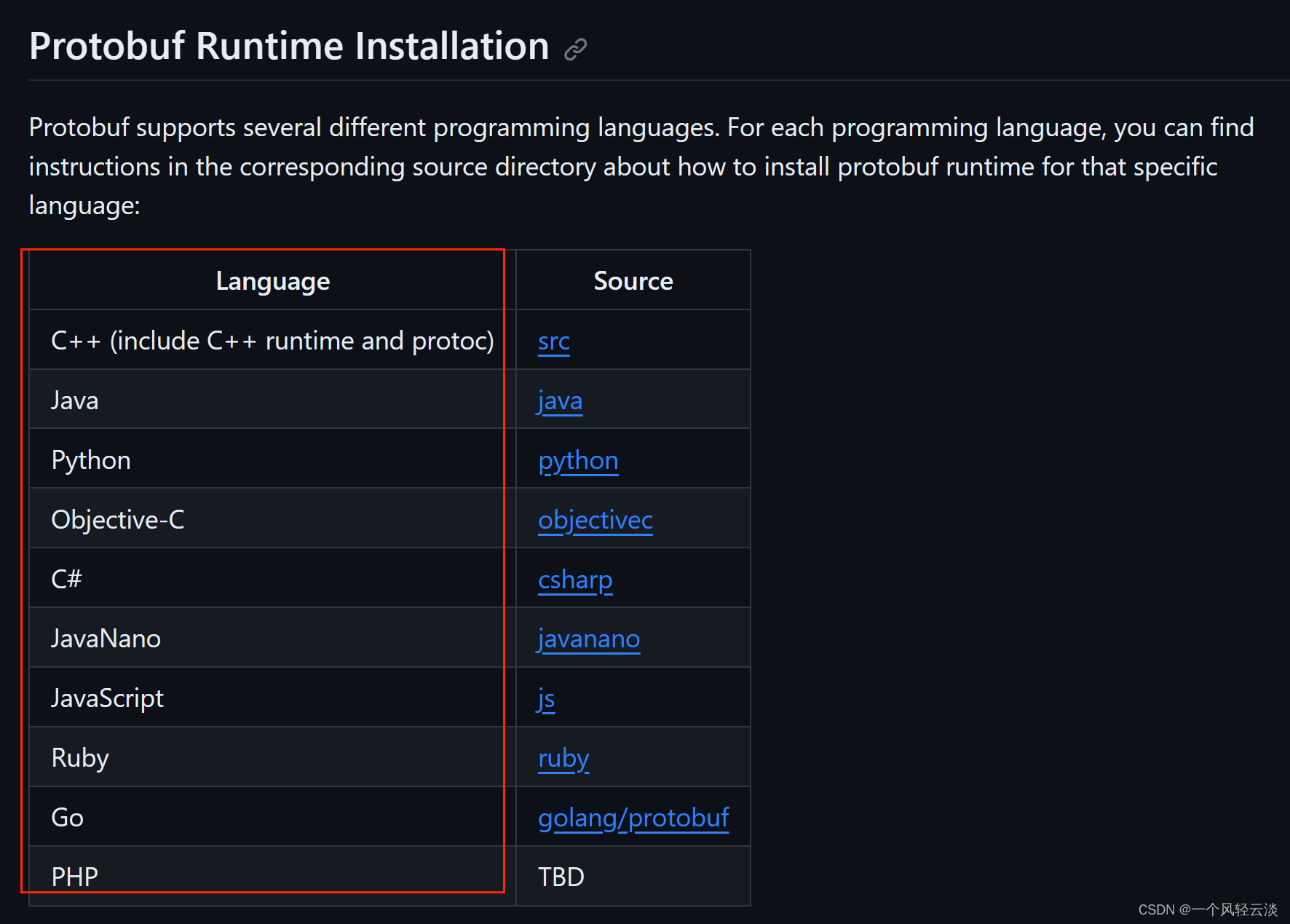
目前Protobuf官方工程主页上显示的已支持的开发语言多达10种,分别有:C++、Java、Python、Objective-C、C#、JavaNano、JavaScript、Ruby、Go、PHP,基本上主流的语言都已支持
- 2001年初,Protobuf首先在Google内部创建, 我们把它称之为
proto1,一直以来在Google的内部使用,其中也不断的演化,根据使用者的需求也添加很多新的功能,一些内部库依赖它。几乎每个Google的开发者都会使用到它。 - Google开始开源它的内部项目时,因为依赖的关系,所以他们决定首先把Protobuf开源出去。 proto1在演化的过程中有些混乱,所以Protobuf的开发者重写了Protobuf的实现,保留了proto1的大部分设计,以及proto1的很多的想法。但是开源的proto2不依赖任何的Google的库,代码也相当的清晰。2008年7月7日,Protobuf开始公布出来。
- Protobuf公布出来也得到了大家的广泛的关注, 逐步地也得到了大家的认可,很多项目也采用Protobuf进行消息的通讯,还有基于Protobuf的微服务框架GRPC。在使用的过程中,大家也提出了很多的意见和建议,Protobuf也在演化,于2016年推出了Proto3。 Proto3简化了proto2的开发,提高了开发的效能,但是也带来了版本不兼容的问题。
原理
ProtoBuf 是通过ProtoBuf编译器将与编程语言无关的特有的 .proto 后缀的数据结构文件编译成各个编程语言(Java,C/C++,Python)专用的类文件,然后通过Google提供的各个编程语言的支持库lib即可调用API。
同类对比
XML、JSON 也可以用来存储此类结构化数据,但是使用ProtoBuf表示的数据能更加高效,并且将数据压缩得更小。
| 协议 | 场景 | 举例 |
|---|---|---|
| xml | 主要在本地使用 | UI,游戏信息 |
| json | http api | HTTP网页注册账户 |
| protobuf | 服务与服务的远程调用 | rpc,游戏,即时通讯,tars brpc |
用
protobuf序列化后的大小是json的10分之一,是xml格式的20分之一,但是性能却是它们的5~100倍,我觉得用户一定会尖叫的:oh my god!。
如果有我们有一个 person 对象,用 JSON、XML 和 protobuf 表示下它们各是什么样。
用 XML 格式表示如下
<person><name>ivy</name><age>24</age>
</person>
用 JSON 格式表示如下
{"name":"ivy","age":24
}
用 protobuf 表示如下, 它直接用二进制来表示数据,不像上面 XML 和 JSON 格式那么直观
[10 6 69 108 108 105 111 116 16 24]三种格式优点:
- json优点就是较XML格式更加小巧,传输效率较xml提高了很多,可读性还不错。
- xml优点就是可读性强,解析方便。
- protobuf优点就是传输效率快,序列化后体积相比Json和XML很小,支持跨平台多语言,消息格式升级和兼容性还不错,序列化反序列化速度很快。
三种格式缺点:
- json缺点就是传输效率也不是特别高(比xml快,但比protobuf要慢很多)。
- xml缺点就是效率不高,资源消耗过大。
- protobuf缺点就是使用不太方便。
为什么要使用protobuf?
使用protobuf的原因肯定是为了解决开发中的一些问题,那使用其他的序列化机制会出现什么问题呢?
- (1)java默认序列化机制:效率极低,而且还能不能跨语言之间共享数据。
- (2)XML常用于与其他项目之间数据传输或者是共享数据,但是编码和解码会造成很大的性能损失。
- (3)json格式也是常见的一种,但是在json在解析的时候非常耗时,而且json结构非常占内存。
但是我们protobuf是一种灵活的、高效的、自动化的序列化机制,可以有效的解决上面的问题。