redis数据倾斜如何解决
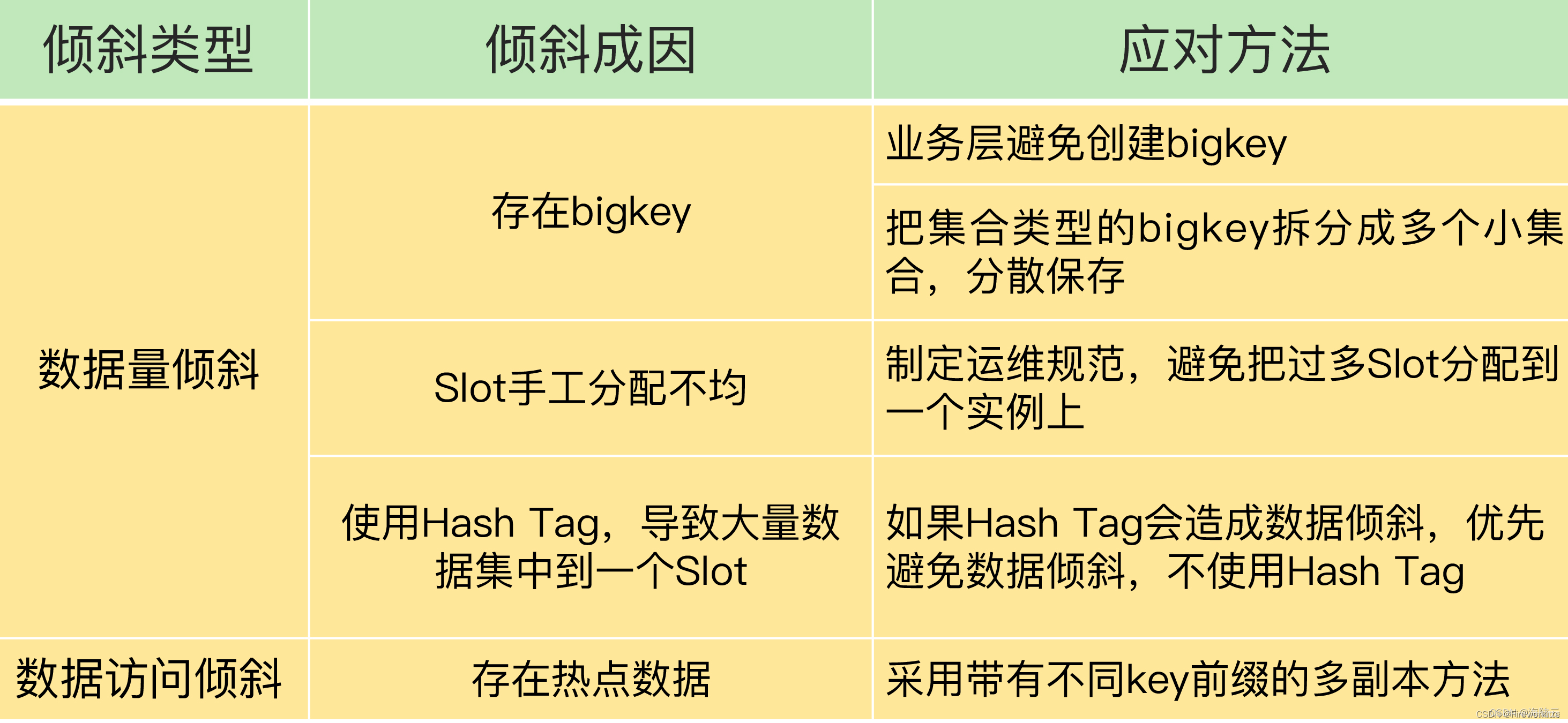
Redis数据倾斜主要是由于数据访问热点导致的,通常在执行事务操作或范围查询时发生。这会导致大量数据集中在某个实例上,使得集群负载不均衡。以下是一些解决Redis数据倾斜的方法:
- 避免在同一个键值对上保存过多的数据。可以将大的键值对拆分成小的集合类型数据,并分散存储在不同的实例上。例如,如果有一个大的哈希集合保存了100万个用户信息,可以将它拆分成10个小的哈希集合,每个集合只保存10万用户信息。
- 采用热点数据多副本方案。如果热点数据是只读的,可以在每个副本的键中增加一个随机前缀,这样可以让不同的副本数据不会映射到同一槽位中。
- 使用分布式锁。当有多个实例同时访问同一个数据时,可以使用分布式锁来确保数据的一致性,避免数据出现倾斜。
- 使用Hash Tag进行数据切片。Hash Tag可以将数据分散到不同的实例上,从而避免数据倾斜。
- 使用KEYS选项进行批量迁移。从Redis3.0.6开始,可以使用KEYS选项一次迁移多个键,从而提高迁移效率。
总之,解决Redis数据倾斜需要针对具体情况采取不同的策略,包括合理设计数据结构、避免热点数据的产生、使用分布式锁、使用Hash Tag进行数据切片以及使用KEYS选项进行批量迁移等。
Redis数据倾斜的解决方法有以下几种:
6. 使用哈希散列:将数据分到不同的哈希槽中,使得数据分布更均匀。可以通过CLUSTER ADD-HASHSLOT命令动态添加或删除哈希槽。
7. 使用集群:将数据分布在多个Redis节点上,通过节点之间的数据迁移和负载均衡来平衡数据分布。可以使用redis-cluster工具创建集群。
8. 使用分区键:为数据设置一个分区键,根据分区键的值将数据存储到不同的Redis实例上。例如,可以使用用户ID作为分区键,将不同用户的数据存储到不同的Redis实例上。
9. 使用预分区:在创建Redis实例时,预先分配好哈希槽,使得数据在一开始就能均匀分布。可以使用CLUSTER REPLICATE命令进行预分区。
10. 使用客户端分片:在客户端实现数据的分片逻辑,根据需要将数据存储到不同的Redis实例上。例如,可以使用一致性哈希算法来实现客户端分片。
参考文章 链接