Python克隆单个网页
网上所有代码都无法完全克隆单个网页,不是Css,Js下载不下来就是下载下来也不能正常显示,只能自己写了,记得点赞~
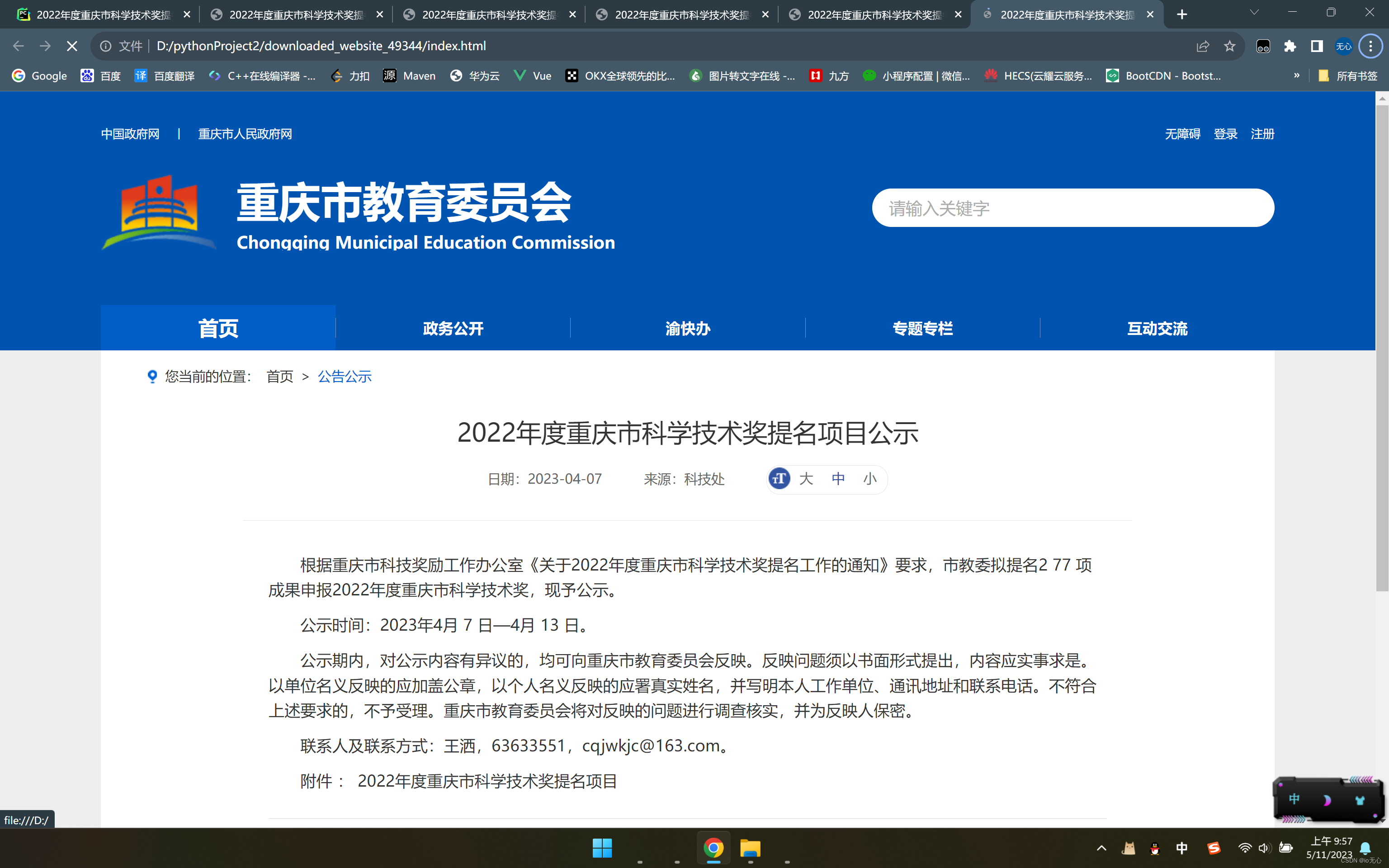
效果如图:
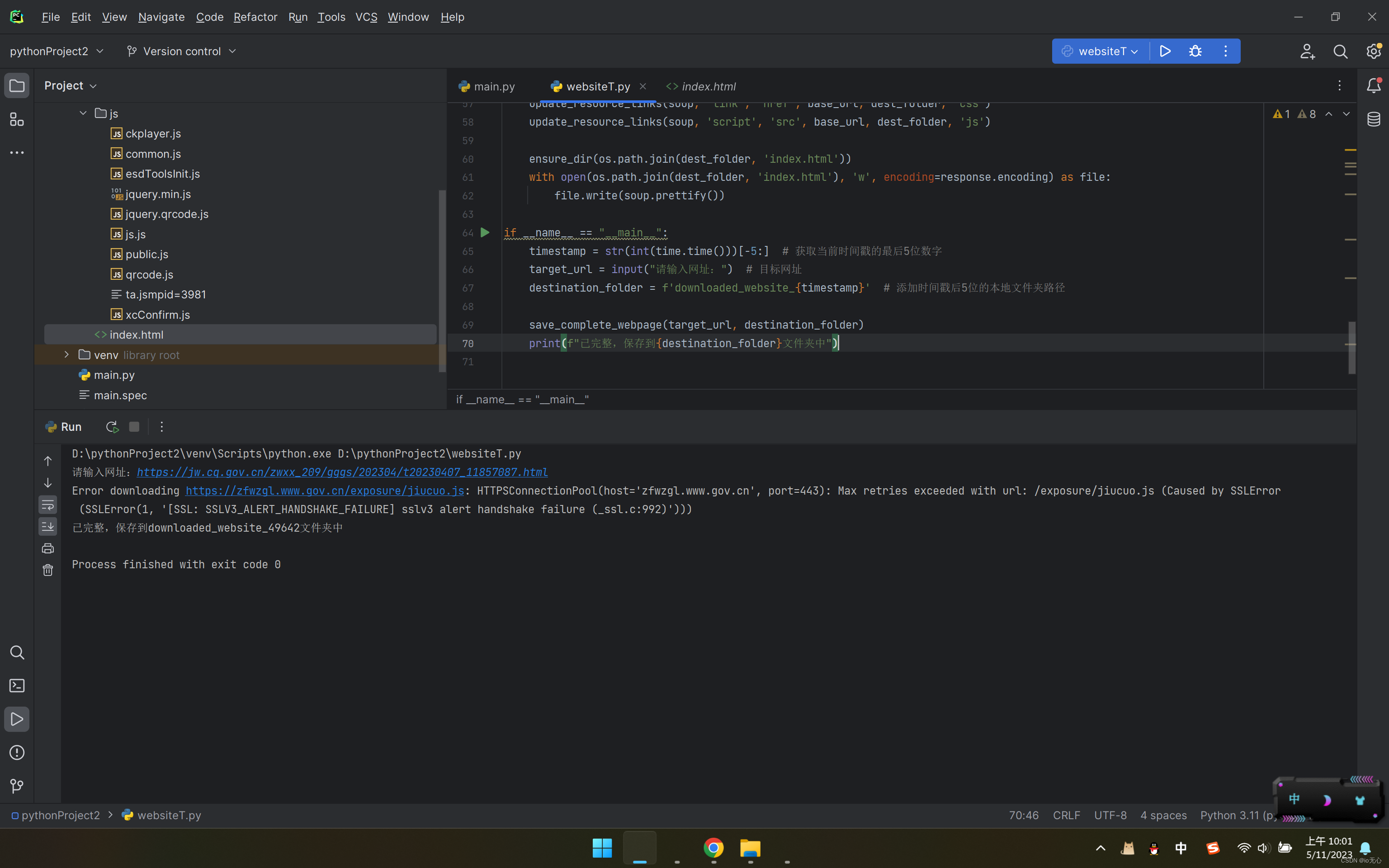
源码与所需的依赖:
pip install requests
pip install requests beautifulsoup4 lxml
requests.packages.urllib3.disable_warnings()
pip install urllib3
pip install pyOpenSSL requests[security] urllib3[secure]
import os
import time
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup# 配置requests,不验证SSL证书
requests.packages.urllib3.disable_warnings()
session = requests.Session()
session.verify = False # 不推荐,仅用于测试目的def sanitize_filename(filename):return "".join(i for i in filename if i not in "\/:*?<>|").split('?')[0]def ensure_dir(file_path):if file_path:directory = os.path.dirname(file_path)if directory and not os.path.exists(directory):os.makedirs(directory)def download_resource(url, dest_folder, local_path):try:r = session.get(url, stream=True)r.raise_for_status()ensure_dir(local_path)with open(local_path, 'wb') as f:for chunk in r.iter_content(chunk_size=8192):f.write(chunk)return Trueexcept requests.exceptions.RequestException as e:print(f"Error downloading {url}: {e}")return Falsedef update_resource_links(soup, tag, attribute, base_url, dest_folder, sub_folder):resources = soup.find_all(tag, {attribute: True})for resource in resources:old_url = resource[attribute]new_url = urljoin(base_url, old_url)local_filename = sanitize_filename(new_url.split('/')[-1])local_path = os.path.join(dest_folder, sub_folder, local_filename)full_local_path = os.path.abspath(local_path)if download_resource(new_url, dest_folder, full_local_path):resource[attribute] = os.path.join(sub_folder, local_filename).replace('\\', '/')def save_complete_webpage(url, dest_folder):response = session.get(url)response.raise_for_status()# 尝试从响应头部或内容中获取编码if response.encoding is None:response.encoding = response.apparent_encodingsoup = BeautifulSoup(response.content, 'html.parser', from_encoding=response.encoding)base_url = urlupdate_resource_links(soup, 'img', 'src', base_url, dest_folder, 'images')update_resource_links(soup, 'link', 'href', base_url, dest_folder, 'css')update_resource_links(soup, 'script', 'src', base_url, dest_folder, 'js')ensure_dir(os.path.join(dest_folder, 'index.html'))with open(os.path.join(dest_folder, 'index.html'), 'w', encoding=response.encoding) as file:file.write(soup.prettify())if __name__ == "__main__":timestamp = str(int(time.time()))[-5:] # 获取当前时间戳的最后5位数字target_url = input("请输入网址:") # 目标网址destination_folder = f'downloaded_website_{timestamp}' # 添加时间戳后5位的本地文件夹路径save_complete_webpage(target_url, destination_folder)print(f"已完整,保存到{destination_folder}文件夹中")