5 Tensorflow图像识别(下)模型构建
上一篇:4 Tensorflow图像识别模型——数据预处理-CSDN博客
1、数据集标签
上一篇介绍了图像识别的数据预处理,下面是完整的代码:
import os
import tensorflow as tf# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 模型参数设置
BATCH_SIZE = 100# 图片尺寸统一为150*150
IMG_SHAPE = 150# 处理图像尺寸
img_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255, horizontal_flip=True, )train_data_gen = img_generator.flow_from_directory(directory=train_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')
val_data_gen = img_generator.flow_from_directory(directory=validation_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')上一篇提到系统的输入是“特征-标签”对,特征是输入的图片,标签就是标记该图片是猫还是狗。上面的代码如何知道输入的照片是猫还是狗?
这里用到了keras的一个函数flow_from_directory(),从目录中生成数据流,子目录会自动帮你生成标签。先看看train训练集的这两个子目录生成的标签是什么:
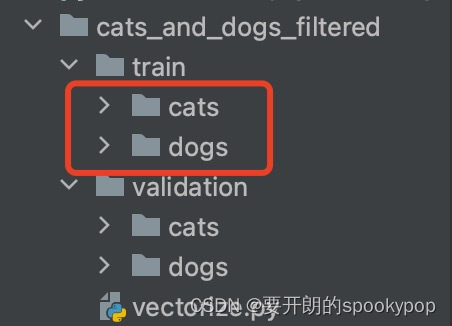
使用下面代码查看
print(train_data_gen.class_indices)运行结果:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
{'cats': 0, 'dogs': 1}
从运行结果可以看到,猫的照片系统自动打上了0的标签,狗的标签是1。
2、Relu激活函数
构建模型的完整代码如下:
import os
import tensorflow as tf
import numpy as np# 获取训练集和验证集目录
train_dir = os.path.join('cats_and_dogs_filtered/train')
validation_dir = os.path.join('cats_and_dogs_filtered/validation')# 模型参数设置
BATCH_SIZE = 100# 图片尺寸统一为150*150
IMG_SHAPE = 150# 处理图像尺寸
img_generator = tf.keras.preprocessing.image.ImageDataGenerator(rescale=1. / 255, horizontal_flip=True, )# 训练数据
train_data_gen = img_generator.flow_from_directory(directory=train_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')# 验证数据
val_data_gen = img_generator.flow_from_directory(directory=validation_dir,shuffle=True,batch_size=BATCH_SIZE,target_size=(IMG_SHAPE, IMG_SHAPE),class_mode='binary')model = tf.keras.Sequential([tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Conv2D(100, (3, 3), activation='relu'),tf.keras.layers.MaxPooling2D(2, 2),tf.keras.layers.Flatten(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(2)])model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])EPOCHS = 20
history = model.fit_generator(train_data_gen,steps_per_epoch=int(np.ceil(2000 / float(BATCH_SIZE))),epochs=EPOCHS,validation_data=val_data_gen,validation_steps=int(np.ceil(1000 / float(BATCH_SIZE)))
)model中加入了和之前不一样的代码:
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),
这里使用了卷积神经,主要是为了突出区分不同对象的特征。一张图片的信息很多的,但往往我们只需要一些特征进行训练就可以了,后续会详细介绍。
现在先介绍 activation='relu',激活函数Relu。
ReLU,全称是线性整流函数(Rectified Linear Unit),是人工神经网络中常用的激活函数。它的图像如下:

当x<=0时,f(x)=0;
当x>0时,f(x)=x;
可以运行代码看看:
例1:
import tensorflow as tfx = -19
print(tf.nn.relu(x))运行结果:
tf.Tensor(0, shape=(), dtype=int32)
输入-19,使用relu激活函数后的结果为0
例2:
import tensorflow as tfx = 8
print(tf.nn.relu(x))运行结果:
tf.Tensor(8, shape=(), dtype=int32)
3、损失函数
代码:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
其中损失函数为SparseCategoricalCrossentropy,它是用于计算多分类问题的交叉熵,如果是两个或两个以上的分类问题可以始终这样设置。对其原理及计算过程的读者可以自行百度,此处不详细介绍。
4、训练过程详解
(1)训练准确率
运行上面的完整代码:
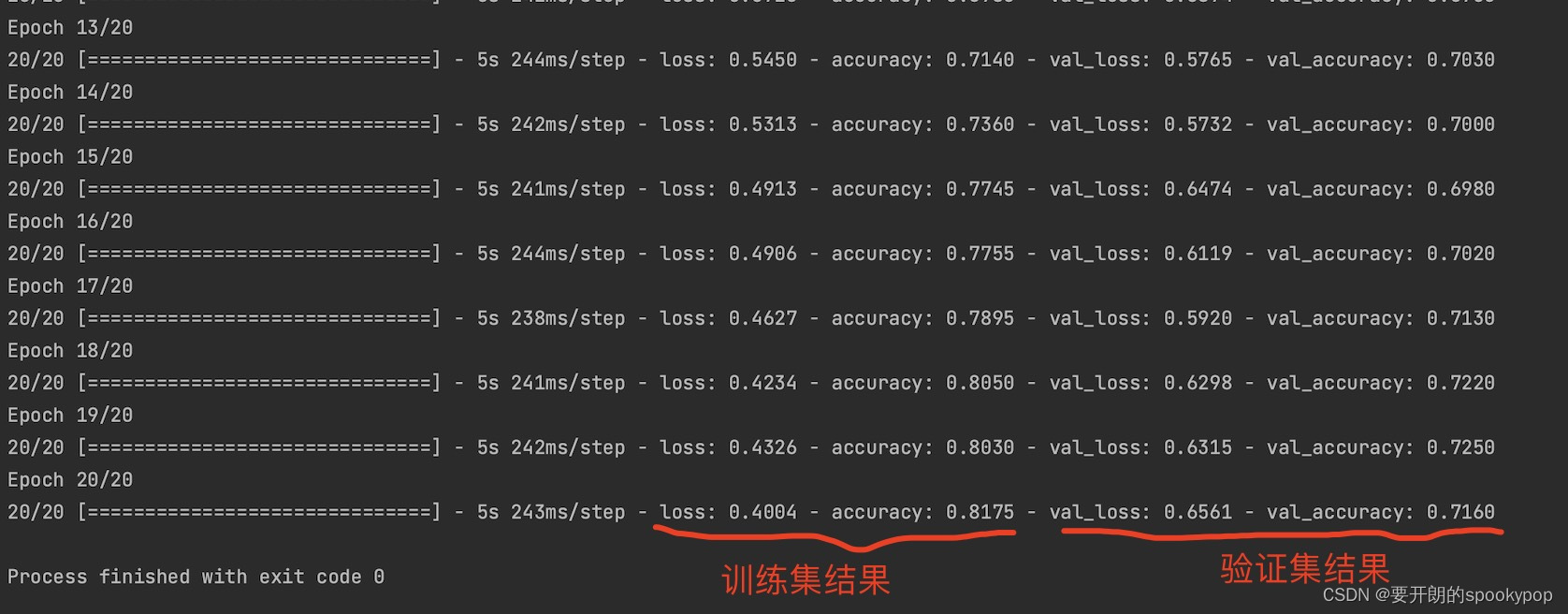
可以看到训练集和验证集的loss值在慢慢下降,准确率在提升。
划线部分是最后一个epoch的训练结果:
accuracy:0.8175,也就是说你的神经网络在分类训练数据方面的准确率约为82%;
val_accuracy:0.7160,在验证集的准确率约为72%
(2)batch_size批次大小
代码中batche_size设置的大小为100,意思是每批次生成的样本数量为100。
例如上述代码的train训练集一共有2000张图片,一个周期(epoch)分20个批次(2000/100=20)样本数据进行训练,每个批次训练完后利用优化器更新模型参数。
所以一个周期(epoch)的模型参数更新次数就是20:2000/batch_size=20
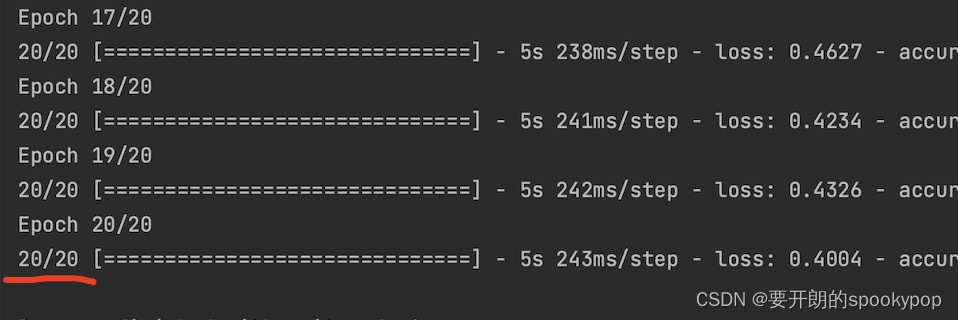
截图中红色部分,就是一个epoch分了20个批次用来更新模型参数。
训练结果会因为模型的参数的设置、训练集图片的数量等等原因结果大不相同,学习的时候可以自己动手去调整模型参数来看看训练结果。