(pytorch进阶之路)Informer
论文:Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting (AAAI’21 Best Paper)
看了一下以前的论文学习学习,我也是重应用吧,所以代码部分会比较多,理论部分就一笔带过吧
论文作者也很良心的给出了colab,就大大加快了看源码是怎么实现的速度:https://colab.research.google.com/drive/1_X7O2BkFLvqyCdZzDZvV2MB0aAvYALLC
那么源码主要看什么呢,首先是issue,github的issue里面如果压根就跑不了,那就不用花时间了,如果没太大的错误说明代码没有致命的错误
第二步是看数据,源数据是什么,数据如何预处理
第三步看模型实现,一般就在model文件夹下面,这一步比较简单,重点看创新点部分如何实现的
第四步pth,看看复现结果
文章目录
- 模型框架
- 代码地址
模型框架
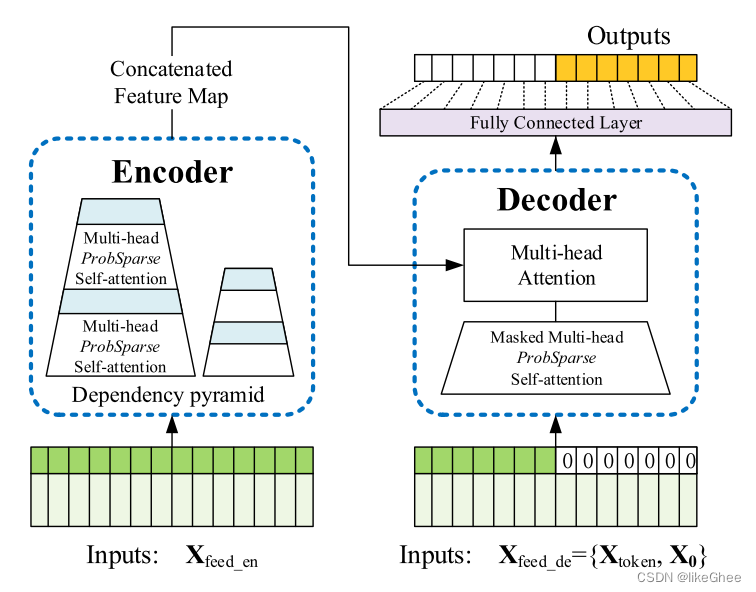
创新点:ProbSparse Attention
主要思想就是用top-k选择最有用的信息
代码地址
https://github.com/zhouhaoyi/Informer2020
下载好代码和数据,仔细阅读Data的说明,我们得知得把数据放到data/ETT文件夹下面
parser部分大致看看什么意思,model,data,root_path,data_path,单卡多卡和num_workers设置一下,结合上下文推测大致的意思,同时github里面提供了数据字典,我们至少需要修改data和data_path参数
由于我是windows上debug的,所以args如果是required=True的话参数需要我们手动填就很麻烦,个人习惯就都改成False先
右键运行成功,那么就可以逐步debug了
main_informer.py运行,逐渐运行到
exp.train(setting)
进入train函数
train_data, train_loader = self._get_data(flag='train')vali_data, vali_loader = self._get_data(flag='val')test_data, test_loader = self._get_data(flag='test')
首先_get_data取数据,进入函数看看,data_dict里面看到了Dataset_Custom,就知道它是可以自定义数据的,后面实例化dataset,实例化dataset再实例化dataloader,数据集做好了
dataset中看看怎么预处理数据的,dataset里面有__read_data__和__getitem__函数,上下文分析__read_data__就是预处理的步骤,因为看到了StandardScaler,里面做了一个标准化
time_features函数对时间维度做特征编码,思想很简单,但是代码写特别复杂
最后构造dataloader
往下走到epoch开始迭代训练数据,到_process_one_batch函数
pred, true = self._process_one_batch(train_data, batch_x, batch_y, batch_x_mark, batch_y_mark)
_process_one_batch进一步处理数据和输入进model,dec_input先全0或者全1进行初始化
然后enc_inputh后面48个和dec_input按dim=1维度进行拼接
dec_input前面的48个就是时序的观测值,我们要预测后面的24个
model输入是96,12的enc_input,enc_mark是96,4时间编码特征
dec_input是72,12,dec_mark是72,4
model 部分
主要是attention模块(其他都比较简单),在model/attn.py,看ProbAttention class,直接看forward函数
首先划分QKV,96个seqlen中选25个(U_part)
重点来了,_prob_QK函数
scores_top, index = self._prob_QK(queries, keys, sample_k=U_part, n_top=u)
进入_prob_QK
首先K扩充了-3的维度,K_expand=(32,8,96,96,64)
index_sample随机采样出0~96的96×25的矩阵,K_sample取出(32,8,96,25,64)
Q和K_sample计算内积的到Q_K_sample(32,8,96,25)
Q_K_sample上计算max,选出M_top个max波峰最大的Q,得到Q_reduce(25个Q)
Q_reduce再和96个K做内积
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)# Q [B, H, L, D]B, H, L_K, E = K.shape_, _, L_Q, _ = Q.shape# calculate the sampled Q_KK_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_qK_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)# find the Top_k query with sparisty measurementM = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K)M_top = M.topk(n_top, sorted=False)[1]# use the reduced Q to calculate Q_KQ_reduce = Q[torch.arange(B)[:, None, None],torch.arange(H)[None, :, None],M_top, :] # factor*ln(L_q)Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_kreturn Q_K, M_top
_get_initial_context函数显示了如果没有选择到的Q,说明比较平庸,直接用平均V来表示
V_sum = V.mean(dim=-2)
_update_context
只更新25个Q
context_in[torch.arange(B)[:, None, None],torch.arange(H)[None, :, None],index, :]\= torch.matmul(attn, V).type_as(context_in)
attention做完
回到forward,做了一个蒸馏操作,MaxPool1d,stride=2,做个下采样
96len变成48len
ConvLayer((downConv): Conv1d(512, 512, kernel_size=(3,), stride=(1,), padding=(1,), padding_mode=circular)(norm): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(activation): ELU(alpha=1.0)(maxPool): MaxPool1d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
encoder做完
做decoder,用的模块和encoder一致,还有一个cross attention,都老生常谈,跳过…