基于词云图的短信热词数据可视化
热词统计:短信、邮件、微信、QQ、微博、电商评价、新闻、各行业热词(旅游、世界杯、战争、考研等)、热点事件等场景。
展示模型:给定多段文本,绘制出词云图。
核心思想:根据样本集中的文本包含的高频词汇作为输入(比如筛选出最高频的30个词),按频率的高低进行逐级突出显示。(可行性分析)
利用运营商的5000+条短信数据样本,提取样本短信文本中所对应的关键特征(高频词汇),频率由高到低,位置从中心到边缘,字体从大到小,笔画从粗到细,结合颜色修饰,达到突出重点的效果。
载入数据文件
查看字段定义
sms_raw<-read.csv("sms_spam.csv",stringsAsFactors = FALSE)
str(sms_raw)统计样本类别比例
table(sms_raw$type)
取垃圾短信子集
sms_raw_spam<-subset(sms_raw,type=="spam")取正常短信子集
sms_raw_ham<-subset(sms_raw,type=="ham")安装文本挖掘支持包、加载文本挖掘支持包
install.packages("tm")
library(tm)创建语料库
sms_corpus<-Corpus(VectorSource(sms_raw$text))
sms_corpus_spam<-Corpus(VectorSource(sms_raw_spam$text))
sms_corpus_ham<-Corpus(VectorSource(sms_raw_ham$text))查看语料库情况
print(sms_corpus)
print(sms_corpus_spam)
print(sms_corpus_ham)
查看语料库内容
inspect(sms_corpus[1:3])
inspect(sms_corpus_spam[1:3])
inspect(sms_corpus_ham[1:3])
数据清理(转小写)
corpus_clean <- tm_map(sms_corpus,tolower)
corpus_clean_spam <- tm_map(sms_corpus_spam,tolower)
corpus_clean_ham <- tm_map(sms_corpus_ham,tolower)数据清理(去掉停用词)
corpus_clean <- tm_map(corpus_clean,removeWords,stopwords())
corpus_clean_spam <- tm_map(corpus_clean_spam,removeWords,stopwords())
corpus_clean_ham <- tm_map(corpus_clean_ham,removeWords,stopwords())
数据清理(去掉标点符号)
corpus_clean <- tm_map(corpus_clean,removePunctuation)
corpus_clean_spam <- tm_map(corpus_clean_spam,removePunctuation)
corpus_clean_ham <- tm_map(corpus_clean_ham,removePunctuation)
安装词云支持包
install.packages("wordcloud")加载词云支持包
library(wordcloud)
生成总体词云图
wordcloud(corpus_clean,min.freq = 40,random.order = FALSE) 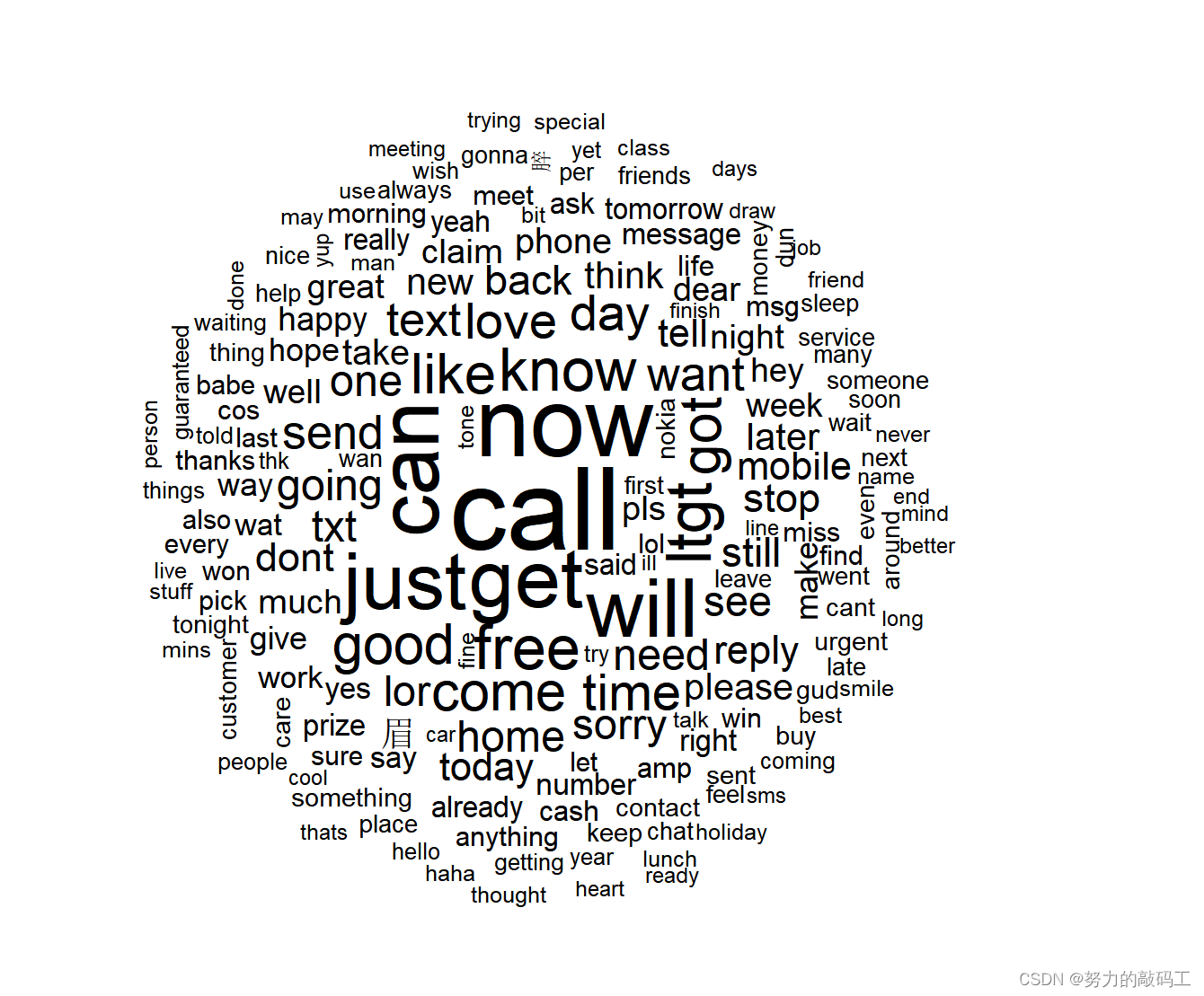
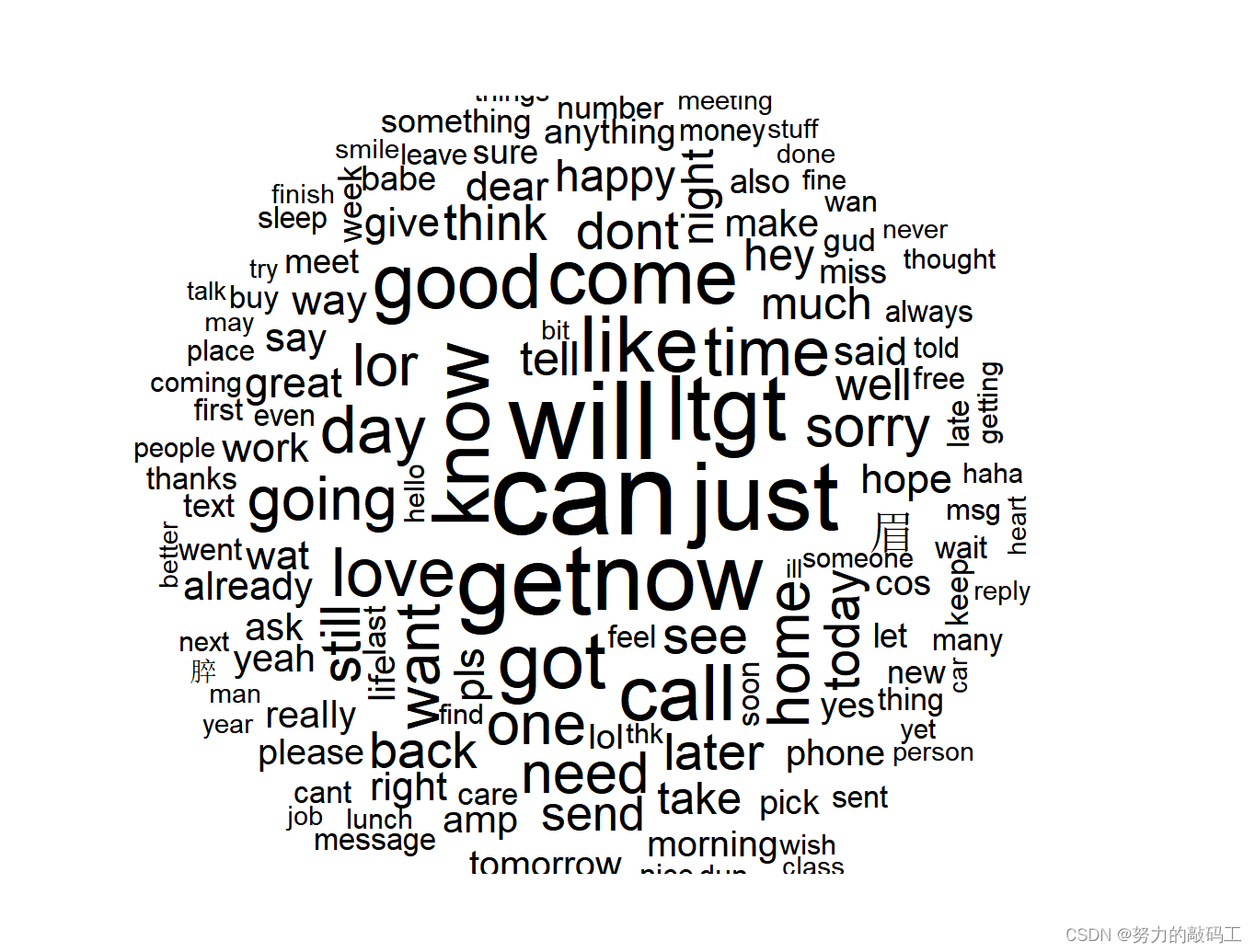
生成正常短信词云图
wordcloud(corpus_clean_ham,min.freq = 40,random.order = FALSE)
生成垃圾短信词云图
wordcloud(corpus_clean_spam,min.freq = 40,random.order = FALSE) 
综上,完成了热点词汇的可视化。