8.spark自适应查询-AQE之自适应调整Shuffle分区数量
目录
- 概述
- 主要功能
- 自适应调整Shuffle分区数量
- 原理
- 默认环境配置
- 修改配置
- 结束
概述
自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。从Spark 3.0开始,AQE有三个主要功如下
- 自适应查询AQE(Adaptive Query Execution)
- 自适应调整Shuffle分区数量
- 原理
- 默认环境配置
- 修改配置
- 动态调整Join策略
- 动态优化倾斜的 Join
- 自适应调整Shuffle分区数量
主要功能
自适应调整Shuffle分区数量
当spark.sql.adaptive.enabled和spark.sql.adaptive.coalescePartitions.enabled配置均为true时,自适应调整Shuffle分区数量功能就启动了
| 属性名称 | 默认值 | 功能 | 版本 |
|---|---|---|---|
| spark.sql.adaptive.enabled | true | 必备条件之一 | 3.0.0 |
| spark.sql.adaptive.coalescePartitions.enabled | true | 必备条件之二 | 3.0.0 |
| spark.sql.adaptive.advisoryPartitionSizeInBytes | 64 MB | 自适应优化期间shuffle分区的建议大小(以字节为单位)。当Spark合并小的shuffle分区或拆分倾斜的shuffler分区时,它就会生效。 | 3.0.0 |
| spark.sql.adaptive.coalescePartitions.parallelismFirst | true | 当为true时,Spark在合并连续的shuffle分区时会忽略Spark.sql.adaptive.advisoryPartitionSizeInBytes(默认64MB)指定的目标大小,并且只遵循Spark.sql.adaptive.salecePartitions.minPartitionSize(默认1MB)指定的最小分区大小,以最大限度地提高并行性。这是为了在启用自适应查询执行时避免性能回归。建议将此配置设置为false,并遵守spark.sql.adaptive.advisoryPartitionSizeInBytes指定的目标大小。 | 3.2.0 |
原理
Spark在处理海量数据的时候,其中的Shuffle过程是比较消耗资源的,也比较影响性能,因为它需要在网络中传输数据。
shuffle 中的一个关键属性是:分区的数量。
分区的最佳数量取决于数据自身大小,但是数据大小可能在不同的阶段、不同的查询之间有很大的差异,这使得这个数字很难精准调优。
如果分区数量太多,每个分区的数据就很小,读取小的数据块会导致IO效率降低,并且也会产生过多的task, 这样会给Spark任务带来更多负担。
如果分区数量太少,那么每个分区处理的数据可能非常大,处理这些大分区的数据可能需要将数据溢写到磁盘(例如:排序或聚合操作),这样也会降低计算效率。
Spark初始会设置一个较大的Shuffle分区个数,这个数值默认是200,后续在运行时会根据动态统计到的数据信息,将小的分区合并,也就是慢慢减少分区数量。
测试时将以SELECT workorder,unitid,partid,partname,routeid,lineid from ods.xx where dt ='2023-06-24' group by workorder,unitid,partid ,partname ,routeid,lineid 语句进行测试,为了看出 Shuffle 的效果,group 字段多了一些
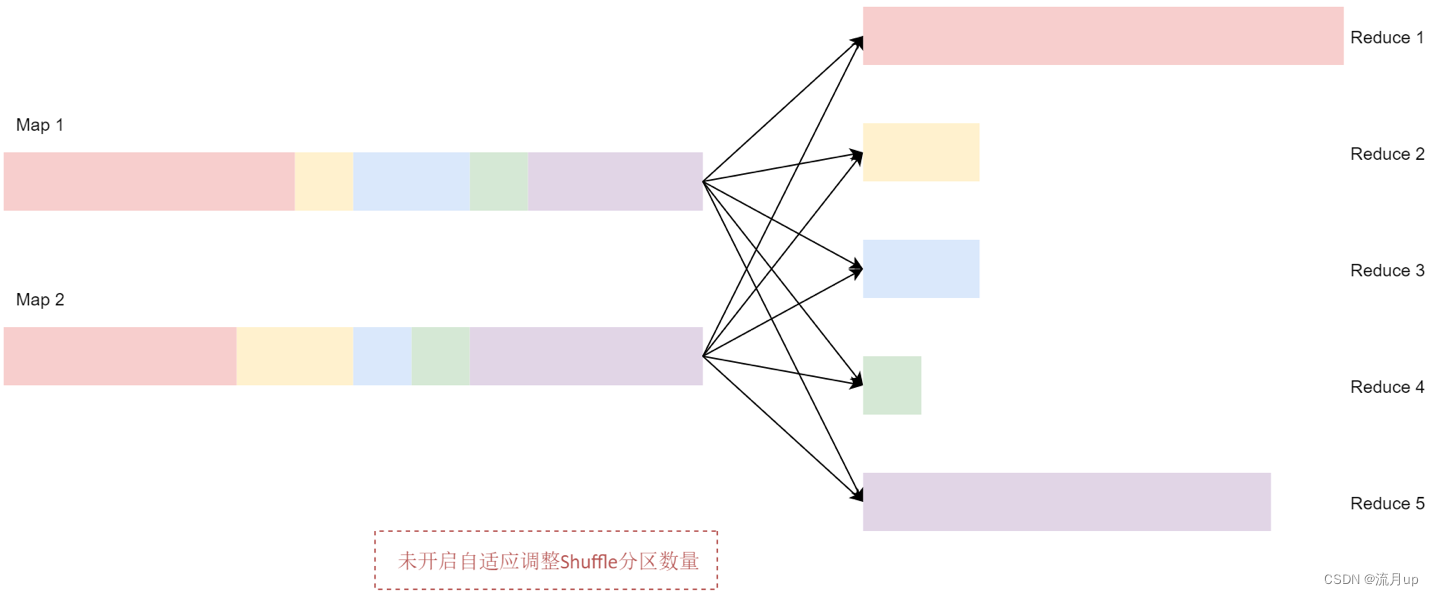
将初始的 Shuffle 分区数量设置为 5,所以在 Shuffle 过程中数据会产生5 个分区。如果没有开启自适应调整Shuffle分区数量这个策略,Spark会启动5个Recuce任务来完成最后的聚合。但是这里面有3个非常小的分区,为每个分区分别启动一个单独的任务会浪费资源,并且也无法提高执行效率。如下图:
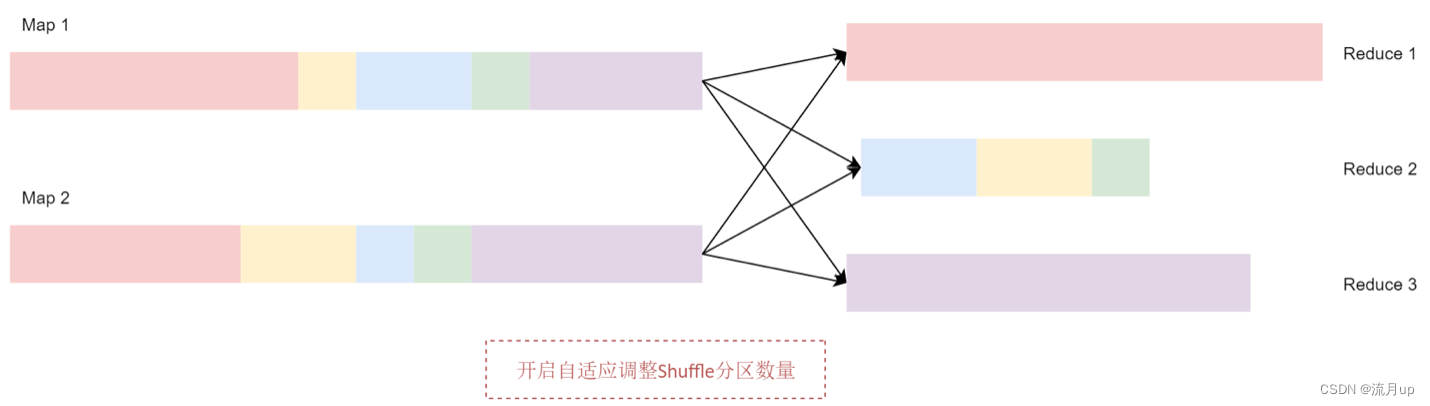
开启自适应调整 Shuffle 分区数量之后,Spark 会将这3个数据量比较小的分区合并为 1 个分区,让1个reduce任务处理
默认环境配置
测试案例:
案例环境,使用的是
spark 3.2.4,kyuubi 1.7.1版本,使用一张20亿的表做优化测试的,也可以准备一个json文件,加载后转成DataFrame
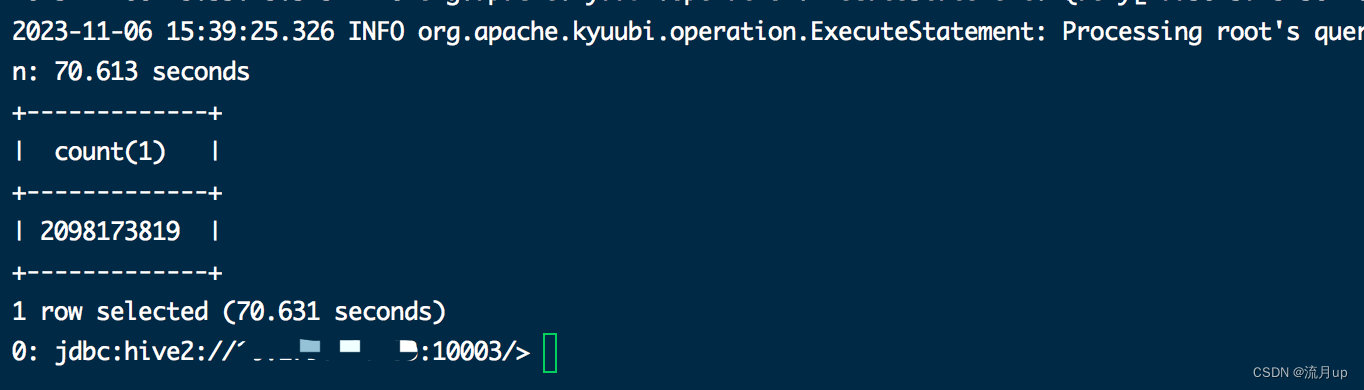
SELECT workorder,unitid,partid,partname,routeid,lineid from ods.xx where dt ='2023-06-24' group by workorder,unitid,partid ,partname ,routeid,lineid
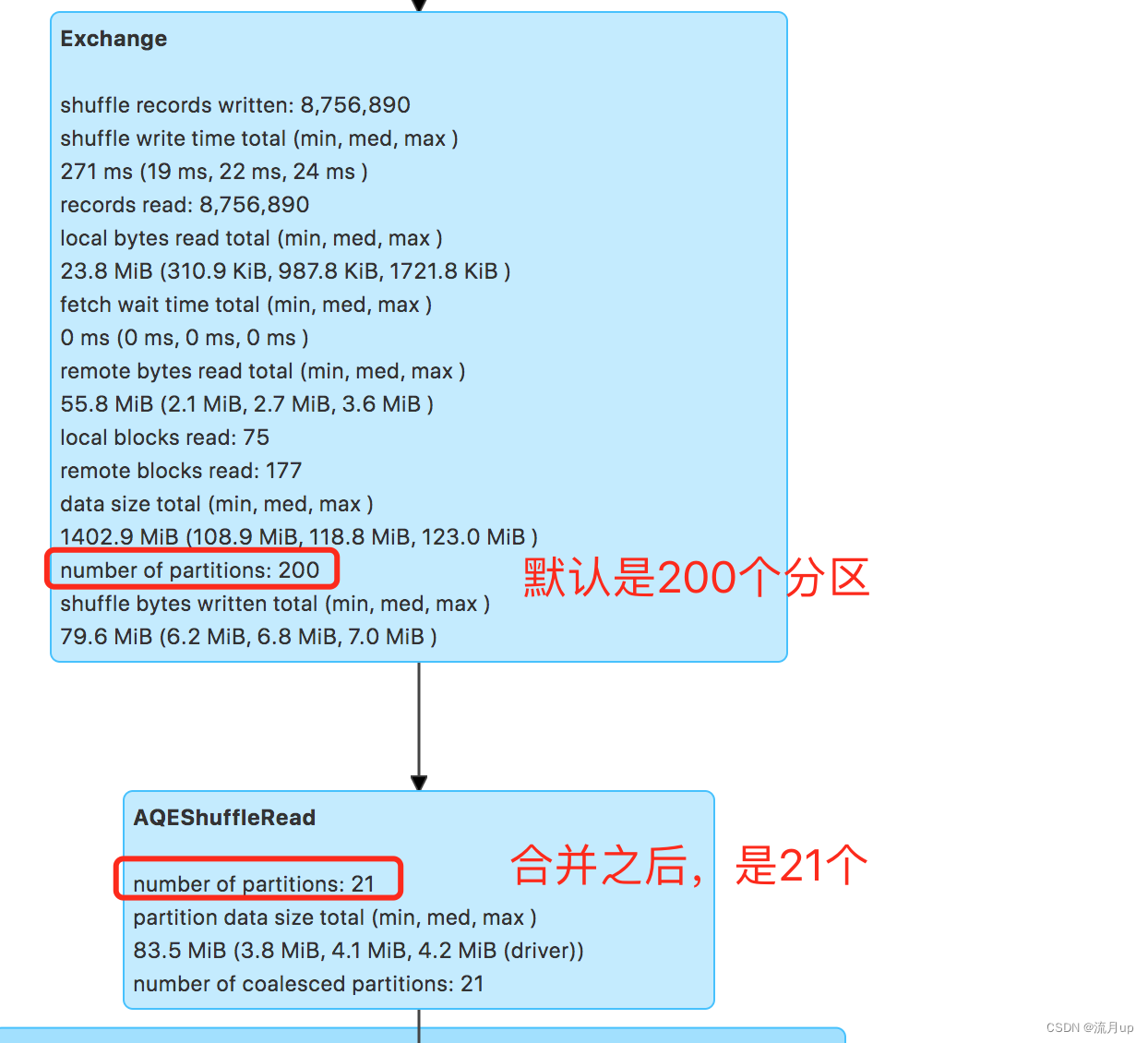

由上两个图,可以看出21任务,每个任务只是 3~4 M 这样,原因是因
spark.sql.adaptive.coalescePartitions.parallelismFirst = true
修改配置
spark.sql.adaptive.coalescePartitions.parallelismFirst=false


可以看出,两三千万的数据,shuffle 处理上还是有倾斜的,但海量数据下,基本上是接近64m的。
结束
至此,自适应调整Shuffle分区数量,就结束了。