总结Kibana DevTools如何操作elasticsearch的常用语句
一、操作es的工具
- ElasticSearch Head
- Kibana DevTools
- ElasticHQ
本文主要是总结Kibana DevTools操作es的语句。
二、搜索文档
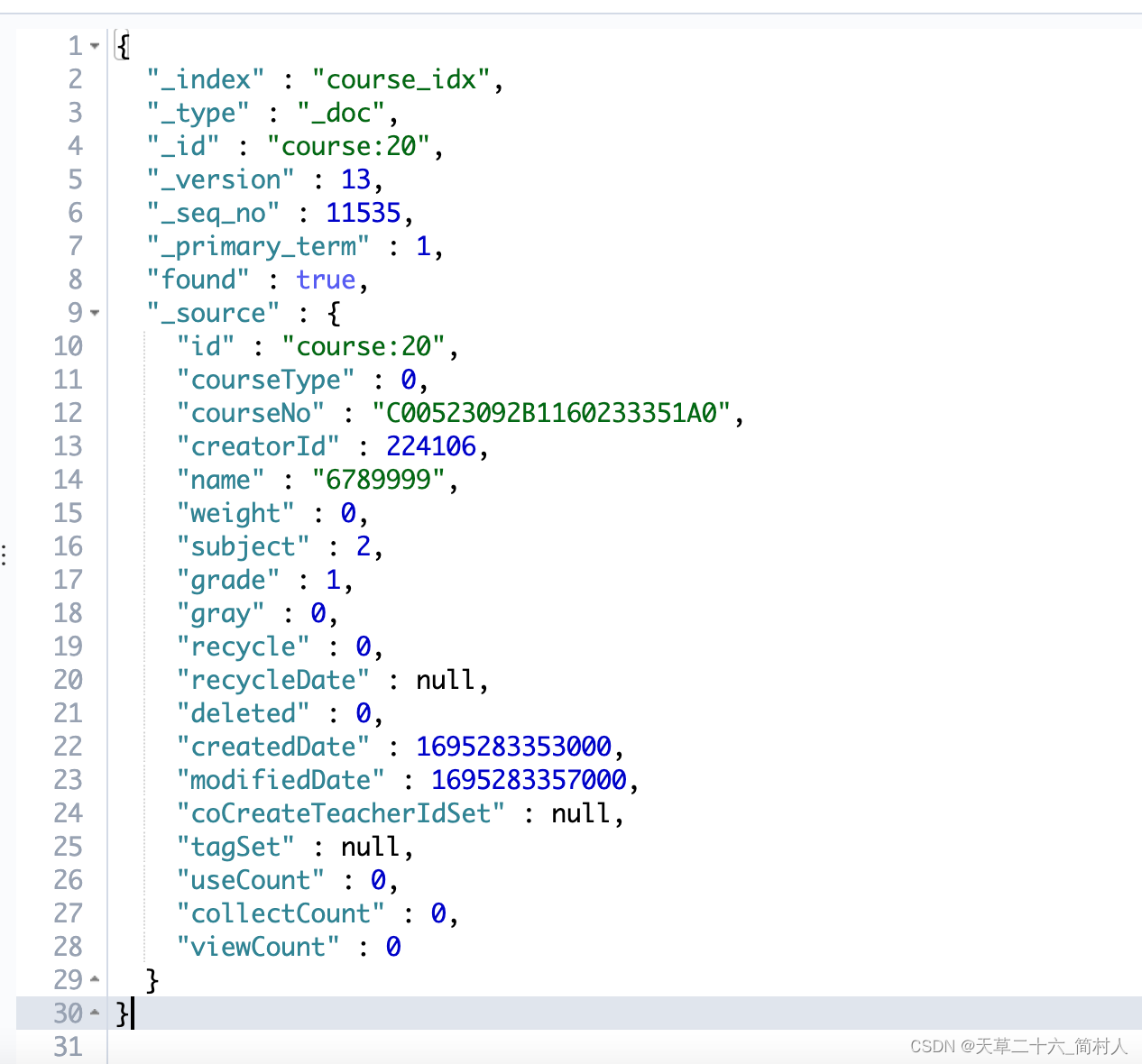
1、根据ID查询单个记录
GET /course_idx/_doc/course:20
2、term
匹配"name"字段的值为"6789999"的文档
- 类似于sql语句中的等于==,属于精准匹配
GET /course_idx/_search
{"query":{"term": {"name": "6789999"}}
}
3、terms
匹配课程编号包含"C00B5230920105650700A1"、"C00B5230921171813401A8"中任意一个值的文档。
- 类似于in集合查询
GET course_idx/_doc/_search
{"query" : {"terms" : {"courseNo" : ["C00B5230920105650700A1","C00B5230921171813401A8"],"boost" : 1.0}}
}- 返回内容
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 2,"max_score" : 1.0,"hits" : [{"_index" : "course_idx","_type" : "_doc","_id" : "course:23","_score" : 1.0,"_source" : {"id" : "course:23","courseType" : 0,"courseNo" : "C00B5230921171813401A8",// 省略其他字段}},{"_index" : "course_idx","_type" : "_doc","_id" : "course:7","_score" : 1.0,"_source" : {"id" : "course:7","courseType" : 0,"courseNo" : "C00B5230920105650700A1",// 省略其他字段}}]}
}4、match
用于在文本字段中执行全文搜索,可以模糊匹配文本。它会分析文本,将其分成词汇,并搜索匹配的词汇。
GET /course_idx/_search
{"query": {"match": {"name": "课"}}
}
5、multi_match
用于在多个字段上执行全文搜索。你可以指定多个字段,并搜索它们中的匹配项。
- 字段name或者courseNo检索匹配"课"字的记录
GET /course_idx/_search
{"query": {"multi_match": {"query": "课","fields": ["name", "courseNo"]}}
}
6、bool
- must(必须匹配)
查询courseNo=‘C005230922B133545556M4’ and useCount=0的记录
- 相当于sql中的and
GET /course_idx/_search
{"query": {"bool": {"must": [{ "term": { "courseNo": "C005230922B133545556M4" } },{ "term": { "useCount": "0" } }]}}
}
- should(可以匹配,比must的强制性小得多)
查询courseNo=‘C005230922B133545556M4’ or useCount=5的记录
- 相当于sql中的or
GET /course_idx/_search
{"query": {"bool": {"should": [{ "term": { "courseNo": "C005230922B133545556M4" } },{ "term": { "useCount": "5" } }]}}
}
- 查询结果,匹配到了3条记录,第一条记录满足第一个条件,第二三条记录满足第二个条件。
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 3,"max_score" : 5.0834727,"hits" : [{"_index" : "course_idx","_type" : "_doc","_id" : "course:35","_score" : 5.0834727,"_source" : {"id" : "course:35","courseType" : 0,"courseNo" : "C005230922B133545556M4","useCount" : 0}},{"_index" : "course_idx","_type" : "_doc","_id" : "lecture:942","_score" : 1.0,"_source" : {"id" : "lecture:942","courseType" : 2,"courseNo" : "L005231012B1421252702M5","useCount" : 5}},{"_index" : "course_idx","_type" : "_doc","_id" : "lecture:943","_score" : 1.0,"_source" : {"id" : "lecture:943","courseType" : 2,"courseNo" : "L005231012142125B2703M4","useCount" : 5}}]}
}- must_not(不匹配)
对must的取反操作,它是一个逻辑非运算。
- 类似于sql 中的 !=
GET /course_idx/_search
{"query": {"bool": {"must_not": [{ "term": { "courseNo": "C005230922B133545556M4" } }]}}
}
7、wildcard
允许使用通配符进行模糊匹配。
-
星号* :星号用于匹配零个或多个字符。例如,app* 将匹配任何以"app"开头的词汇,例如"apple"、"application"等。
-
问号?:问号用于匹配一个单一字符。例如,te?t 将匹配"test"、“text"等,但不会匹配"tent”,因为它包含了两个不同的字符。
GET /course_idx/_search
{"query": {"wildcard": {"name.keyword": "22*"}}
}
- 返回报文
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0},"hits" : {"total" : 31,"max_score" : 1.0,"hits" : [{"_index" : "course_idx","_type" : "_doc","_id" : "lecture:184","_score" : 1.0,"_source" : {"id" : "lecture:184","courseType" : 2,"courseNo" : "L005B2310111036451771M7","creatorId" : 155954,"name" : "22"}},{"_index" : "course_idx","_type" : "_doc","_id" : "lecture:211","_score" : 1.0,"_source" : {"id" : "lecture:211","courseType" : 2,"courseNo" : "L005B2310111052501806M4","creatorId" : 155954,"name" : "222"}},{"_index" : "course_idx","_type" : "_doc","_id" : "lecture:557","_score" : 1.0,"_source" : {"id" : "lecture:557","courseType" : 2,"courseNo" : "L0B052310111423472182M8","creatorId" : 155954,"name" : "22222"}}]}
}8、prefix
用于匹配字段的前缀
- 类似于sql中的 like ‘22%’
GET /course_idx/_search
{"query": {"prefix": {"name": "22"}}
}
9、fuzzy
模糊查询name名称字段中包含"课"字的记录。
- 依赖于分词器
GET /course_idx/_search
{"query": {"fuzzy": {"name": "课"}}
}
- fuzzy查询还允许你配置其他选项,如模糊度、前缀长度和最大扩展数,以控制查询的模糊度和性能。
三、更新文档
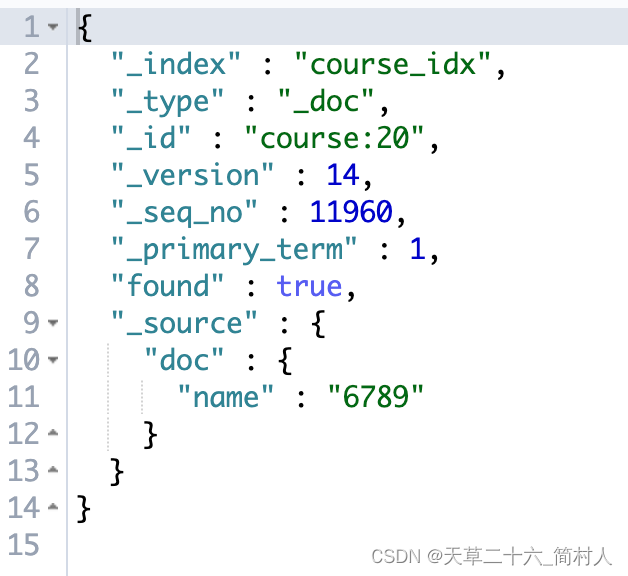
POST /course_idx/_doc/course:20
{"doc": {"name": "6789"}
}// 修改成功!!
{"_index" : "course_idx","_type" : "_doc","_id" : "course:20","_version" : 14,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 11960,"_primary_term" : 1
}
- 再次查询,发现文档的name内容是更新了,但是文档的字段也只剩下name了。
所以,在使用本操作语句的时候,需要特别注意这一点。
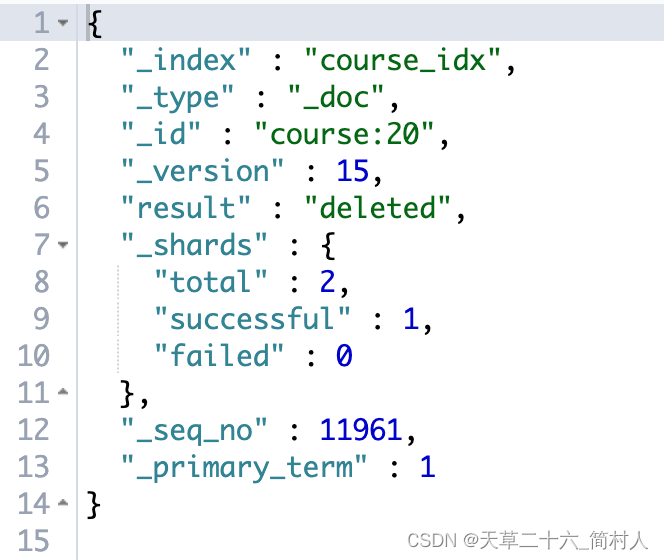
四、删除文档
DELETE /course_idx/_doc/course:20
五、索引
1、创建索引
这里只列举出几个字段,并不是全部字段的定义。
PUT /course_idx
{"mappings":{"_doc":{"properties":{"courseType":{"type":"integer"},"creatorId":{"type":"long"},"courseNo":{"type":"keyword"},"name":{"type":"text","fields":{"keyword":{"ignore_above":256,"type":"keyword"}}},"id":{"type":"keyword"}}}}
}
2、删除索引
谨慎操作,这个会删除掉所有数据及结构。
DELETE /course_idx
六、聚合查询
1、计数
GET /course_idx/_count// 总记录数是1153条
{"count" : 1153,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0}
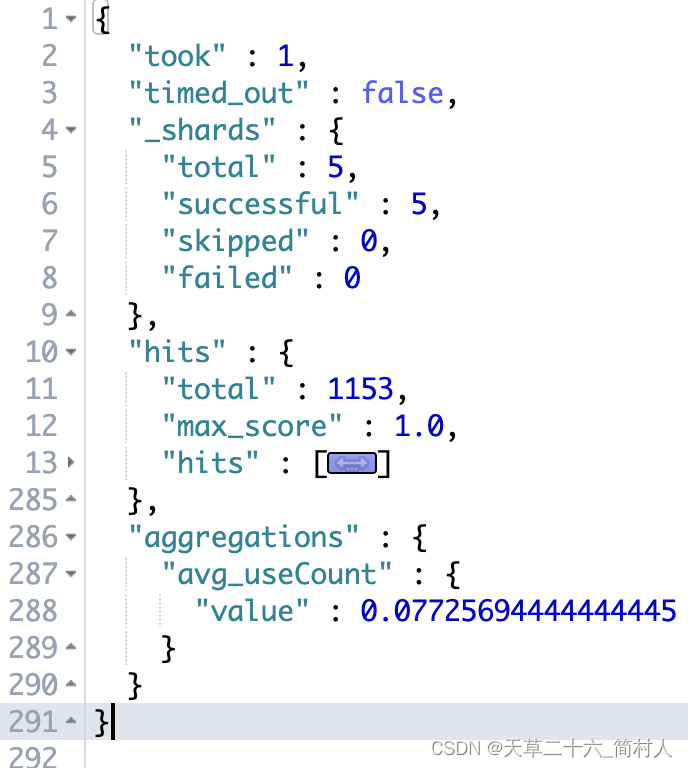
}2、平均值
统计字段useCount-使用次数的平均数
GET /course_idx/_search
{"aggs": {"avg_useCount": {"avg": {"field": "useCount"}}}
}
3、汇总
使用次数的汇总
GET /course_idx/_search
{"aggs": {"total_useCount": {"sum": {"field": "useCount"}}}
}
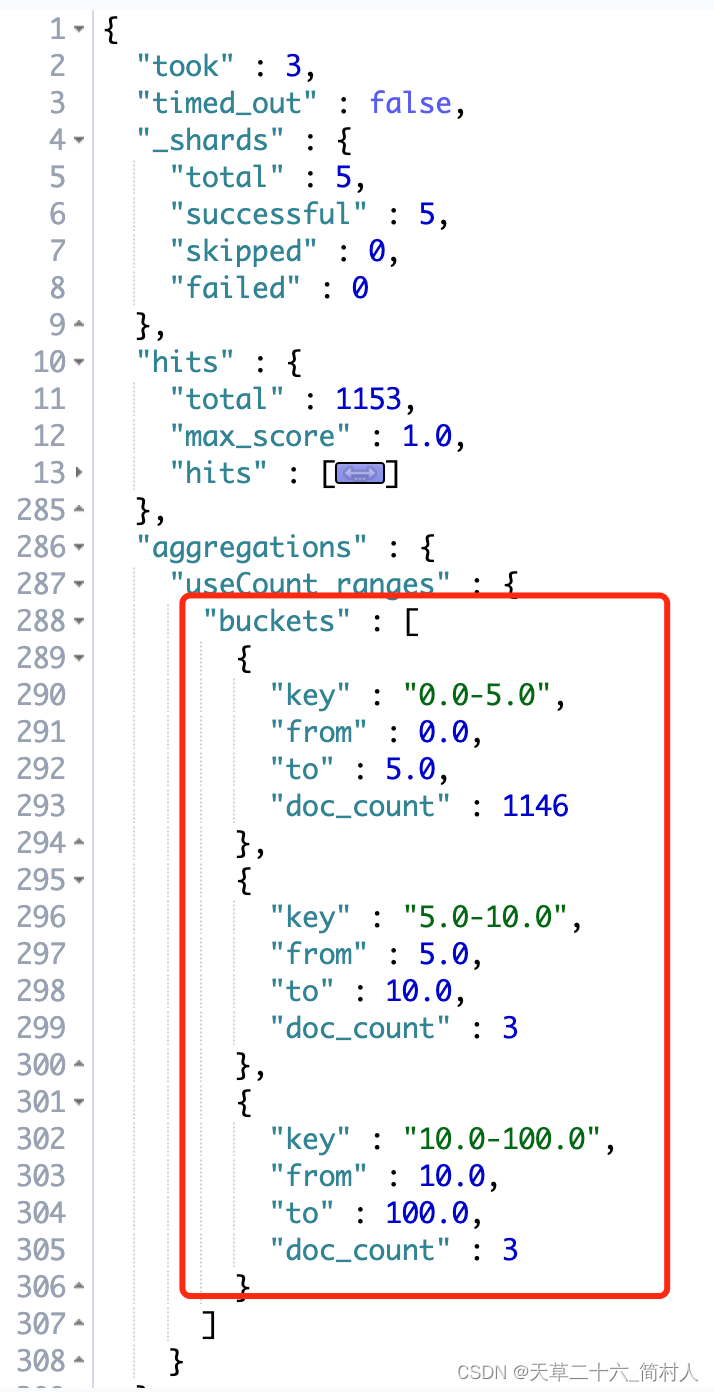
4、bucket桶查询
使用次数的桶统计
GET /course_idx/_search
{"aggs": {"useCount_ranges": {"range": {"field": "useCount","ranges": [{ "from": 0, "to": 5 },{ "from": 5, "to": 10 },{ "from": 10, "to": 100 }]}}}
}
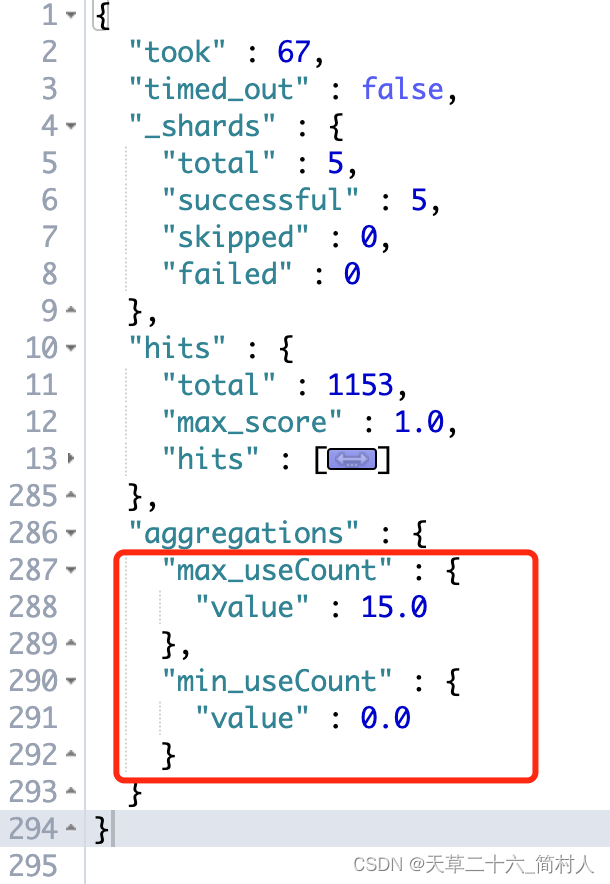
5、最大/小值
求最大使用次数和最小使用次数。
GET /course_idx/_search
{"aggs": {"max_useCount": {"max": {"field": "useCount"}},"min_useCount": {"min": {"field": "useCount"}}}
}
6、日期直方图
按天的直方图,统计每天的文档数量
GET /course_idx/_search
{"aggs": {"date_histogram": {"date_histogram": {"field": "createdDate","interval": "day"}}}
}

七、分词器
es默认的分词器是standard。
下面以“数学的课程库”三个字为示例,看下分词结果。
GET /_analyze
{"analyzer": "standard","text": "数学的课程库"
}GET /_analyze
{"text": "数学的课程库"
}
结果都是“数”“学”“的”“课”“程”“库”。
想要更好的支持中文分词,一般的建议是按照ik分词器。
如果想要进一步自定义分词,需要编写你自己的dict文本。
- 建议在安装es的时候,就把需用的分词器安装OK
- 第二步在建立es索引的时候,指定具体字段使用什么分词器(否则它将使用对中文不是很友好的标准分词器)