【人脸识别】FROM:提升遮挡状态下的人脸识别效果
论文题目:《End2End Occluded Face Recognition by Masking Corrupted Features》
论文地址:https://arxiv.org/pdf/2108.09468v3.pdf
代码地址:https://github.com/haibo-qiu/from
1.前言
人脸识别技术已经取得了显著的进展,主要归功于以下三个因素:
- loss functions: Center loss、CosFace、ArcFace etc. (损失函数)
- carefully designed convolutional neural network architectures (CNNs): ResNet etc.(网络设计)
- large-scale training datasets: LFW、WebFace etc.(数据集)
人脸识别技术在真实场景中面临的主要挑战:
- extreme illumination (极端的光线)
- rare head pose (罕见的头部姿态)
- lowresolutions, and occlusions (低分辨率以及遮挡)
目前为了缓解因遮挡造成的效果下降主要采用两种方式:Recovering and Removing。
- Recovering means recovering the occluded facial parts first, and then performing recognition on the recovered face images.
(恢复是指先恢复被遮挡的面部部位,然后对恢复后的人脸图像进行识别)- Removing represents first removing the features that are corrupted by occlusions, and then utilizing the remaining clean
features for recognition.(删除表示首先删除被遮挡损坏的特征,然后利用剩余的干净特征进行识别)
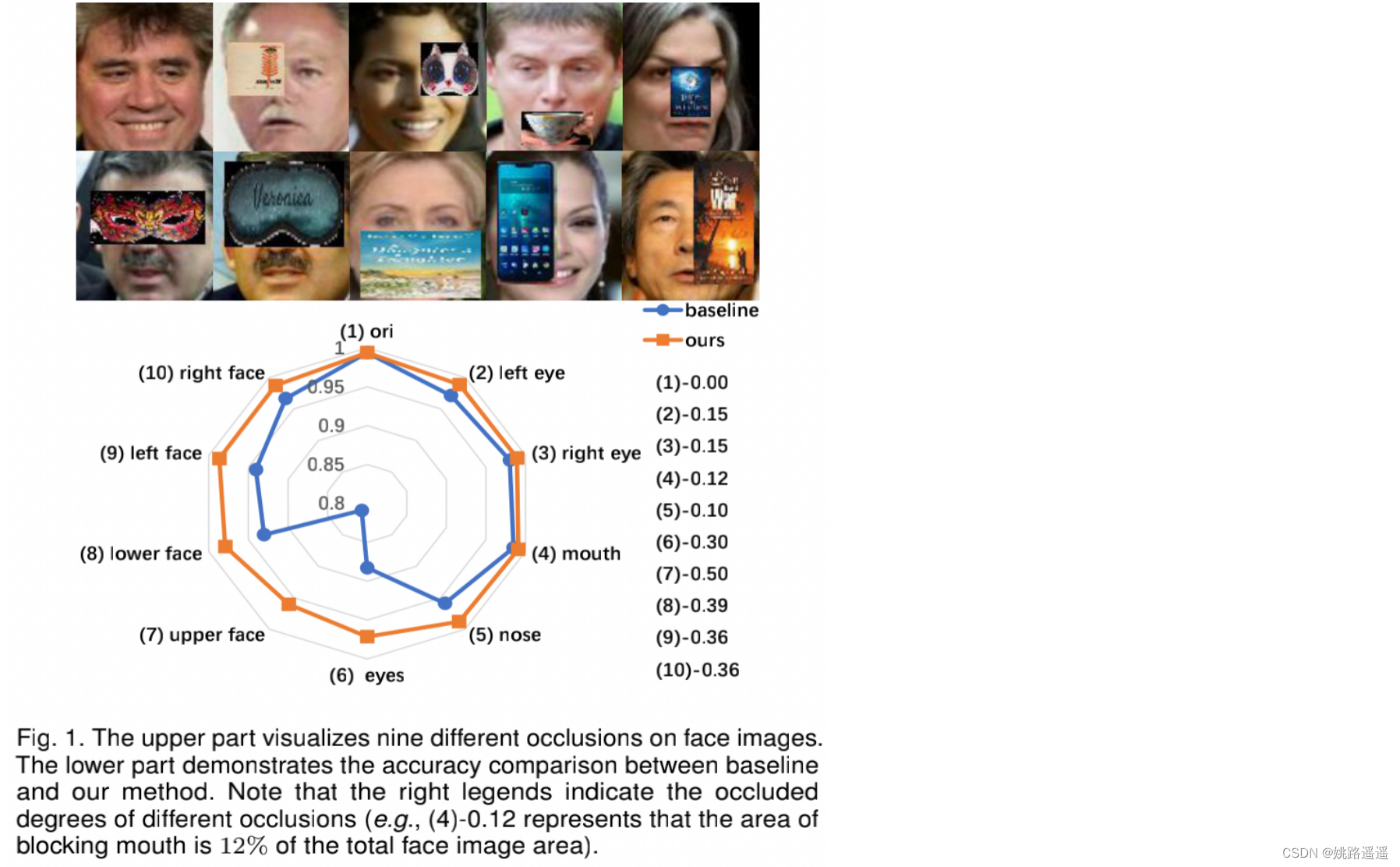
图1:上半部分可视化了面部图像上的九种不同遮挡。 下半部分展示了基线和我们的方法之间的准确性比较。 请注意,右边的图例表示不同遮挡的遮挡程度(例如,(4)-0.12 表示遮挡嘴巴的面积占人脸图像总面积的 12%)。从上图可以大致看出:1)面部遮挡明显影响到了模型效果;2)不同的遮挡区域和遮挡面积造成模型效果下降的程度不一样(例如眼睛被遮挡会显著降低准确率);3)本文提出的算法不仅可以在遮挡状态下明显超过baseline的效果,而且在未遮挡状态下也能保持相当的效果。
2.FROM
2.1.整体架构
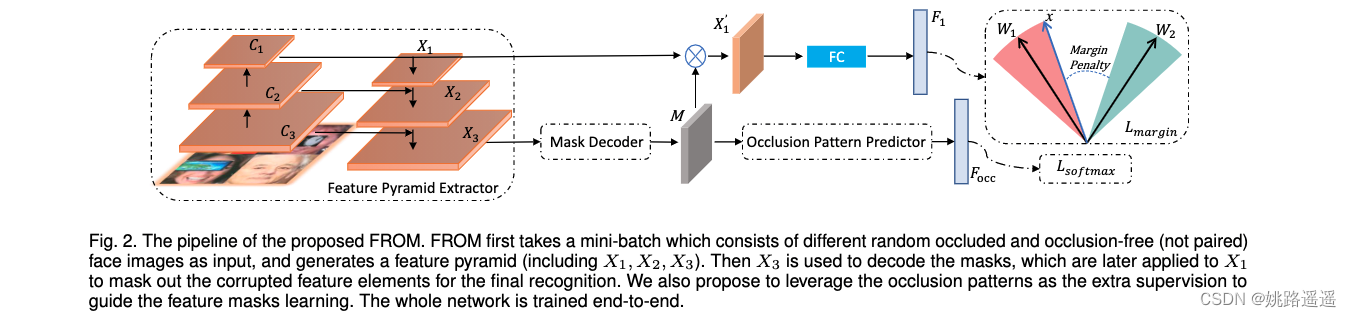
FROM的整体结构如图 2 所示,FROM是一种新颖的单网络端到端方法。 它以一小批随机遮挡和无遮挡(未配对)的面部图像作为输入,并生成金字塔特征,然后将其用于解码特征掩码。 然后,获得的掩码通过乘法mask损坏的元素来清理深层特征,以进行最终识别。
FROM 的核心思想是学习准确的特征掩码以有效地清除损坏的特征。
2.2.Mask Decoder

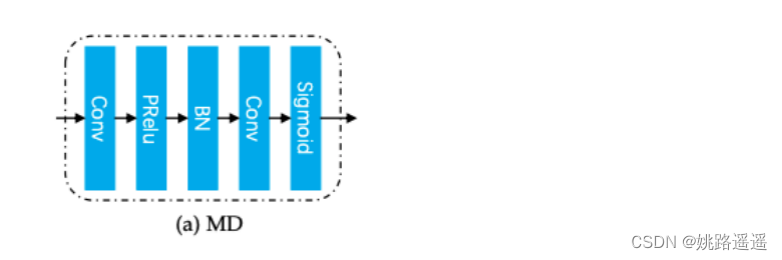
FROM 的原理是学习一个 Mask Decoder 来生成特征掩码,用于精确去除由遮挡引起的损坏特征。 如图 2 所示,它将特征金字塔提取器获得的 conv 特征图 X3 中的遮挡信息解码为特征掩码 M。 期望通过逐元素乘积来屏蔽 X1 的损坏特征元素,以生成清洁的特征 X’1 以供后续识别。 如图 3a 所示,Mask Decoder 被实现为一个简单的“Conv-PReLU-BN-Conv-Sigmoid”结构,其中“Sigmoid”函数用于将输出特征掩码约束到 (0, 1)。 请注意,两个“Conv”层的步幅都设置为 2,以缩小 4 倍分辨率以与 X1 的大小完全匹配。
简而言之,Mask Decoder结构就类似于一个注意力机制模块,让网络去学习出一个合适的权重矩阵来mask掉原特征图中损坏的特征。(只是注意力机制是让网络自适应的去学习,而Mask Decoder后续还有一个Occlusion Pattern Predictor来监督它的学习)在得到权重矩阵M之后,与原特征图进行一个乘积的操作,来mask掉损坏特征以更好的进行后续的识别。
2.3.Occlusion Pattern Predictor

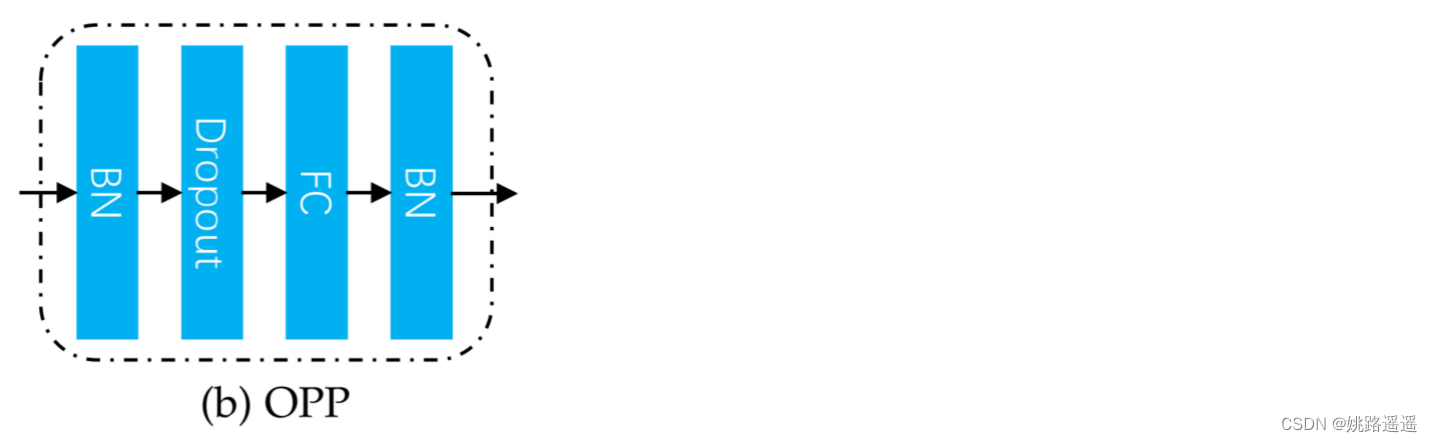
为了鼓励 Mask Decoder 生成与输入人脸图像的遮挡模式相关的掩码,我们将模块 Occlusion Pattern Predictor 引入我们的网络以监督特征掩码学习。 如图 2 所示,它将学习到的特征掩码作为输入并预测遮挡模式向量,然后使用 softmax 损失对其进行分类。 它有一个简单的“BNDropout-FC-BN”结构,其输出通道等于图 3b 中遮挡模式的数量(比如你只想预测口罩遮挡这一个类型,最后的FC层节点个数就设置为2,即二分类是否戴口罩)。 因此,Mask Decoder 被训练生成掩码:1)与输入图像的遮挡相关; 2) 正确屏蔽掉对人脸识别有害的损坏特征。 虽然第一点是通过引入遮挡模式预测器实现的,但第二点是通过应用于掩蔽特征的人脸识别损失(本文中的 CosFace 损失 [4])来监督的。
2.3.1.Proximate Occlusion Patterns
为了探究遮挡模式,提出邻近性。相邻块在实际应用中通常具有相似的遮挡状态(例如,如果嘴巴被遮挡,那么鼻子也很有可能被遮挡)。具体操作如下图所示:
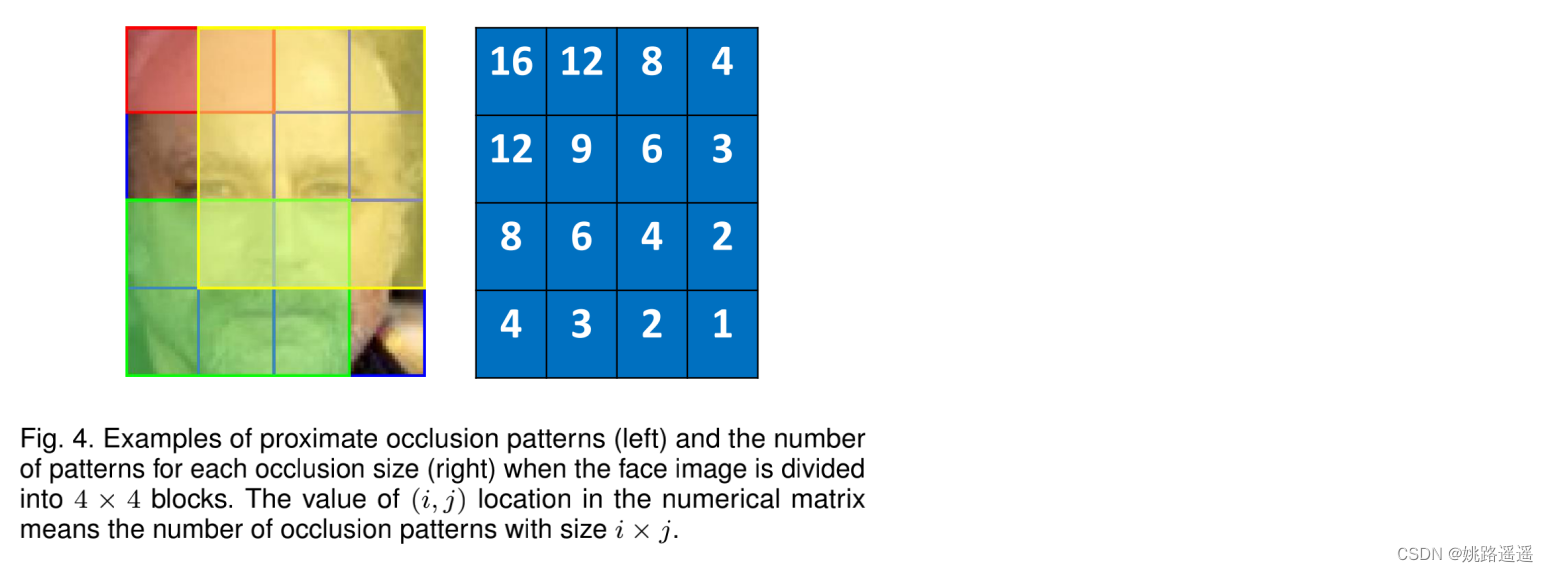
当人脸图像被分成 4 × 4 块时,邻近遮挡模式的示例(左)和每个遮挡大小的模式数量(右)。 数值矩阵中 (i, j) 位置的值表示大小为 i × j 的遮挡模式的数量。通过总结矩阵的所有值,我们有 101 种遮挡模式(100 种被遮挡和另外 1 种未被遮挡)。
举例说明:当图像被分成4 x 4时。以左上角为坐标原点,比如左上角的16,意思就是(1x1)大小的块遮挡模式有16种,同理,右下角的1,意思就是(4x4)大小的块遮挡模式只有1种。
2.3.2.Pattern Prediction
生成的特征掩码应该用于正确预测相应的参考模式。 特别是,在训练阶段,我们有每个图像的遮挡位置。 对于每个图像 Xi,我们通过将其遮挡位置与 226(当 K = 5)遮挡模式匹配来获得其遮挡模式 Yi。 我们的匹配策略是计算遮挡和 226 个参考模式之间的 IoU 分数,然后选择具有最大 IoU 分数的模式作为相应的标签。 从遮挡模式预测器获得遮挡特征向量后,我们采用传统的 softmax 损失及其遮挡模式 Yi,公式如下:
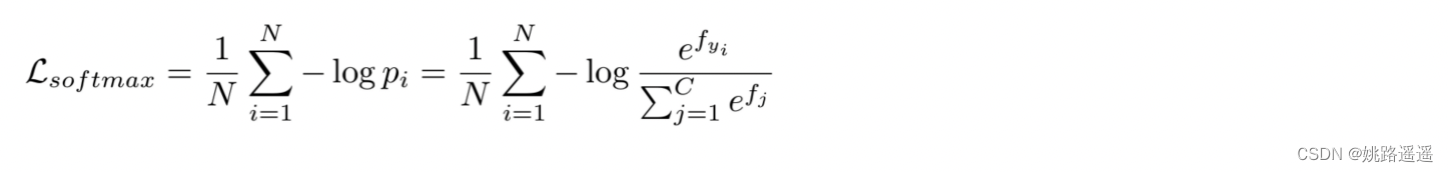
简而言之,就是对于训练数据要确定好遮挡模式,才能进行后续的分类计算。首先,按照预先设定好的K值(也就是图像怎么切,有多少种遮挡模式),将训练数据的真实遮挡情况与设定好的遮挡模式计算iou,这一步是确定图片属于那种类型的遮挡,以便确定好分类标签。然后就是计算分类损失就好了。注意:遮挡模式预测器最终FC层的维度一定要与你设定好的遮挡模式的个数一致。
2.4.总损失

3. 实验
3.1. 遮挡数据集构建

AR 人脸数据集示例和我们合成遮挡的人脸图像。 第一行图像在 WebFace 上以 1 : 0.5 : 5 的随机比例被遮挡。 第二行和第三行图像在 LFW 和 Facescrub 上分别被 1.0、1.5、2.0 遮挡。 最后一行图像来自 AR Face 数据集。

3.2.训练细节
训练阶段可以分为两个步骤。 首先,我们使用具有较大margin的cosine loss在 WebFace 数据集上学习主干网络(即图 2 中的上部分支)。 主干网络训练了 40 个 epoch,初始学习率为 0.1,batch size 为 512。使用权重衰减为 0.0005 和动量为 0.9 的 SGD,在第 15 和 30 个 epoch 将学习率降低 10 倍。然后我们将训练好的来自步骤 1 的模型作为我们的预训练模型,并在 OccWebFace 数据集上微调整个网络,包括特征金字塔提取器、掩码解码器和遮挡模式预测器,该数据集是通过从 1.0 : 0.5 : 5.0 中随机选择作为 Alg1 中的 Scale s 和来自原始 WebFace 数据集的每个图像的遮挡器构建的。
3.3.部分实验结果
3.3.1.Ablation Study

对比权重向量M矩阵的值是使用sigmoid,还是大于某个值直接置为1,反之置为0,意思也就是抑制还是删除(损坏特征)。实验证明抑制好于删除。
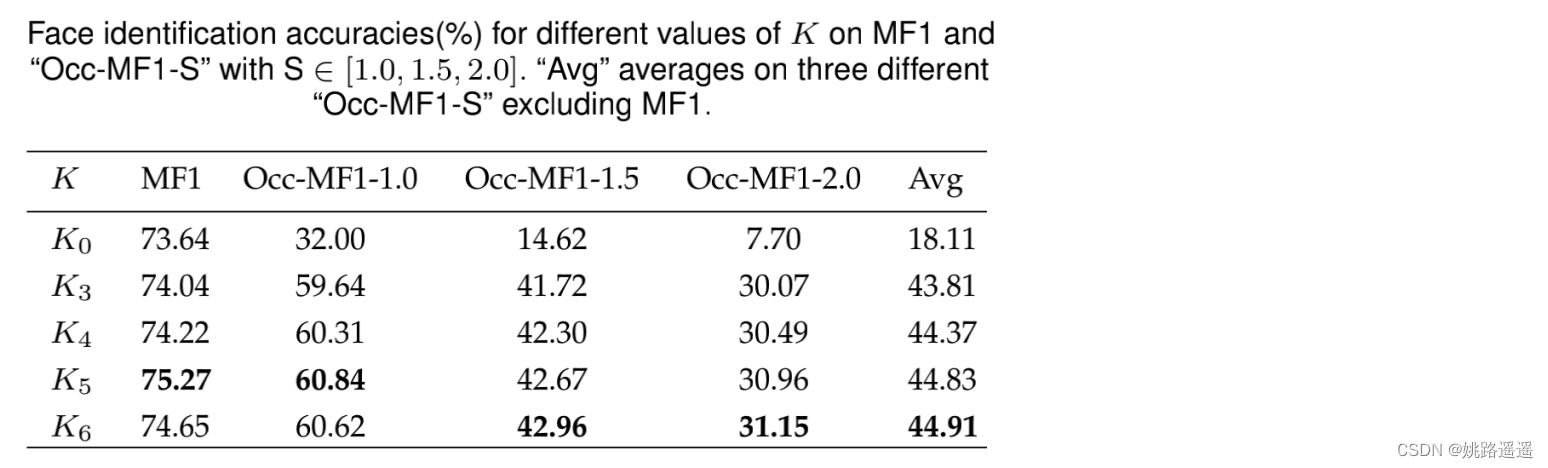 K4, K5, K6的表现基本相同,K3略落后。考虑到速度和精度的权衡,我们采用K = 5(即将人脸图像划分为5 × 5网格)进行其余实验。
K4, K5, K6的表现基本相同,K3略落后。考虑到速度和精度的权衡,我们采用K = 5(即将人脸图像划分为5 × 5网格)进行其余实验。
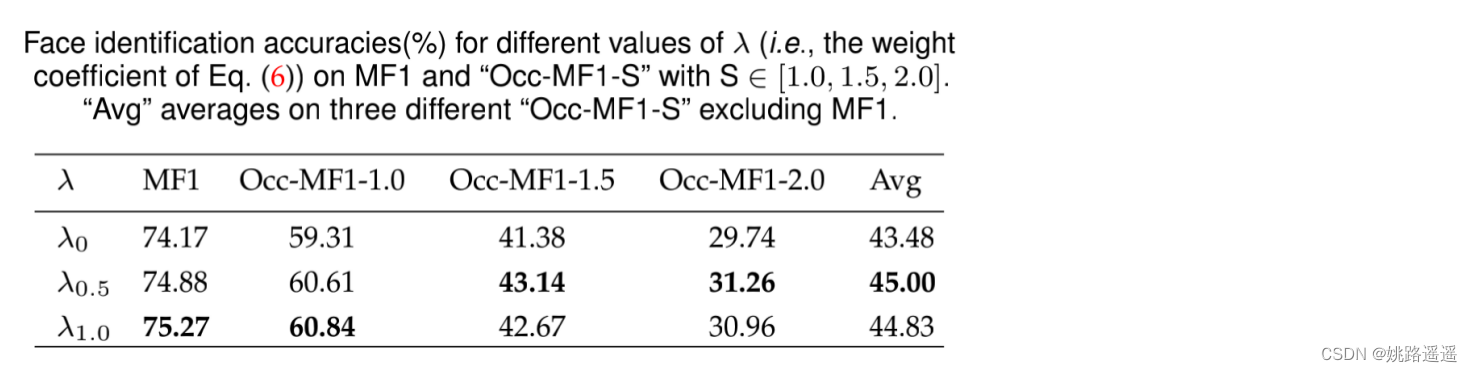
λ=0.5, λ=1具有较好的精度
3.3.2.Comparision to Baselines
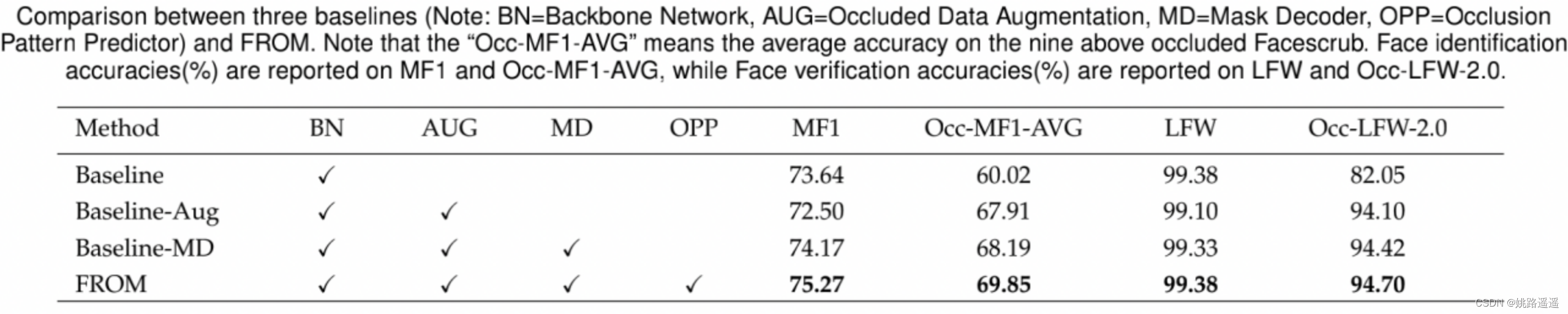
1)带Mask Decoder的Baseline_x0002_MD的性能比Baseline-Aug好,这可能是由额外的网络参数带来的。
2)我们首先发现Baseline- aug的性能略差于Baseline,这可能是由于其遮挡数据微调过程中存在过拟合问题。
3.3.3.Effects of Different Occluded Areas
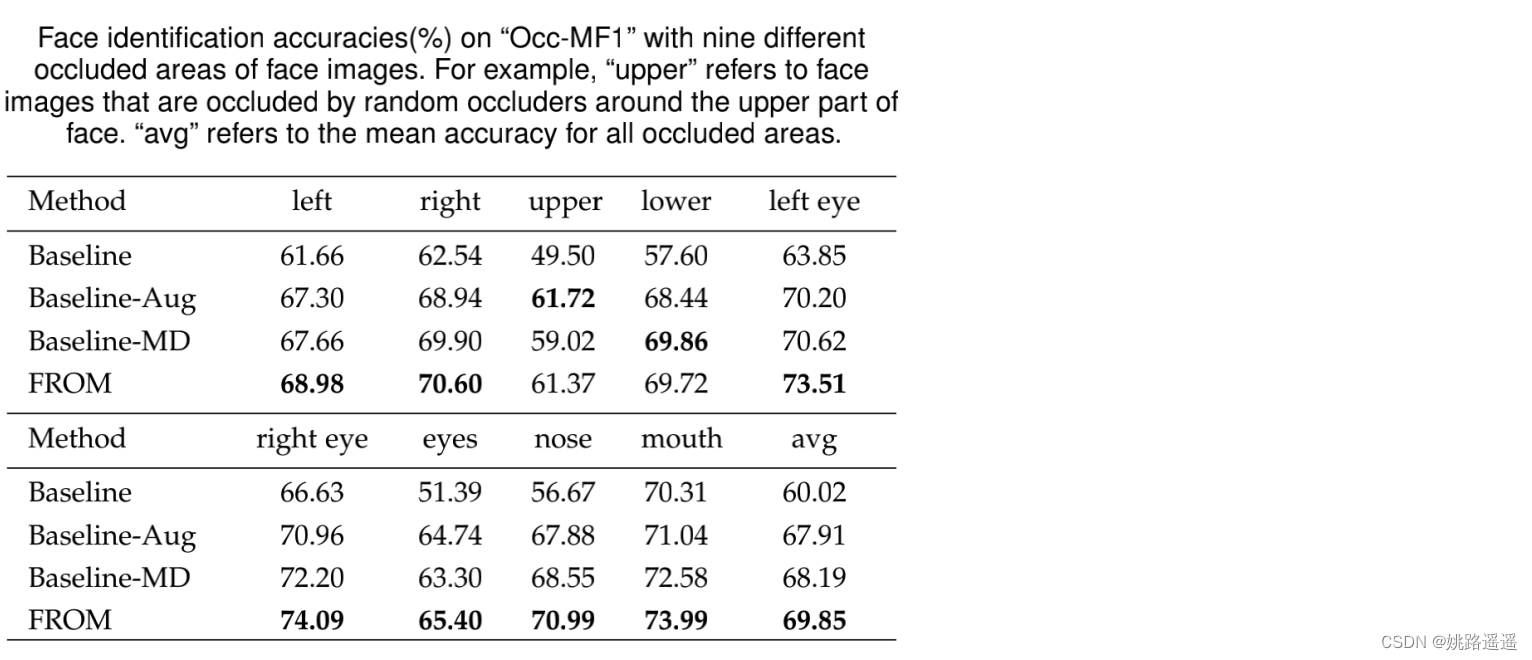
另一个观察结果是,模型在左脸和右脸上的表现非常相似,这可能有助于训练人脸图像的翻转增强。
3.3.4.Benchmark on RMF2, LFW-SM and O_LFW
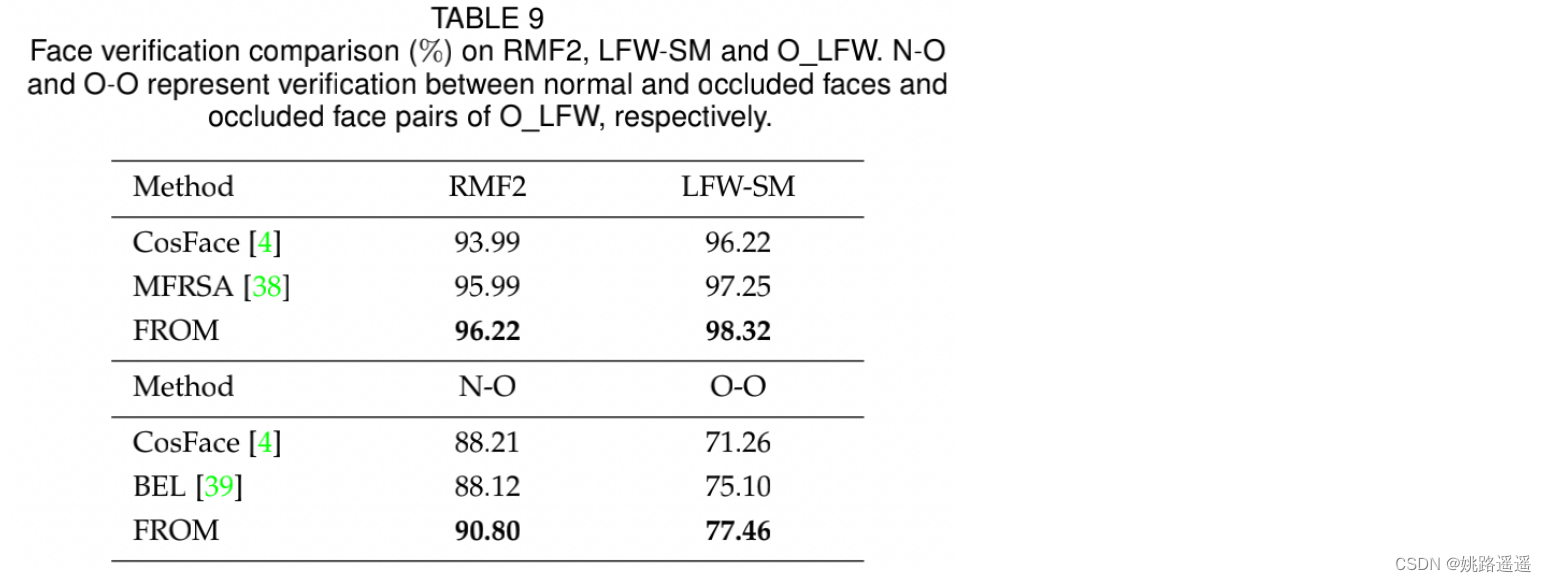
occluded faces (N-O) and occluded face pairs (O-O)
3.3.5.Benchmark on Megaface Challenge 1

同样值得注意的是,PDSN的56.34%的精度是50个遮挡区域的平均精度,然而,在他们的论文中没有详细说明。因此,在相同的配置下,我们无法得到公平比较的结果。但是,我们在随机位置遮挡上上获得了60.84%的准确率,这比50个区域更不受约束,也更困难,使我们的结果更有说服力。
3.3.6.Benchmark on AR Face Dataset
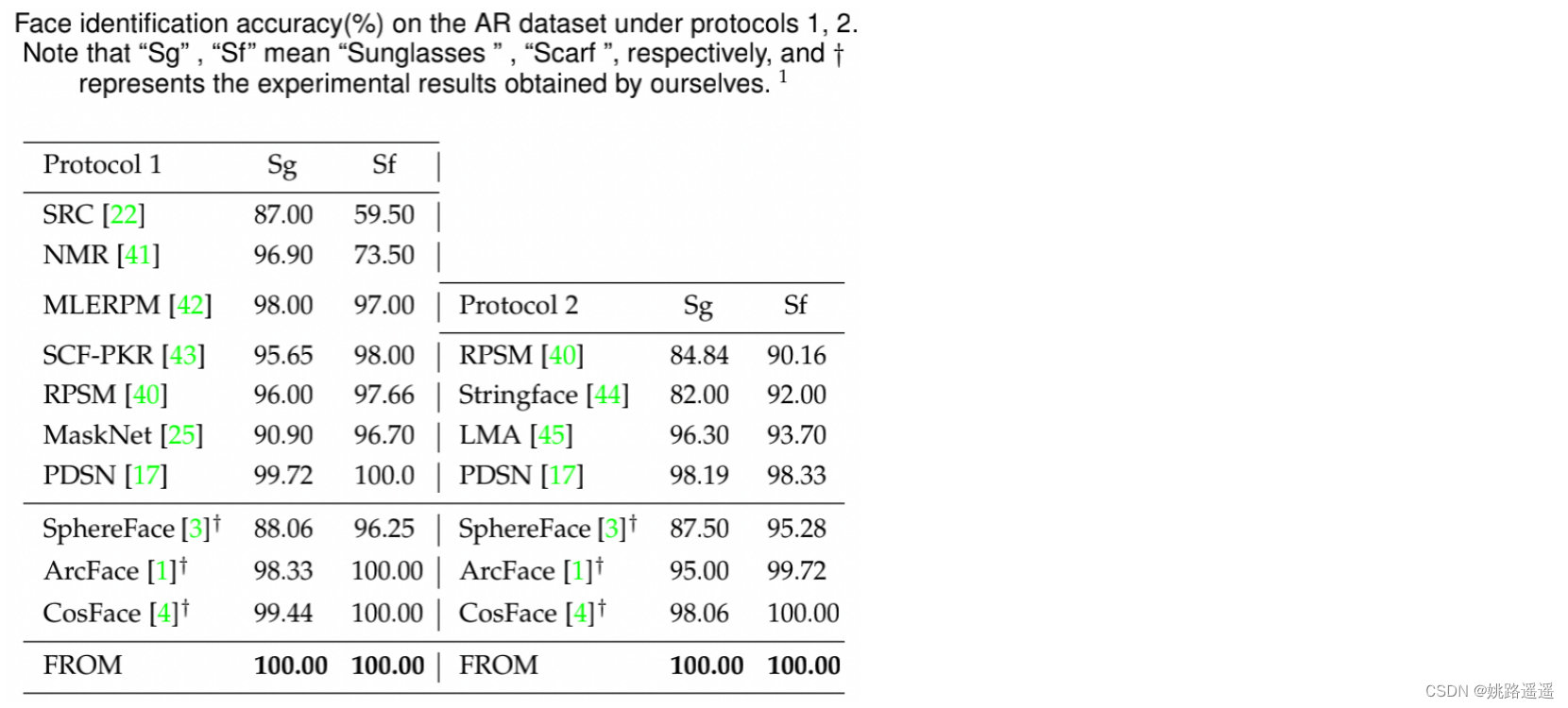
1)对于SphereFace,我们使用public code及其预训练的模型 。
2)对于CosFace和ArcFace,我们自己用相应的损失训练模型,并得到实验结果。