国家统计局教育部各级各类学历教育学生情况数据爬取
教育部数据爬取
- 1、数据来源
- 2、爬取目标
- 3、网页分析
- 4、爬取与解析
- 5、如何使用Excel打开CSV
1、数据来源
国家统计局:http://www.stats.gov.cn/sj/
教育部:http://www.moe.gov.cn/jyb_sjzl/
数据来源:国家统计局教育部文献教育统计数据2021年全国基本情况(各级各类学历教育学生情况)
我们看到,最新的数据是到2021年
2、爬取目标
本次,我们爬取2021年教育统计数据全国基本情况各级各类学历教育学生情况数据
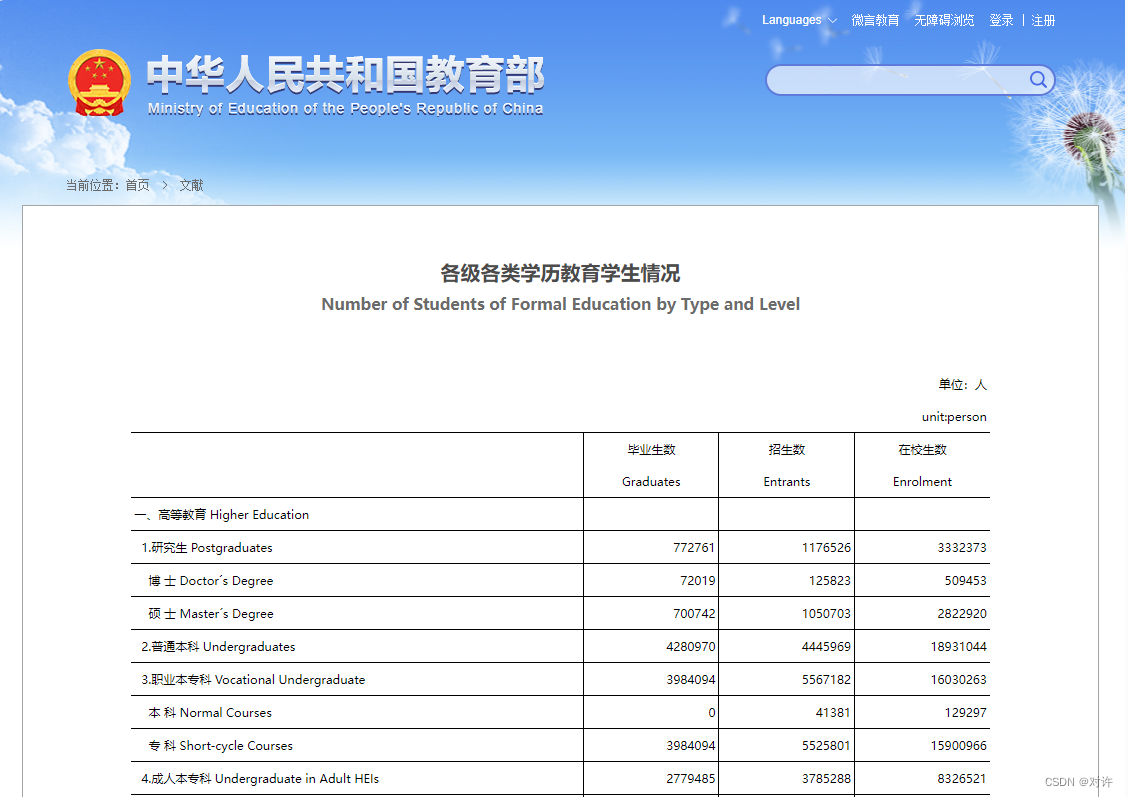
数据(部分)如下:
爬虫前必备知识:Python网络爬虫基本库详解:https://blog.csdn.net/weixin_55629186/article/details/132415946
3、网页分析
经过分析,我们发现,数据形式为HTML,数据主要嵌入在table标签中
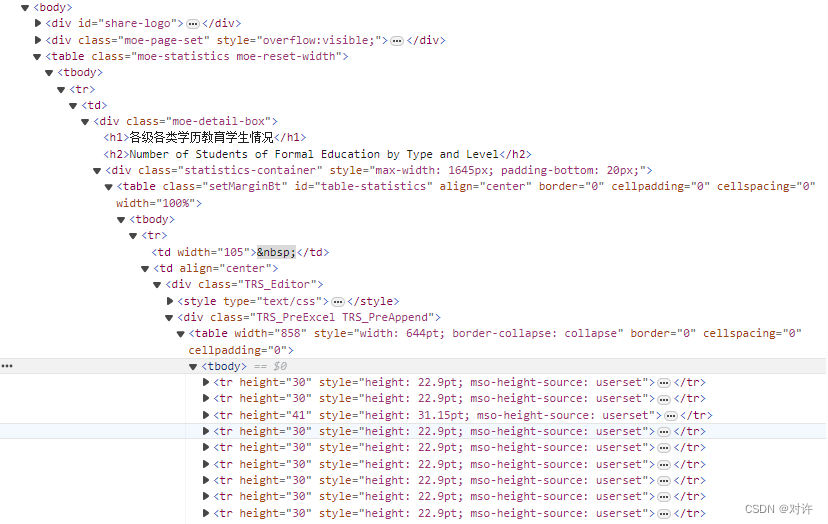
4、爬取与解析
1)环境准备
import numpy as np
import pandas as pd
import requests
import re
from bs4 import BeautifulSoup
2)发起请求,获取响应
# URL
url = 'http://www.moe.gov.cn/jyb_sjzl/moe_560/2021/quanguo/202301/t20230104_1038067.html'
# 数据保存路径
out_path = r"C:\Users\cc\Desktop"def get_html_str(callback):headers = {