Python的web自动化学习(五)Selenium的隐式等待(元素定位)
引言:
WebDriver隐式等待是一种全局性的等待方式,它会在查找元素时设置一个固定的等待时间。当使用隐式等待时,WebDriver会在查找元素时等待一段时间,如果在等待时间内找到了元素,则立即执行下一步操作;如果超过等待时间仍未找到元素,则抛出NoSuchElementException异常。
其元素定位8种方法
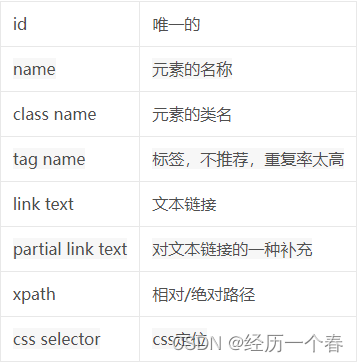
1.通过id或name定位
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">#通过元素所带的id和name属性对元素定位:
brower.find_element_by_id("kw")
brower.find_element_by_name("wd")
2.通过class name或tag name定位
<div class="jstEditor">
<textarea cols="60" rows="10" accesskey="e" class="wiki-edit" name="issue[description]" id="issue_description">
</textarea>
</div>通过元素中带的class属性定位
brower.find_element_by_class_name("iki-edit")通过元素中的tag标签定位,这种定位方式极不靠谱,不推荐采取此种方式。
brower.find_element_by_tag_name("div")附加说明,如果class属性含有空格,那么取其中一个不重复的字段就可以了,例子:
<a title="新建版本" tabindex="200" class="icon-only icon-add" data-remote="true" data-method="get" href="/projects/bk_community/versions/new">新建版本</a>其中class的属性值为“icon-only icon-add”,取其中“icon-only”、“ icon-add”都可以,但最好是取其中唯一的。
brower.find_element_by_class_name("icon-add")
3.通过link text和partial link text定位
<a href="http://news.baidu.com" target="_blank" class="mnav">新闻</a>
通过text link定位元素
brower.find_element_by_link_text("新闻")通过partial link text定位元素,当文字链接很长时,可以通过此方式取其中一部分,只要取的部分可以作为唯一标识。brower.find_element_by_partial_link_text("新")
4.xpath定位
此种定位方式需知晓xpath路径,通过火狐浏览器就可以知道,具体如何操作,可参考我的另一篇博文https://blog.csdn.net/qq_30990097/article/details/81325681调用的方法为:brower.find_element_by_xpath("/html/body/div[1]/div/div[2]/ul/li[2]")
也可以通过相对路径自行填写,例如://*[@id="su"]/form/span/input #通过上三级目录的id属性定位当然也可以通过某一级的name属性定位。
5.CSS定位
css定位有点麻烦,方法很多。以百度输入框html代码为例:<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
定义浏览器
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
6.通过id或class属性定位,方法见代码注释
#css通过id属性定位,用#号表示id属性browser.find_element_by_css_selector("#kw").send_keys("css通过id属性定位")#css通过class属性定位,用.表示class属性browser.find_element_by_css_selector(".s_ipt").clear()
7.通过标签定位
#css通过标签属性定位,无任何标识符,最好加上一个固定属性,否则会出错browser.find_element_by_css_selector("input[class=s_ipt]").send_keys("css通过标签属性定位")browser.find_element_by_css_selector("input#kw").send_keys("css通过标签属性定位")通过其他属性定位#css通过其他属性定位browser.find_element_by_css_selector("[name='wd']").send_keys("css通过name属性定位")browser.find_element_by_css_selector("[autocomplete='off']").clear()通过css层级关系定位还是以百度的输入框html代码为示例:定位代码:#css层级关系browser.find_element_by_css_selector("form#form>span>input").send_keys("通过层级定位")browser.find_element_by_css_selector("form.fm>span>input").clear()
8. 通过css索引定位
示例html代码:定位代码:#通过css索引定位browser.find_element_by_css_selector("select.pagination-page-list>option:nth-child(1)").click()