Elasticsearch:在你的数据上训练大型语言模型 (LLM)

过去的一两年,大型语言模型(LLM)席卷了互联网。 最近 Google 推出的 PaLM 2 和 OpenAI 推出的 GPT 4激发了企业的想象力。 跨领域构思了许多潜在的用例。 多语言客户支持、代码生成、内容创建和高级聊天机器人都是一些例子。 这些用例要求 LLMs 根据业务的自定义数据做出响应。
企业如何借助 LLMs 对其自定义数据解决这些用例? 经过一些研究和接触 LLMs 后,我发现了三种方法。
- Prompt Engineering
- Embeddings
- Fine Tuning

Prompt Engineering
什么是提示 (prompt)?
提示是 LLM 的输入。 例如,在下图中,提示是:
“Recommend me 5 fiction novels similar to the Bourne Series. Write only the title and author name.”

提示中的自定义数据
在提示中注入数据或上下文是在 LLM 中使用自定义数据的最简单方法。 例如,在下图中,提示包含某公司 2023 年第一季度和 2023 年第二季度的销售数据。 LLM 的问题是返回销售额的百分比变化。

何时使用 prompt engineering?
Prompt engineering 有很多应用。 事实上,Prompt engineering 被认为是一项未来将令人垂涎的关键技能。
在你想要向 LLM 提供说明、执行搜索操作或从较小的数据集中获取查询答案的情况下,在提示中传递数据效果很好。 但是,由于提示的大小和将大型文本传递给 LLM 相关的成本的限制,这并不是将大量文档或网页作为 LLM 输入的最佳方式。
嵌入 - embeddings
什么是嵌入?
嵌入是将信息(无论是文本、图像还是音频)表示为数字形式的一种方式。 想象一下,你想要根据相似性对苹果、香蕉和橙子进行分组。 这可以使用 “嵌入” 来完成。
嵌入会将每种类型的水果转换为数字形式(向量)。 考虑下面的例子,
- 苹果 -> (3, 8, 7)
- 香蕉 -> (8, 1, 3)
- 橙子 -> (4, 7, 6)
苹果和橙子的这些嵌入彼此更接近。 我们可以说苹果和橙子更相似。
使用嵌入
下图从概念上解释了如何使用这些嵌入来使用 LLM 从你的文档中检索信息。 首先,文档通过一个模型,该模型创建文档的小块,然后创建这些块的嵌入。 然后将这些嵌入存储在向量数据库中。 当用户想要查询 LLM 时,将从向量存储中检索嵌入并将其传递给 LLM。 LLM 使用嵌入从自定义数据生成响应。
这篇文章是一个为文档生成嵌入并将这些嵌入传递到 Chat GPT 的工作示例。

目前 Elasticsearch 是时间上下载量最大的向量数据库。我们可以使用 Elasticsearch 作为上图中的 Vector DB。

在实际的使用中,为了得到更好的响应,我们可以把从向量数据库中搜索出来的结果进行组合,已提供更多的上下文:

什么时候使用嵌入?
当需要将大量文档或网页传递给 LLM 时,嵌入效果很好。 例如,当构建聊天机器人来向用户提供一组策略文档的响应时,此方法会很有效。
微调
什么是微调 (fine tuning)?
微调是一种教导模型如何处理输入查询以及如何表示响应的方法。 例如,LLM 可以通过提供有关客户评论和相应情绪的数据进行微调。
Prompt: I really liked this product. I highly recommend it.
Completion: Positive
Prompt: I found the delivery experience below average.
Completion: Negative这里 “prompt” 是输入的示例,“completion”是相应输出的示例。
现在,如果你向 LLM 提供另一条评论作为提示,那么它会以相应的情绪做出回应。
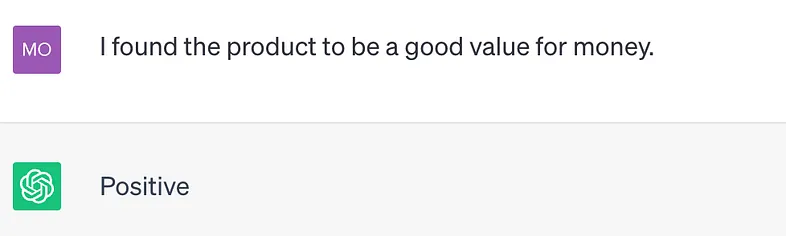
另一个例子是:
Prompt: Q1 2023, $10 million, +5%, good, positive
Completion: The revenue for Q1 2023 was $10 million, which is 5% higher than revenue in the previous quarter. The sentiment on the streets is good for this company and there is a positive outlook for the business.
Prompt: Q2 2023, $20 million, -2%, neutral, negative
Completion: The revenue for Q2 2023 was $20 million, which is 2% lower than revenue in the previous quarter. The sentiment on the streets is neutral for this company and there is a negative outlook for the business.你可以提供许多示例来微调模型,然后向模型提出问题。
微调可用于有限的基本模型 - davinci、curie、babbage 和 ada。
什么时候使用微调?
微调通常用于针对特定任务调整 LLM 并在该范围内获得响应。 该任务可以是电子邮件分类、情感分析、实体提取、根据规格生成产品描述等。
这篇文章仅仅触及了这些技术的表面。 其中每一个都有更多的细微差别。