语雀P0级时间爆发,留给运维的时间不多了?
事件背景
打工人的焦虑,已经延伸到在线文档了。近日,语雀P0级故障想必大家都有所体会,宕机近8小时,笔记、离线同步完全不可用。作为用户尤其担心我的文档资料是否会因此消失。
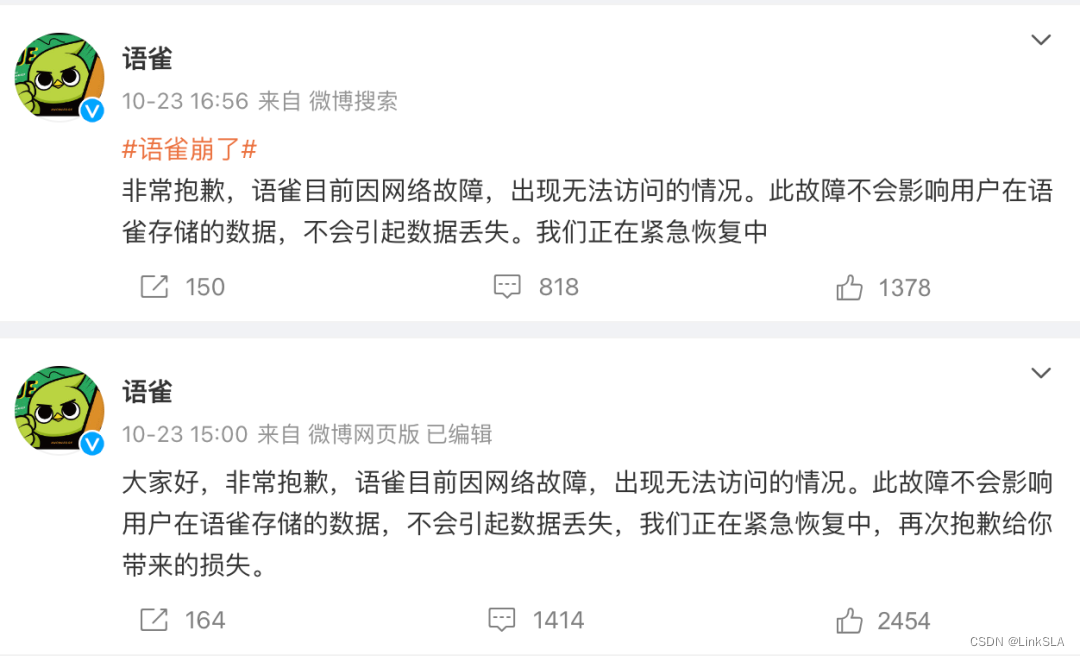
这泼天的8小时,放眼互联网界也是相当炸裂的。
从次日的故障处理通报可知,团队在收到运维监控系统报警后,定位故障根因来自于新的运维升级工具中的一个致命bug,该bug带来了一系列严重的影响。更深层次的问题在于高可用架构体系的设计、运维流程,以及项目规范的不完善。
教训是个体的,经验是共享的。语雀表示:作为一款千万级用户的在线文档,应该做到更完善的技术风险保障和高可用架构设计,尤其是面向技术变更操作的“可监控,可灰度,可回滚”的系统化建设和流程审计,从同 Region 多副本容灾升级为两地三中心的高可用能力,设计足够的数据和系统冗余实现快速恢复,并进行定期的容灾应急演练。
如何提升运维效率,保障系统的稳定运维,故障如何才能快速恢复,并从根本上避免此类故障再次出现才是运维的核心要义。
一、不断完善监控系统
「无监控,不运维」,监控系统的地位不言而喻。监控什么,能发挥什么价值,结合LinkSLA智能运维管家进一步阐述。
1、实时采集监控数据,
包括硬件、操作系统、中间件、应用程序等各个维度的数据。实时掌握瞬息万变的复杂的业务系统,对业务的健康稳定有着极其重要的价值。
2、实时反馈监控状态,
通过对采集的数据进行多维度统计和可视化展示,能实时体现监控对象的状态是正常还是异常。
3、预知故障和告警,
能够提前预知故障风险,并及时发出告警信息。
4、辅助定位故障,
提供故障发生时的各项指标数据,辅助故障分析和定位。
5、辅助性能调优,
为性能调优提供数据支持,比如慢SQL分析与优化,接口响应时间等。
6、辅助容量规划,
为服务器、中间件以及应用集群的容量规划提供数据支撑。例如看似简单的空间增长问题,实际检查起来非常费时费力,很多用户会过滤掉,不愿为这种小事每天做例行检查。通过AI机器学习算法,进行趋势性监测分析,提前一周告知客户,做好空间规划与清理。
二、更有效地使用监控系统
在故障复盘时,有没有做监控?监控是否及时?监控信息是否有助于快速定位问题?这三个问题一定会被追问。可见有监控系统还远远不够,如何用好才是关键。
1、统一部署,全链路监控
将分散监控实现集中统一的监控管理,建立统一的事件管理体系,对告警严重等级设定标准、规范事件处理流程,提高运维效率。通过可视化大屏,可全面直观地掌握业务系统及IT资源运行状态。
2、趋势预测,提前预知
清楚使用哪些指标来刻画监控对象的状态,比如对某个接口进行监控,可以采用请求量、耗时、超时量、异常量等指标来衡量。
机器学习算法通过数据分析趋势变化,对未来趋势进行预测,自动调整阈值,提前对故障进行响应,实现告警收敛、异常监测, 辅助运维人员聚焦关键故障信息,极大程度地提高运维效率。
3、设定合理的报警阈值和等级
达到什么阈值需要告警?对应的故障等级是多少?
传统运维依赖人工和静态规则,无法适应动态复杂变化的场景。LinkSLA智能运维可基于历史数据,利用智能算法深度学习,对未来时间段的数值精准预测,将预测值作为基线,更贴近用户使用场景。
告警分为5个等级,对应的处理方式也不同。MOC在线值守工程师根据告警等级,选择在线处理或沟通现场工程师进行处理,确保问题得到及时响应。
三、 完善的故障处理流程
1、快速恢复——应急预案很重要
应急方案很重要,故障处理第一原则是快速恢复。系统恢复运行足够快,就不会造成太大影响。一个合格的应急方案,要包含系统、服务、辅助工具等方面。如系统或上下游出现问题,知道如何配合上下游分析问题;服务上如日志、程序、配置文件在哪里,如何检查服务是否正常,如何重启服务,如何调整应用级参数等。知晓这个服务影响什么业务;辅助工具上如何使用自动化工具辅助分析并应急。这就要求运维人员熟悉系统逻辑,架构部署,应用作用,端口,服务等级的应急处理。
2、告警要及时、准确
故障处理的时效性,关键在于是否及时发现故障,是否及时处理故障。这两点的前提还在于告警是否准确。如果运维监控平台产生大量的错误、重复、无效告警,则大大降低了运维的效率,浪费大量的精力和成本处理这些无效告警。
试用2个月的用户表示 “告警减少了65%,MTTR减少了30%”大大的节约了公司处理告警的时间成本和风险。戳👇
仅用2个月,告警减少65%,这家公司做对什么?
3、完善故障处理流程
在日常的运维场景中,普遍存在2个问题。一是无法时刻关注系统的告警情况,其次是遇到告警问题不知该如何处理。MOC工程师7*24值守解决系统关注问题,固化ITIL流程,当系统出现故障报警后会对报警信息进行筛选,对于高危报警能第一时间通知客户,并提供技术支持。这一点大大降低用户的系统风险和人力成本的投入,解决告警处理问题。
在故障处理案例中,从问题的发现到解除,只用了15分钟。戳👇
案例分享|从发现到处理,15分钟故障解决