二叉树的后续遍历(迭代法)
迭代法实现二叉树的后续遍历
1、递归版本
public static void dfs(TreeNode root){if(root==null){return;}if(root.left!=null)dfs(root.left);if(root.right!=null)dfs(root.right);System.out.println(root.val);
}
从递归版本可以看出我们第一步需要遍历完所有的左节点
这里我们使用一个栈来存储树的节点,模拟递归的先进后出。
Stack<TreeNode> stack = new Stack<>();
if(root!=null){return;
}
stack.push(root);
while(!stack.isEmpty()){//遍历所有的左节点直到左节点为nullwhile(root!=null&&root.left!=null){root = root.left;stack.push(root);}//再看递归的第二步就是访问右子树。root = stack.pop(); //取出栈顶元素,准备遍历它的右子树if(root.right==null){ //说明没有右子树,就可以直接访问root节点了System.out.println(root.val);}else{//然后就又会回到上面那个while循环遍历这个右子树所有的左节点root = root.right; stack.push(root);}
}
上面就是大致的逻辑,但还有两个重要的问题没有解决。
问题1:关于左子树的重复访问。
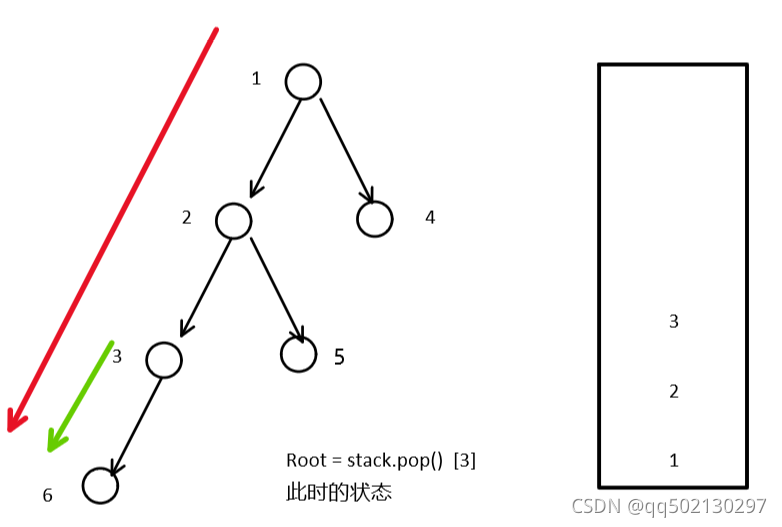
1、当栈顶节点为3时,root = stack.pop() 。此时root指向3节点
2、然后进入while循环,又会将6号节点再次访问一遍。因为1号节点已经访问过6了。
红色箭头表示对于root节点,访问它左子树的所有左节点。
绿色箭头表示3节点,访问它左子树的所有左节点。可以看出6节点是重复访问了的。
解决方法:对于从栈中取出的节点,如果没有右子树就设置为null。
Stack<TreeNode> stack = new Stack<>();
if(root!=null){return;
}
stack.push(root);
while(!stack.isEmpty()){while(root!=null&&root.left!=null){root = root.left;stack.push(root);}root = stack.pop(); if(root.right==null){ root = null; //防止重复访问左节点System.out.println(root.val);}else{root = root.right; stack.push(root);}
}
问题2:
栈顶取出的节点有右子树的情况下,造成该节点没有被访问。
while(!stack.isEmpty()){while(root!=null&&root.left!=null){root = root.left;stack.push(root);}root = stack.pop(); if(root.right==null){ root = null;System.out.println(root.val);}else{ //含有右子树时。这时的root并没有被访问,而root也被root = root.right;覆盖掉了。所以就会造成当前节点root缺失访问。root = root.right; stack.push(root);}
}
解决方案:在root被root = root.right覆盖之前再将root存回栈中。
我们将root取出来的目的就是访问它的右子树。
while(!stack.isEmpty()){while(root!=null&&root.left!=null){root = root.left;stack.push(root);}root = stack.pop(); if(root.right==null){ root = null;System.out.println(root.val);}else{ stack.push(root); //保存当前节点root = root.right; stack.push(root); //保存当前节点的右子节点}
}
虽然解决了在栈顶取出的节点有右子树的情况下造成该节点没有被访问的问题,但又引出了一个新的问题,重复访问右子节点。
为了解决缺失访问时将2节点存入了栈两次。
1、一次是遍历所有左子树的所有左子节点加入的。(这次的加入目的是用来遍历该节点右子树的)
2、一次是为了解决缺失访问又将2节点存入栈中。(这次的目的是为了在遍历完右子树后再访问2节点用的。因为是后序遍历)
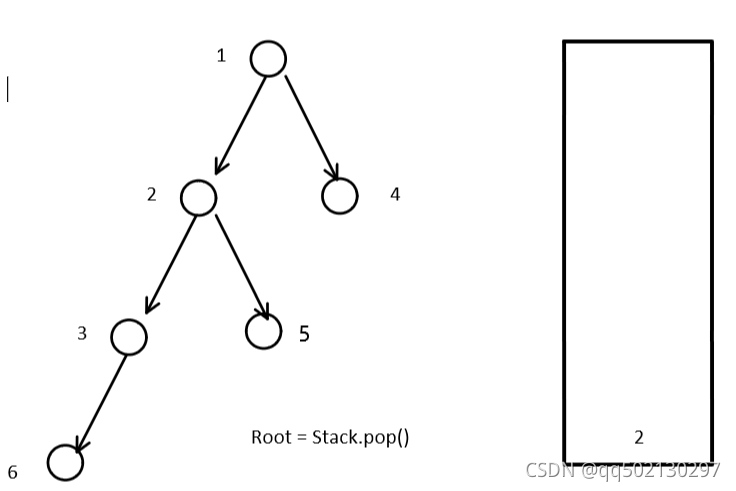
通过代码可以看出,如果我们不加以限制,那么这个2节点就会第三次,第四次…入z栈造成重复访问。
我们的需求是对于有右子树的节点只访问两次。所以我们可以引入一个标记。
TreeNode pre = null
pre变量的作用就是标识该节点的右子树是否已经遍历过了,如果遍历过了。我们就不将其再次入栈了。
当pre==root.right说明右子树已经访问过了。
最终版本
//这个pre防止重复遍历右子树
TreeNode pre = null;while(!stack.isEmpty()){while (root!=null&&root.left != null) {root = root.left;stack.push(root);}root = stack.pop();//pre==root.rightif(root.right==null||pre==root.right){pre = root;System.out.println(root.val);//这个root设置为null防止重复遍历左子树root = null;}else{stack.push(root);root = root.right;stack.push(root);}}
如果节点2的右子树等于pre就说明这个右子树已经访问过了。2节点的左右子树都访问完就可以按照同样操作继续处理1节点了。
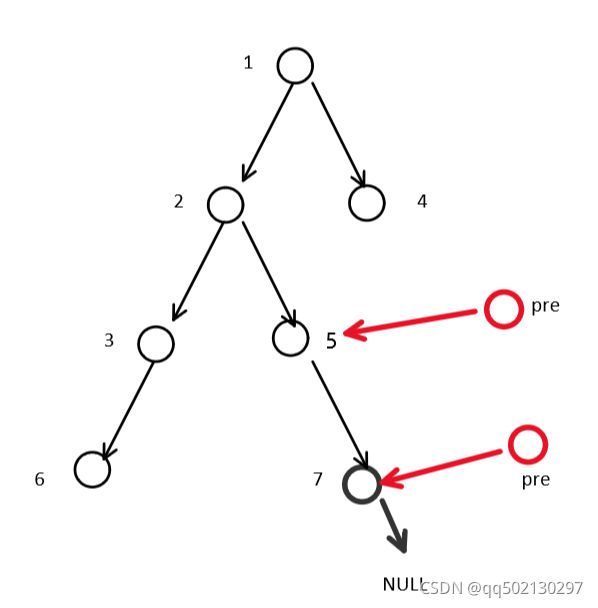
从图中可以看出pre指针是从下往上一步一步传递上去的。