HTTP发起请求与收到响应的大致过程
可以《《透视 HTTP 协议》Windows 10 搭建最小实验环境》搭建环境,之后才能进行下边的操作。
1.鼠标左键点击两下www目录下的start.bat批处理文件。
2.打开Wireshark,然后选择Adapter for loopback traffic capture。

3.然后把tcp.port == 80 || udp.port == 80搜索条件放到搜索框里边。
4.在浏览器里边输入http://127.0.0.1/再按下回车键,等着欢迎页面出来后,就会有捕获的数据包。
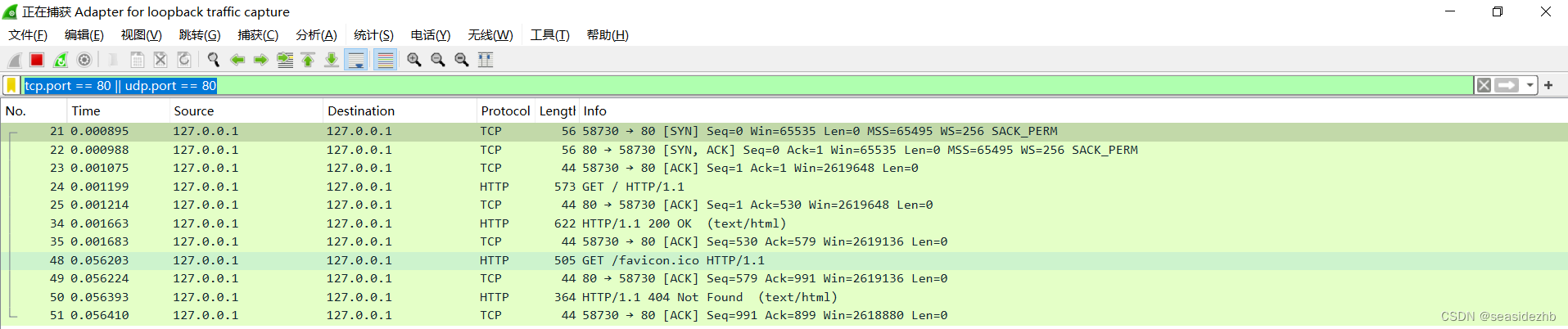
可以看到有十一条数据。
使用IP建立连接抓包分析
HTTP 协议是运行在 TCP/IP 基础上的,依靠 TCP/IP 协议来实现数据的可靠传输。所以浏览器要用 HTTP 协议收发数据,首先要做的就是建立 TCP 连接。
在浏览器里边直接输入127.0.0.1,Web 服务器的默认端口是 80,所以浏览器就要依照 TCP 协议的规范,直接就开始进行“三次握手”,建立与 Web 服务器的连接。
从图中可以看到浏览器使用的端口是58730,No.列显示为21、22和23这三行就是TCP的三次握手,分别是ACK、SYN/ACK、ACK的三个包,经过这三个包之后,TCP连接才建立起来。

No.列显示为24那行数据表明浏览器按照HTTP协议规定的格式,通过TCP发送了一个GET / HTTP/1.1请求报文。
No.列显示为25那行数据是Web服务器通过TCP协议进行确认刚才的报文我已经收到了,不过这个TCP包,HTTP协议是看不到的。
Web服务器在收到报文之后,就要开始处理这个请求。这里就需要依据HTTP协议的规定,解析报文,看看浏览器到底想要干什么。它解析之后,发现浏览器想要获取根目录下的默认文件,那么它就把磁盘上把这个文件全部读出来,在拼成HTTP格式的报文,发回去。这就是No.列显示为34那个包HTTP/1.1 200 OK,底层走的还是TCP协议。
No.列显示为35的包是浏览器通过TCP协议告诉服务器,我收到你的报文了。
这时候,浏览器收到了响应数据之后,开始解析报文。发现这是HTML文件,那么就开始调用排版引擎、JavaScript引擎等等进行处理,最后就在窗口里边展现出来欢迎页面。
这之后还有两个来回,共4个包,重复了相同的步骤。这是浏览器自动请求了作为网站图标的favicon.ico文件,与我们输入的网址没有关系,与我们输入的网址没有关系,但是因为我们的实验环境没有这个文件,所以服务器找不到,之后回复404 Not Found。
这就是键入网址再按下回车的全过程。
使用域名访问Web服务器
在浏览器里边输入http://www.chrono.com/之后,再次进行抓包。

这次好像没有什么不同,浏览器中同样显示出欢迎页面,抓到的包同样还是11个:先是三次握手,然后是两次HTTP传输。
将域名转化成IP就需要DNS了。但是因为域名解析的全过程实在麻烦,若每一个域名都要去网上查一下,那么我们上网肯定会慢得受不了。
域名解析的过程有多级缓存。首先浏览器会看自己的缓存,没有对应的域名解析的话,就会向操作系统的缓存索要,如果没有的话,就需要检查本机域名解析文件hosts——C:\Windows\System32\drivers\etc\hosts,正好发现有一行映射关系127.0.0.1 www.chrono.com,这样的话,浏览器就可以知道了域名对应的IP地址,这样就可以建立TCP连接了。
真实的网络世界
第一个实验就是只有浏览器和服务器两个角色,浏览器直接通过IP地址找到服务器,两者直接建立TCP连接后发送HTTP报文通信。
第二个实验在浏览器和服务器之间增加了一个DNS的角色,浏览器不知道服务器的IP地址,所以必须借助DNS的域名解析功能得到IP地址,然后才能借助IP地址才能与服务器通信。
而在真实的网络世界,可能需要DNS协议从操作系统、本地DNS、根DNS、顶级DNS、权威 DNS 的层层解析,当然这中间有缓存,或许不会费太多时间就能拿到结果。
CDN也会在 DNS 的解析过程中帮上忙。DNS 解析可能会给出 CDN 服务器的 IP 地址,这样你拿到的就会是 CDN 服务器而不是目标网站的实际地址。
因为 CDN 会缓存网站的大部分资源,比如图片、CSS 样式表,所以有的 HTTP 请求就不需要再发到 Apple,CDN 就可以直接响应你的请求,把数据发给你。
由 PHP、Java 等后台服务动态生成的页面属于“动态资源”,CDN 无法缓存,只能从目标网站获取。于是你发出的 HTTP 请求就要开始在互联网上的“漫长跋涉”,经过无数的路由器、网关、代理,最后到达目的地。
此文章为10月Day 26学习笔记,内容来源于极客时间《透视 HTTP 协议》。