二叉排序树
二叉排序树定义及性质
二叉排序树(Binary Sort Tre)或者是一棵空树,或者是具有如下性质的二叉树:
(1) 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 它的左右子树也分别为二叉排序树。
简单来说,二叉排序树是指根结点大于左子树,小于右子树的二叉树。
根据使用目的,二叉排序树也常被称为二叉查找树、二叉搜索树。
二叉排序树的存储结构
二叉排序树存储结构与二叉树的存储结构一致,常见的存储方式有两种:顺序存储结构、链式存储结构。在实际开发中,链式存储结构是使用最多的。这里重点介绍下链式存储结构。
链式存储结构
不同的存储结构可构成不同形式的链式存储结构。二叉排序树的链式存储结构与二叉树的链式存储结构一致。由二叉树的定义可知,二叉树的结点由一个数据元素和分别指向左右子树的两个分支构成。有时,为了便于查找结点的双亲,还会增加一个指向其双亲结点的指针域。对应存储形式如下图所示:
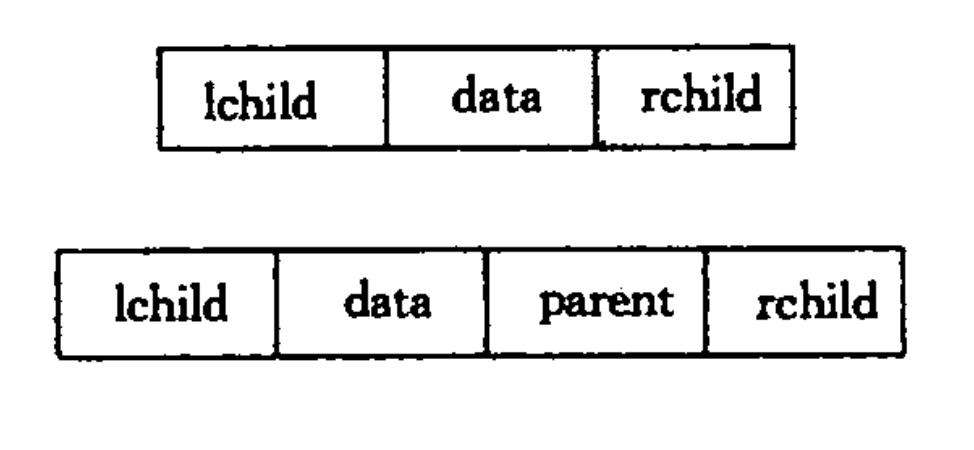
二叉排序树的操作
同一种操作,不同的存储结构,对应不同的实现。本文仅介绍基于链式存储结构的实现。同时,这里仅介绍基本的操作,更多高级的操作可以参考力扣。
二叉排序树的查找
二叉排序树中关键字的查找过程如下:当二叉排序树不空时,首先将给定值的和根结点的关键字比较,若相等,则查找成功,否则将依据给定值和根结点的关键字之间的大小关系,分别在左子树或右子树上继续进行查找。对于二叉链表为存储结构的二叉树来说,其查找算法如下所示:
BiTree SearchBST(BiTree T, KeyType key) {// 在根指针 T 所指二叉排序树中递归地查找某关键字等于key的数据元素,// 若查找成功,则返回指向该数据元素结点的指针,否则返回空指针if((!T) || EQ(key, T->data.key)) {return (T); // 查找结束} else if(LT(key, T->data.key)) {return SearchBST(T->lchild, key); // 在左子树中继续查找} else {return SearchBST(T->rchild, key); // 在右子树中继续查找}
}
接下来考虑该算法的执行效率。含有 n n n个结点的二叉排序树的平均查找长度和树的形态有关。当先后插入的关键字有序时,构成的二叉排序树蜕变成单支树。树的深度为 n n n,其平均查找长度为 ( n + 1 ) / 2 (n+1)/2 (n+1)/2(和顺序查找相同),这是最差的情况。最好的情况则是二叉排序树的形态和折半查找的判定树相同,其平均查找长度和 l o g 2 n log_2 n log2n成正比。接下来分析二叉排序树的平均查找性能。
假设二叉排序树中 n n n个关键字的排列是"随机"的,即任一关键字在序列中将是第1个,或第2个,…,或第 n n n个的概率是相同的,那么平均查找长度 P ( n ) P(n) P(n)可以表示为:
P ( n ) = 1 n ∑ i = 0 n − 1 P ( n , i ) P(n) = \frac{1}{n}\sum_{i=0}^{n-1}P(n, i) P(n)=n1i=0∑n−1P(n,i)
显然, P ( n ) = 0 P(n) = 0 P(n)=0, P ( 1 ) = 1 P(1) = 1 P(1)=1。对于上述公式,当 n > = 2 n>=2 n>=2时,可表示为:
P ( n ) < = 2 ( 1 + 1 n ) l n n P(n) <= 2(1+\frac{1}{n})ln n P(n)<=2(1+n1)lnn
具体化简过程,可参考《数据结构》的9.2.1 二叉排序树和平衡二叉树。
由此可见,在关键字排列随机的情况下,二叉排序树的平均查找长度和 l o g n log n logn是等数量级的。
这里给出基于java的二叉树查找实现:
public TreeNode searchBST(TreeNode root, int val) {if(root == null) {return null;}if(val == root.val) {return root;} else if(val < root.val) {return searchBST(root.left, val);} else {return searchBST(root.right, val);}
}
为了消减递归调用,这里使用循环的方式,给出实现方式。更多使用循环替代递归的通用知识可以参考通用的递归转循环方法一文。
public TreeNode searchBST(TreeNode root, int val) {while (root != null) {if(val == root.val) {break;} else if(val < root.val) {root = root.left;} else {root = root.right;}}return root;
}
更多二叉树查找的实现可以参考力扣。
二叉排序树的插入
一个无序序列可以通过构造一棵二叉排序树而变成一个有序序列,构造树的过程即为对无序序列进行排序的过程。而且每次向二叉排序树上插入新的结点都是二叉排序树上新的叶子节点,所以在进行插入操作时,不必移动其他结点,仅需改动某个结点的指针,由空变为非空即可。这就相当于在一个有序序列上插入一个记录而不需要移动其他记录。这表明二叉排序树既拥有类似折半查找的特性,又采用了链表作为存储结构,因此是动态查找表的一种合适表示。
二叉排序树中关键字的插入过程如下:首先根据给定值查找给定值是否已经存在二叉排序树中,如果存在,则直接返回。否则将结点插入到这棵树种。对于二叉链表为存储结构的二叉树来说,其插入算法如下所示:
Status SearchBST(BiTree T, keyType key, BiTree f, BiTree &p) {// 在根指针T所指二叉排序树中递归地查找器关键字等于key的数据元素,若查找成功,// 则指针p指向该数据元素节点,并返回TRUE,否则指针p指向查找路径上访问的最后一个结点// 并返回FALSE,指针f指向T的双亲,其初始调用值为 NULLif(!T) {p = f;return FALSE;} else if(EQ(key, T->data.key)) {p = T;return TRUE;} else if(LT(key, T->data.key)) {return SearchBST(T->lchild, key, T, p);} else {return SearchBST(T->rchild, key, T, p);}
}Status InsertBST(BiTree &T, ElemType e) { // 当二叉排序树T 中不存在关键字等于e.key的数据元素,插入e并返回TRUE,// 否则返回FALSEif(!SearchBST(T, e.key, NULL, p)) {s = (BiTree) malloc(sizeof(BiTNode));s->data = e;s->lchild = NULL;s->rchild = NULL;if(!p) {T = s;} else if(LT(e.key, p->data.key)) {p->lchild = s;} else {p->rchild = s; }} else {return FALSE;}
}
接下来考虑该算法的执行效率。分析其伪代码实现可知,插入数据依赖查找其待插入位置,所以每次插入的时间复杂度和查找的时间复杂度相同,也为 l o g n log n logn。
因为Java语言无法使用指针,这里给出基于Java语言的的二叉排序树插入实现时假定待插入数据一定不存在:
public TreeNode insertIntoBST(TreeNode root, int val) {if(root == null) {return new TreeNode(val);}if(root.val > val) {root.left = insertIntoBST(root.left, val);} else {root.right = insertIntoBST(root.right, val);}return root;
}
更多二叉树插入的实现可以参考力扣。
二叉排序树的删除
对于一般的二叉树来说,删除树中的一个结点是没有意义的。因为这将使被删除结点为根的子树成为森林,破坏了整棵树的结构。然而,对于二叉排序树来说,删去树上一个结点相当于删去有序序列中的一个记录,只要在删除某个结点之后依旧保持二叉排序树的性质即可。
那么,如何在二叉排序树上删去一个结点呢?假设在二叉排序树上被删除结点为*p(指向结点的指针为p),其双亲结点为*f(结点指针为f),且不失一般性,可设的左孩子。那么可以分以下三种情况进行讨论:
(1) 若*p结点为叶子节点,即 P L P_L PL和 P R P_R PR均为空树。由于删除叶子结点不破坏整棵树的结构,则只需修改其双亲结点的指针即可。
(2) 若*p结点只有左子树 P L P_L PL或者只有右子树 P R P_R PR,此时只要令 P L P_L PL或者 P R P_R PR直接成为其双亲结点*f的左子树即可。显然,作此修改也不破坏二叉排序树的性质。
(3) 若*p结点的左子树和右子树均不空,此时不能如上简单处理。在删去*p之后,为保持其他元素之间的相对位置不变,可以有两种做法:其一是令*p的左子树为*f的左子树,而*p的右子树为其直接前驱或直接后继的右子树。其二是令*p的直接前驱(或直接后继)替代*p,然后从二叉排序树中删去那个直接前驱(或直接后继)。
其删除算法如下所示:
Status DeleteBST(BiTree &T, KeyType key) {// 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素节点,// 并返回TRUE,否则返回FALSEif(!T) { return FALSE;}if(EQ(key, T->data.key)) {return Delete(T);} else if(LT(key, T->data.key)) {return DeleteBST(T->lchild, key);} else {return DeleteBST(T->rchild, key);}
}Status Delete(BiTree &p) {// 从二叉排序树中删除结点p,并重接它的左子树或右子树if(!p->rchild) { // 右子树为空,则只需重接其左子树q = p;p = p->lchild;free(q);} else if(!p->lchild) { // 左子树为空,则只需重接其右子树q = p;p = p->rchild;free(q);} else { // 左子树和右子树均不为空q = p;s = p -> lchild;while(s->rchild) { // 转左,然后向右到尽头q = s;s = s->rchild;}p->data = s-> data; // s指向被删除结点的前驱if(q != p) { // 重接*q的右子树q->rchild = s->lchild;}else { // 重接*q的左子树q->lchild = s->lchild;}delete s;}return TRUE;
}
接下来考虑该算法的执行效率。分析其伪代码实现可知,删除数据前需要先查找到待删除结点,然后移动相关结点,所以每次删除的时间复杂度和查找的时间复杂度相同,也为 l o g n log n logn。
这里给出基于Java语言的的二叉排序树删除实现:
public TreeNode deleteNode(TreeNode root, int key) {if(root == null) {return null;}if(root.val == key) {root = delete(root);}else if(root.val > key) {root.left = deleteNode(root.left, key);} else {root.right = deleteNode(root.right, key);}return root;
}private TreeNode delete(TreeNode root) {if (root.left == null && root.right == null) {return null;}if (root.right == null) {return root.left;}if (root.left == null) {return root.right;}TreeNode successor = root.right;while (successor.left != null) {successor = successor.left;}root.right = deleteNode(root.right, successor.val);successor.right = root.right;successor.left = root.left;return successor;
}
更多二叉树删除的实现可以参考力扣。
参考
《数据结构》 严蔚敏 吴伟民 著 9.2.1 二叉排序树和平衡二叉树
https://blog.csdn.net/L_T_W_Y/article/details/108407686 数据结构——二叉搜索树详解
https://leetcode.cn/tag/binary-search-tree/problemset/ 二叉搜索树
https://leetcode.cn/problems/search-in-a-binary-search-tree/description/ 700. 二叉搜索树中的搜索
https://leetcode.cn/problems/insert-into-a-binary-search-tree/description/ 701. 二叉搜索树中的插入操作
https://leetcode.cn/problems/delete-node-in-a-bst/description/ 450. 删除二叉搜索树中的节点
https://blog.csdn.net/COCO56/article/details/96971844 markdown 数学公式 累加、连乘与乘号的代码
https://blog.csdn.net/qq_43444349/article/details/105400052 全面整理Typora的Latex数学公式语法