优化改进 | YOLOv2算法超详细解析(包括诞生背景+论文解析+技术原理等)

前言:Hello大家好,我是小哥谈。YOLOv2是YOLO(You Only Look Once)目标检测算法的第二个版本,它在YOLOv1的基础上做了很多改进,包括使用更深的卷积神经网络Darknet-19作为特征提取器、使用Batch Normalization、使用锚盒(Anchor Box)等技术来提高准确性和速度。此外,YOLOv2还提出了一种分类和检测的联合训练策略,可以检测超过9000个类别的物体(故又称YOLO9000)。总的来说,YOLOv2在准确性、速度和识别种类方面都有很大的提升。本节课就给大家重点介绍下YOLO系列算法中的YOLOv2!🌈
目录
🚀1.诞生背景
🚀2.论文发表
🚀3.技术原理
💥💥3.1 网络结构
💥💥3.2 训练策略
🚀4.性能评价

🚀1.诞生背景
2017年,作者Joseph Redmon和Ali Farhadi在YOLOv1的基础上,进行了大量改进,提出了YOLOv2 ,重点解决YOLOv1召回率和定位精度方面的不足。YOLOv2 是一个先进的目标检测算法,比其它的检测器检测速度更快。除此之外,该网络可以适应多种尺寸的图片输入,并且能在检测精度和速度之间进行很好的权衡。相比于YOLOv1是利用全连接层直接预测Bounding Box的坐标,YOLOv2借鉴了Faster R-CNN的思想,引入Anchor机制。利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率。同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
作者动机:♨️♨️♨️
1.YOLOv1 速度还是不够快,更换了分类的网络结构。
2.YOLOv1 能检测的物体的种类不够多,提出的YOLO9000利用了分类的数据库使得能检测9000种物体。
3.YOLOv1 召回率低,利用了anchor box解决同一个bonding box 只能检测同一类物体的问题。
YOLOv1和YOLOv2是两个不同版本的目标检测模型。它们之间的区别总结如下:
-
网络架构:YOLOv1使用一个单一的卷积神经网络(CNN)来同时预测边界框和类别,而YOLOv2采用了Darknet-19作为主干网络,并在其之上添加了额外的卷积层和特征金字塔网络。
-
特征提取:YOLOv1在最后一层使用全连接层来生成预测,而YOLOv2在特征图上进行多尺度预测。这种多尺度预测使得YOLOv2能够更好地捕捉不同尺度的目标。
-
Anchor Boxes:YOLOv2引入了锚框(anchor boxes)的概念,通过在每个单元格上定义多个先验框,来预测不同尺度和长宽比的目标。这种方法使得YOLOv2能够更好地处理不同形状和大小的目标。
-
损失函数:YOLOv1使用平方误差来计算边界框坐标和类别的损失,而YOLOv2采用了适应性权重的交叉熵损失函数,以更好地处理类别不平衡问题。
-
训练策略:YOLOv2使用了分步训练策略。首先,使用较大的输入图像进行预训练,然后再用较小的输入图像进行微调。这种策略在提高模型性能的同时,还能提高模型的速度。
🚀2.论文发表
YOLOv2是一篇由Joseph Redmon和Ali Farhadi于2016年发表的目标检测论文。该论文提出了一种新的目标检测算法,可以更快地在各种图像尺寸下运行,并且可以检测9000种以上的目标类别。YOLOv2使用了锚框,这是YOLOv1没有使用的技术。此外,该论文还提出了一种新的网络结构,称为Darknet-19,可以在不损失准确性的情况下减少模型大小和计算量。YOLOv2的性能比YOLOv1有了显著的提升,成为了当时最先进的目标检测算法之一。

说明:♨️♨️♨️
论文题目:《YOLO9000: Better, Faster, Stronger》
论文地址: https://arxiv.org/abs/1612.08242
说明:♨️♨️♨️
关于YOLOv2论文的详细解析,请参考文章:
优化改进 | YOLOv2论文介绍及翻译(纯中文版)
🚀3.技术原理
💥💥3.1 网络结构
YOLOv2 采用 Darknet-19 作为特征提取网络,其整体结构如下:
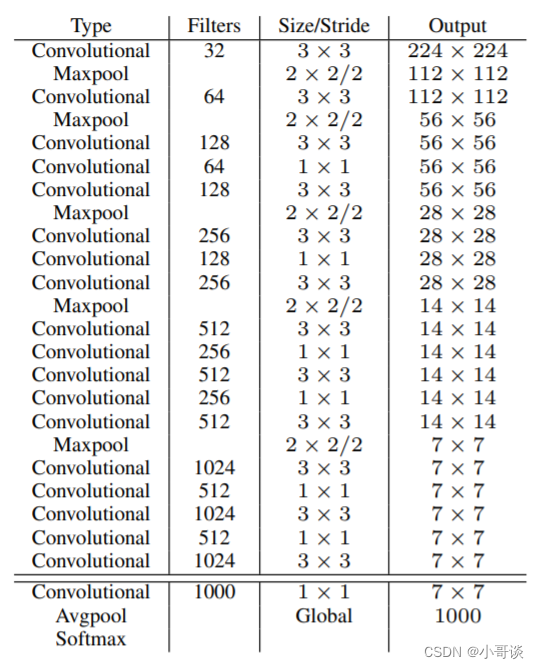
该网络结构的主要优势在于:
- 没有全连接层,可以输入任意尺寸的图片。
- 速度快,每2个卷积层之间用了1x1的卷积核来压缩模型。最后没用全链接层, 而是利用了avgpool。速度提升了。
- 特点:每次pool尺寸减半,通道增加 一倍。
改进后的YOLOv2: Darknet-19,总结如下:
- 与VGG相似,使用了很多3×3卷积核;并且每一次池化后,下一层的卷积核的通道数 = 池化输出的通道 × 2。
- 在每一层卷积后,都增加了批量标准化(Batch Normalization)进行预处理。
- 采用了降维的思想,把1×1的卷积置于3×3之间,用来压缩特征。
- 在网络最后的输出增加了一个global average pooling层。
- 整体上采用了19个卷积层,5个池化层。
💥💥3.2 训练策略
YOLOv2的训练策略主要包括以下几个步骤:
-
数据准备:首先需要准备训练数据集,包括图像和标注信息。标注信息通常包括物体的类别和边界框的位置。
-
网络初始化:使用预训练的卷积网络(如Darknet-19)作为特征提取器,然后添加额外的卷积层和全连接层来预测边界框的位置和类别。
-
损失函数:定义损失函数来度量预测和真实标注之间的差异。YOLOv2使用多任务损失函数,包括分类损失、边界框坐标损失和置信度损失。
-
训练过程:使用随机梯度下降(SGD)或其他相似的优化算法来最小化损失函数。在每个训练批次中,随机选择一批图像,并通过前向传播计算预测结果。然后使用反向传播更新网络参数。
-
数据增强:为了增加训练样本的多样性和鲁棒性,可以采用数据增强技术,如随机缩放、随机裁剪、随机旋转等。
-
迭代训练:重复执行步骤4和步骤5,直到达到预定的训练轮数或收敛条件。
-
推理阶段:在训练完成后,可以使用训练好的模型对新的图像进行目标检测。
🚀4.性能评价
🍀(1)优点
- 结果:相对v1 (更快、mAP更高)
- 正负样本:引入Anchor和使用K-means聚类,提高了Recall。
- Backbone:DarkNet-19,降低了计算量(更快)。
- Neck:引入特征融合模块(passthrouch),融合细粒度特征。
- 检测头:多尺度训练提高模型能力,实现了速度和精度的权衡。
- 小技巧:引入BN,加速网络收敛;约束输出范围,训练更稳定;
🍀(2)缺点
- Backbone 可持续优化。
- Neck 可持续优化。
- 只是单个检测头,小目标识别还不太好。
- 损失函数可持续优化
