大数据技术学习笔记(二)—— Hadoop 运行环境的搭建
目录
- 1 准备模版虚拟机hadoop100
- 1.1 修改主机名
- 1.2 修改hosts文件
- 1.3 修改IP地址
- 1.3.1 查看网络IP和网关
- 1.3.2 修改IP地址
- 1.4 关闭防火墙
- 1.5 创建普通用户
- 1.6 创建所需目录
- 1.7 卸载虚拟机自带的open JDK
- 1.8 重启虚拟机
- 2 克隆虚拟机
- 3 在hadoop101上安装JDK
- 3.1 传输安装包并解压
- 3.2 配置JDK环境变量
- 3.3 测试JDK是否安装成功
- 4 在hadoop101上安装Hadoop
- 4.1 解压安装包
- 4.2 配置Hadoop环境变量
- 4.3 测试Hadoop是否安装成功
笔者使用镜像为:
CentOS-7.5-x86_64-DVD-1804.iso
1 准备模版虚拟机hadoop100
以 CentOS-7.5-x86-1804为例,安装成功后:
1.1 修改主机名
查看当前主机名
hostname
修改当前主机名
vim /etc/hostname
修改主机名为 hadoop100
1.2 修改hosts文件
- 修改linux的主机映射文件(hosts文件)
编辑 /etc/hosts
vim /etc/hosts
添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
- 修改windows的主机映射文件(hosts文件)
进入C:\Windows\System32\drivers\etc 路径,打开hosts文件并添加如下内容
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
1.3 修改IP地址
1.3.1 查看网络IP和网关
查看虚拟网络编辑器
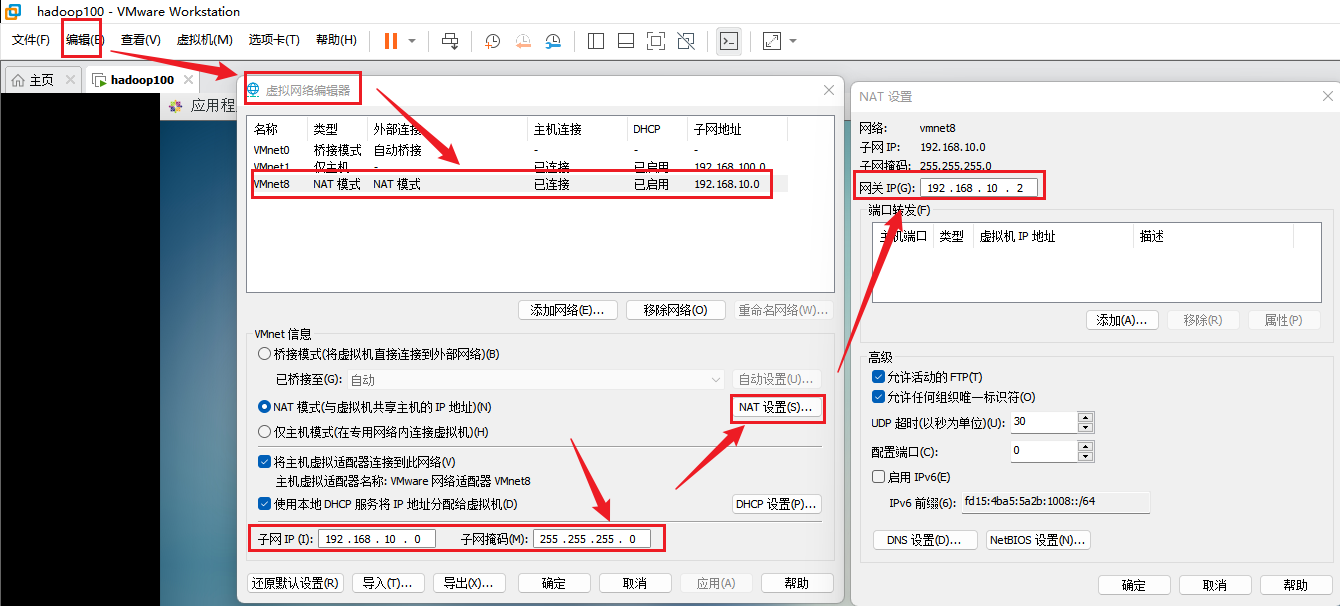
查看windows环境的中VMnet8网络配置

1.3.2 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
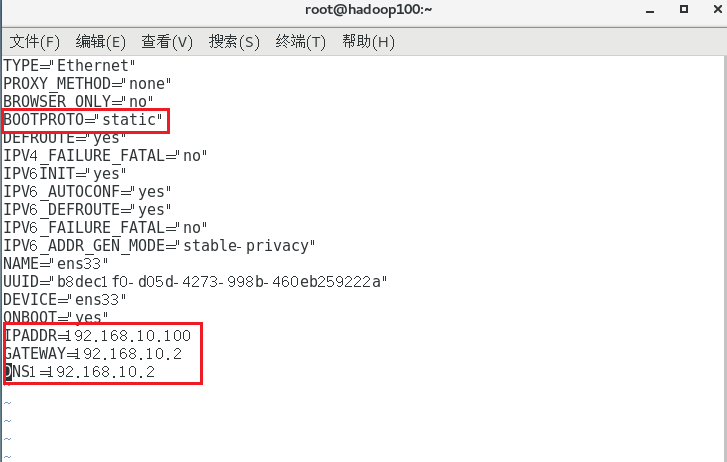
编辑完后,按键盘esc ,然后输入 :wq 回车即可。
重启网络
systemctl restart network
查看修改后的IP
ifconfig
或者
ip addr
1.4 关闭防火墙
关闭防火墙,并关闭防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld
1.5 创建普通用户
创建普通用户huwei
useradd huwei
修改普通用户huwei的密码
passwd huwei
配置 huwei 用户具有 root 权限,方便后期加 sudo 执行 root 权限的命令
vim /etc/sudoers
esc,键入:set nu显示行号,找到91行,在 root 下面添加一行
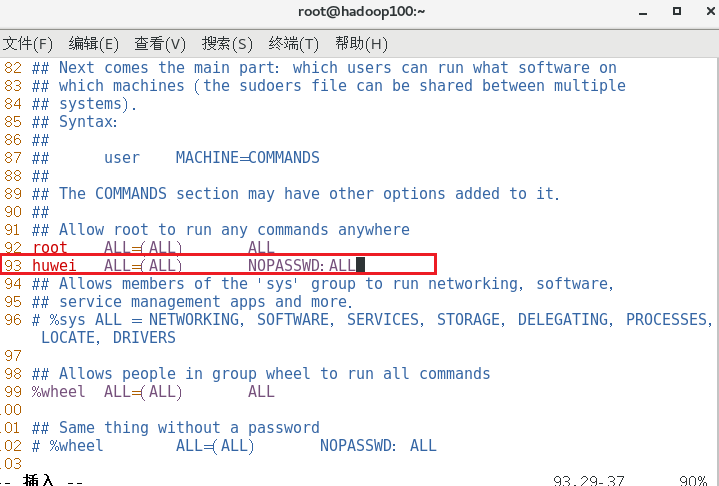
esc,对该只读文件保存强制退出:wq!
1.6 创建所需目录
在 /opt 目录下创建 module、software 文件夹
mkdir /opt/module
mkdir /opt/software
修改 module、software 文件夹的所有者和所属组均为 huwei 用户
chown huwei:huwei /opt/module
chown huwei:huwei /opt/software
查看module、software文件夹的所有者和所属组
cd /opt/
ll

1.7 卸载虚拟机自带的open JDK
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
1.8 重启虚拟机
reboot
2 克隆虚拟机
利用模板机 hadoop100,克隆三台虚拟机:hadoop101 、hadoop102、hadoop103
然后修改克隆机IP,以下以 hadoop101 举例说明。
修改IP地址,只需改 IPADDR=192.168.10.101
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改主机名为 hadoop101
vim /etc/hostname
重启!
暂时不考虑克隆 hadoop102、hadoop103
3 在hadoop101上安装JDK
3.1 传输安装包并解压
将 hadoop 和 jdk 通过传输工具上传到 /opt/software
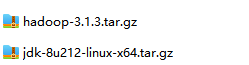
切换到 /opt/software目录下,解压 jdk到 /opt/module目录下
cd /opt/software
tar -zxvf jdk-8u212-linux-x64.tar.gz -C ../module/
3.2 配置JDK环境变量
新建 /etc/profile.d/jdk.sh文件
sudo vim /etc/profile.d/my_env.sh
添加如下内容
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
source /etc/profile
3.3 测试JDK是否安装成功
java -version

如果能看到以上结果,则代表 Java 安装成功!
4 在hadoop101上安装Hadoop
4.1 解压安装包
切换到 /opt/software目录下,解压 jdk到 /opt/module目录下
cd /opt/software
tar -zxvf hadoop-3.1.3.tar.gz -C ../module/
查看Hadoop目录结构
cd /opt/module/hadoop-3.1.3/
ll
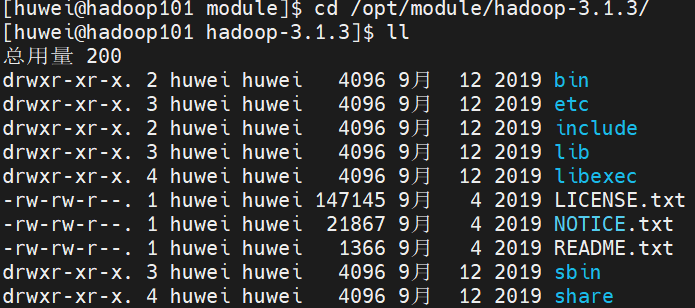
重要目录
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例
4.2 配置Hadoop环境变量
编辑 /etc/profile.d/jdk.sh文件
sudo vim /etc/profile.d/my_env.sh
添加如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使环境变量生效
source /etc/profile
4.3 测试Hadoop是否安装成功
hadoop version

如果能看到以上结果,则代表 Hadoop 安装成功!