交通 | 实现可泛化性:机器学习求解VRP

推文作者:缪昌昊,张景琪,张云天
论文作者:Jieyi Bi, Yining Ma, Jiahai Wang, Zhiguang Cao, Jinbiao Chen, Yuan Sun, and Yeow Meng Chee
论文原文:Bi, Jieyi, et al. “Learning generalizable models for vehicle routing problems via knowledge distillation.” Advances in Neural Information Processing Systems 35 (2022): 31226-31238.
论文代码:https://github.com/jieyibi/AMDKD
摘要:
近年来,用于求解车辆路径规划问题(Vehicle Routing Problem, VRP)的神经网络方法通常在相同的实例分布上对深度模型进行训练和测试(即均匀分布)。为了解决跨分布泛化问题,作者引入了知识蒸馏到这个领域,并提出了一种自适应多分布知识蒸馏(Adaptive Multi-Distribution Knowledge Distillation,AMDKD)方案,用于学习泛化能力更强的深度模型。AMDKD首先训练了提供分布知识的教师模型,而后将教师模型输出的知识(分布)作为学生模型的监督信息,训练学生模型。与此同时,作者为AMDKD配备了一种自适应策略,允许学生集中精力处理困难的分布,以更有效地吸收难以掌握的知识。AMDKD首先训练了提供分布知识的教师模型,而后将教师模型输出的知识(分布)作为学生模型的监督信息,训练学生模型。
大量的实验证明,与基线的神经网络方法相比,AMDKD在未见过的同一分布和不同分布实例上都能取得出色的结果,这些实例可以是随机合成的,也可以是从基准数据集(即TSPLIB和CVRPLIB)中选取的。值得注意的是,作者提出的AMDKD具有通用性,且在推断时消耗更少的计算资源。
1. 背景
**车辆路径规划问题是一个NP-hard的组合优化问题,其具有广泛的实际应用,例如货物配送、末端物流和网约车服务等。**几十年来,该问题在计算机科学和运筹学领域得到了深入研究,且提出了许多精确和(近似)启发式算法。在实践中,尽管人们通常更喜欢使用计算效率相对较高的启发式算法,但是这些算法往往依赖于手工设计的规则和领域知识,且仍有改进的空间。近年来,深度(强化)学习作为一种有前景的替代方案,已经引起了广泛关注,它可以被用来以端到端的方式自动学习VRP的启发式(或策略)。与传统方法相比,基于深度模型的启发式学习方法可以进一步降低计算成本,同时保证理想的解决方案。
然而,现有的深度模型在不同的节点坐标分布上存在泛化性能较差的问题。具体而言,它们通常在相同分布的实例上对神经网络进行训练和测试,其主要是均匀分布。相比于传统的启发式算法,深度模型能够更有效地获得出色的结果。然而,当利用学习得到的策略对分布外(Out-of-Distribution)的实例进行推断时,求解结果的质量通常较低。这种跨分布的泛化问题不可避免地阻碍了深度模型的应用,特别是因为现实世界中的VRP实例可能遵循不同甚至未知的分布。
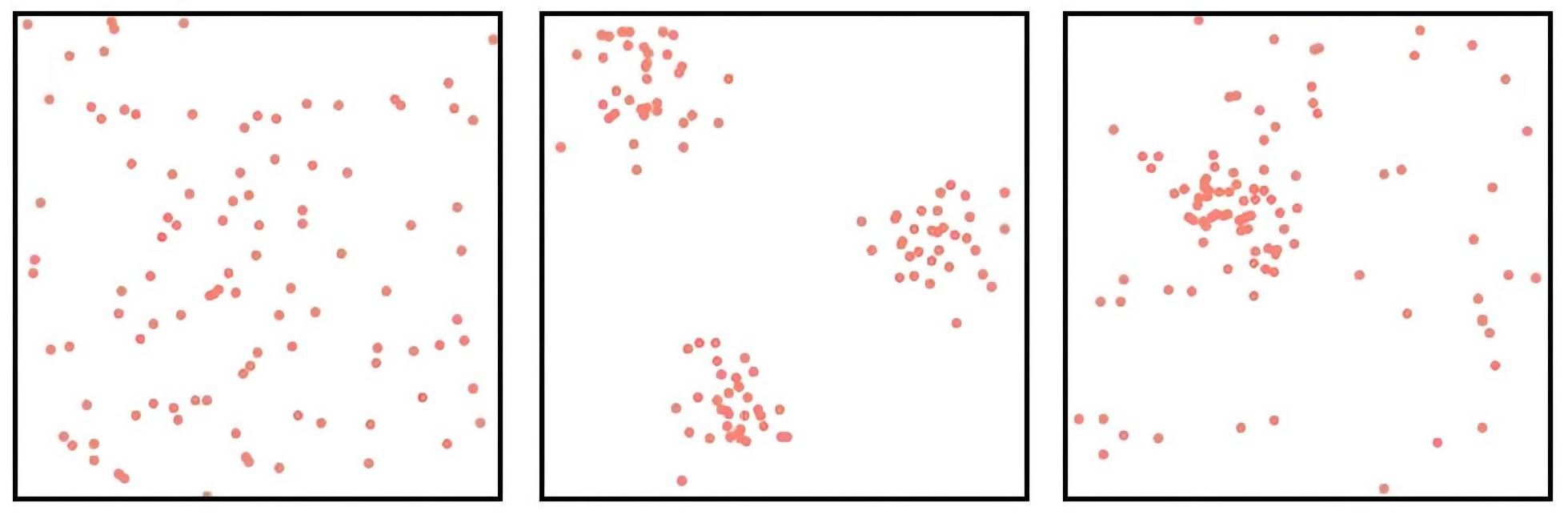
图1:不同的VRP实例分布。自左至右分别为均匀分布(Uniform)、簇状分布(Cluster)和二者的混合分布(Mixed)
如今,对于VRP中的泛化问题,人们主要利用(自动)数据增强和分布鲁棒优化的方法进行了一些初步的尝试。然而,在作者看来,这些方法并不是最佳选择。数据增强方法通常从指定的单一分布开始,这可能会对结果的质量有所限制。分布鲁棒优化方法需要手动定义主要和次要实例。与上述两种方法不同的是,在本文中,作者旨在通过将从不同分布中学到的各种策略转移到一个分布中来增强跨分布的泛化性能。作者利用了知识蒸馏技术来学习更具泛化性的VRP模型。
具体而言,**作者提出了一种通用的自适应多分布知识蒸馏(Adaptive Multi-Distribution Knowledge Distillation,AMDKD)方案,用于训练一个具有良好的跨分布泛化性能的轻量级模型。**为了传授广泛且专业的知识,作者利用了多个在各自示范分布上(预)训练过的教师模型。AMDKD利用这些教师模型轮流对一个学生模型进行训练,其灵感来自人类的学习范式。同时,作者还为AMDKD配备了一个自适应策略,用于追踪学生模型在每个示范分布上的实时学习表现,这使得学生能够集中精力吸收难以掌握的知识,以增强学习的有效性。
2. 模型构建
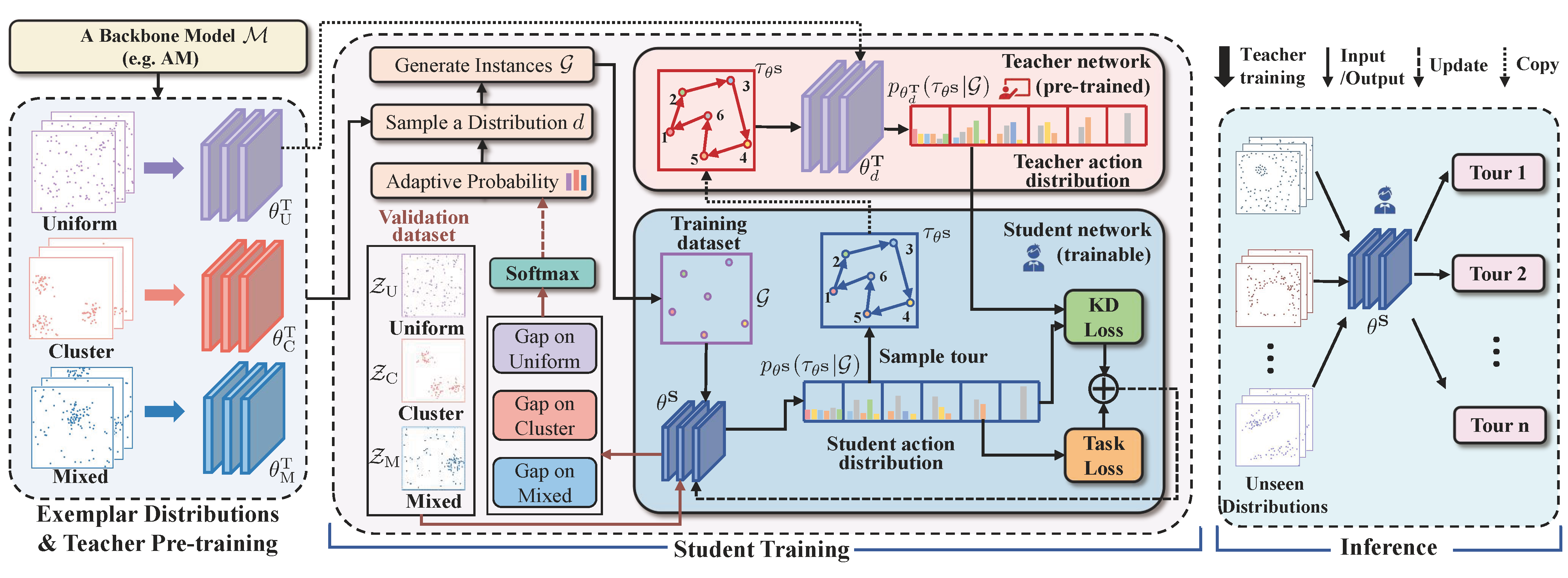
图2:AMDKD框架自左至右分为三个阶段:教师预训练、学生训练和推断。图中选择了均匀分布作为当前示范分布的示例。
在先前的研究中,深度模型通常是在单一分布上进行训练的。近年来,人们开始尝试通过增加非典型(次要)或困难实例来扩充训练数据。与这些方法不同,AMDKD通过知识蒸馏方法将不同分布下的专家知识传递到同一个模型中。由于其轻量级网络和高速推断的特点,生成的模型在性能上会优于现有的方法。此外,AMDKD是通用的,可以对各种VRP深度模型进行增强。
下面将对AMDKD算法的整体结构、教师(预)训练和自适应多分布学生训练进行详细介绍。
2.1 整体结构和教师(预)训练
AMDKD的总体框架如图2所示。给定一个现有的深度模型,AMDKD首先对教师模型进行训练(或直接使用预训练的教师模型),以获得示范分布所对应的教师模型。之后,在每个知识传递周期中,AMDKD选择一个特定分布 d d d及其对应的教师模型 θ d T \theta_d^T θdT来训练一个学生网络。为了促进学习的有效性,选择每个分布的概率会根据学生在验证数据集上的表现实时调整。最后,AMDKD进行基于策略的蒸馏,允许学生网络 θ S \theta^S θS对强化学习轨迹路径 { τ θ S } \{\tau_{\theta^S}\} {τθS}进行采样训练,并计算两个损失函数(知识蒸馏损失和任务损失)以进行更新。
在本文中,作者将均匀分布(Uniform)、簇状分布(Cluster)和二者的混合分布(Mixed)作为示范分布,用于训练教师网络。因此,针对每个分布可以得到一组经过良好训练的教师模型参数 θ T = { θ U T , θ C T , θ M T } \theta^T=\{\theta_U^T,\theta_C^T,\theta_M^T\} θT={θUT,θCT,θMT}。尽管在整个训练过程中只使用了有限个数的分布,但作者期望学习得到的学生网络能够从这些教师吸收到通用且鲁棒的知识,从而能够有效地泛化到未见过的分布。作者希望每个教师只需要掌握特定的分布,通过与蒸馏方案共同协作,即可以训练出一个通用的学生模型。需要注意的是,这里使用的示范分布也可以被其他分布替代。此外,由于作者设计的蒸馏方案与特定模型无关,因此教师网络可以遵循大多数现有的架构。为了对AMDKD进行评估,作者将AMDKD应用于两种具有代表性的VRP构建型求解方法:AM和POMO。
2.2 自适应多分布学生训练
在AMDKD方案中,基于给定的示范分布可以获得训练好的教师模型。在每个知识传递周期中,AMDKD学生选择一个分布及其对应的教师模型,并逐渐学习如何做出适当的决策。需要注意的是,还有另一类研究认为在蒸馏过程中同时应当使用多个教师,通过所有教师参与以提供加权损失的方法来训练学生。然而,这种设计可能需要通过监督学习对同质任务进行训练,这与使用强化学习处理异构分布的需求不符。
学生网络
作者规定学生模型与教师模型具有相似的架构,但可以根据需要减少网络参数以加快推断速度。然而,较大的学生模型通常会拥有更好的性能。因此,在求解质量和计算成本之间需要进行权衡。在本文中,作者考虑将节点嵌入的维度从128(教师模型)降低到64(学生模型),这导致将AMDKD应用于AM和POMO后模型参数分别减少了61.8%和59.2%。同时,作者也考虑了减少编码器层数,但结果低于预期。
自适应多分布蒸馏策略
在每个训练周期中,AMDKD选择一个分布及其相应的教师模型。在开始时,它以相等的概率选择分布。在 E ′ E^\prime E′个周期之后,选择概率将根据学生在给定验证数据集 Z U \mathcal{Z}_U ZU、 Z C \mathcal{Z}_C ZC、 Z M \mathcal{Z}_M ZM上的性能表现进行自适应调整,其中每个数据集包含1000个算例。选择分布 d ∈ { U , C , M } d\in\{U,C,M\} d∈{U,C,M}的概率 p a d a p t i v e p^{adaptive} padaptive与LKH求解器优度Gap的指数成正比。选择概率 p a d a p t i v e p^{adaptive} padaptive的详细定义如下:
p adaptive ( d ) = { Softmax ( AvgGap [ { τ θ S } ∣ Z d , { τ solver } ∣ Z d ] ) , if E ≥ E ′ 1 ∣ D ∣ , otherwise ( 1 ) p^{\text {adaptive }}(d)=\left\{\begin{array}{cc} \operatorname{Softmax}\left(\operatorname{AvgGap}\left[\left\{\tau_{\theta^S}\right\}|_{\mathcal{Z}_d},\left.\left\{\tau_{\text {solver }}\right\}\right|_{\mathcal{Z}_d}\right]\right), & \text { if } E \geq E^{\prime} \\ \frac{1}{|\mathcal{D}|}, & \text { otherwise } \end{array}\right.\qquad(1) padaptive (d)={Softmax(AvgGap[{τθS}∣Zd,{τsolver }∣Zd]),∣D∣1, if E≥E′ otherwise (1)
其中, ∣ D ∣ |\mathcal{D}| ∣D∣为示范分布的数量, { τ θ S } ∣ Z d \{\tau_{\theta^S}\}|_{\mathcal{Z}_d} {τθS}∣Zd和 { τ s o l v e r } ∣ Z d \{\tau_{solver}\}|_{\mathcal{Z}_d} {τsolver}∣Zd分别代表学生 θ S \theta^S θS和LKH求解器所生成的路径集。验证集是固定的,因此LKH求解器只需要运行一次即可获得分布 d ∈ { U , C , M } d\in\{U,C,M\} d∈{U,C,M}对应的路径集 { τ s o l v e r } ∣ Z d \{\tau_{solver}\}|_{\mathcal{Z}_d} {τsolver}∣Zd。与此同时,作者注意到选择概率 p a d a p t i v e p^{adaptive} padaptive在蒸馏过程中会逐渐收敛,这意味着评估过程可能可以提前终止,并且可以对已经稳定的路径集进行重复利用,以便进行更快的训练。
损失函数
作者利用任务损失 L T a s k \mathcal{L}_{Task} LTask和知识蒸馏损失 L K D \mathcal{L}_{KD} LKD共同对学生进行训练。任务损失 L T a s k \mathcal{L}_{Task} LTask的详细定义如下:
L Task = − J ( θ S ∣ d ) = − E G ∼ d , τ ∼ p θ S ( τ ∣ G ) [ L ( τ ∣ G ) ] ( 2 ) \mathcal{L}_{\text {Task }}=-J\left(\theta^{\mathrm{S}} \mid d\right)=-\mathbb{E}_{\mathcal{G} \sim d, \tau \sim p_{\theta^ \mathrm{S}}(\tau \mid \mathcal{G})}[L(\tau \mid \mathcal{G})]\qquad(2) LTask =−J(θS∣d)=−EG∼d,τ∼pθS(τ∣G)[L(τ∣G)](2)
其中,训练算例 G \mathcal{G} G是从给定分布 d d d中抽样的,路径 τ \tau τ是通过学生网络 θ S \theta^S θS来构建的。AM和POMO中使用了强化学习算法对上述损失函数的梯度进行估计,且作者沿用了他们的原始设计。至于知识蒸馏损失 L K D \mathcal{L}_{KD} LKD,其设计目的是鼓励学生模仿教师网络顺序选择节点的方法。具体而言,对于从分布 d d d中抽样得到的训练算例 G \mathcal{G} G和由学生 θ S \theta^S θS根据自己策略构建的路径 τ θ s \tau_{\theta^s} τθs,作者提出的AMDKD利用教师网络 θ d T \theta^T_d θdT提供的策略 p θ d T ( τ θ S ∣ G ) p_{\theta_d^T}(\tau_{\theta^S}|\mathcal{G}) pθdT(τθS∣G)来计算知识蒸馏损失 L K D \mathcal{L}_{KD} LKD,其使用了KL散度来度量教师和学生之间概率分布的相似性。知识蒸馏损失 L K D \mathcal{L}_{KD} LKD的详细定义如下:
L K D = 1 B ∑ i = 1 B ∑ a j ∈ τ θ S p θ d T ( a j ∣ G i ) ( log p θ d T ( a j ∣ G i ) − log p θ S ( a j ∣ G i ) ) ( 3 ) \mathcal{L}_{\mathrm{KD}}=\frac{1}{B} \sum_{i=1}^B \sum_{a_j \in \tau_{\theta^\mathrm{S}}} p_{\theta_d^{\mathrm{T}}}\left(a_j \mid \mathcal{G}_i\right)\left(\log p_{\theta_d^{\mathrm{T}}}\left(a_j \mid \mathcal{G}_i\right)-\log p_{\theta^\mathrm{S}}\left(a_j \mid \mathcal{G}_i\right)\right)\qquad(3) LKD=B1i=1∑Baj∈τθS∑pθdT(aj∣Gi)(logpθdT(aj∣Gi)−logpθS(aj∣Gi))(3)
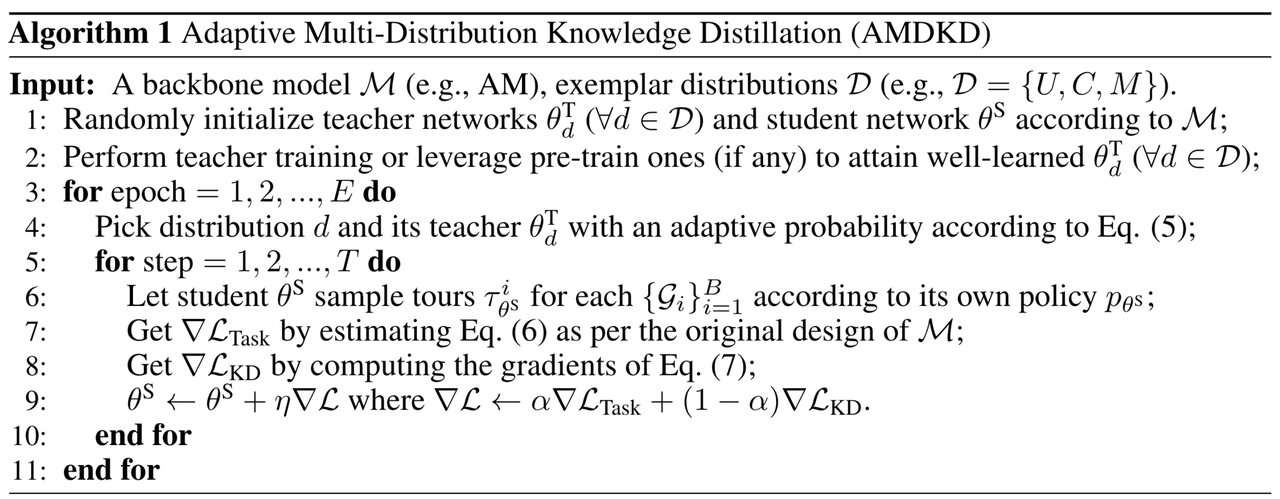
图3:AMDKD算法流程
AMDKD的算法流程如图3所示。需要注意的是,AMDKD采用了on-policy方案,其中路径 τ θ S \tau_{\theta^S} τθS由当前正在学习的学生输出。作为替代方案,这些路径也可以由教师输出(即off-policy方案)。然而,与on-policy方案相比,off-policy方案的性能较差。最后作者指出,由AMDKD学习到的学生模型也可以在推断时与高效主动搜索(EAS)相结合,来进一步提高性能,且AMDKD+EAS的方法达到了目前最好的性能。
3. 实验分析
作者在TSP和CVRP上进行了实验,节点数量分别为20、50和100,与之前的研究类似。正如前面所提到的,作者采用均匀分布(Uniform)、簇状分布(Cluster)和混合分布(Mixed)作为训练的示范分布;而在测试中,作者使用扩张分布(Expansion)、坍塌分布(Implosion)、爆炸分布(Explosion)和网格分布(Grid)作为未见过的分布。所有实验均在NVIDIA RTX 3090 GPU和Intel Xeon Silver 4216 CPU 2.10GHz 的计算机上实现。
论文代码可公开获取:https://github.com/jieyibi/AMDKD
3.1 AMDKD的有效性分析
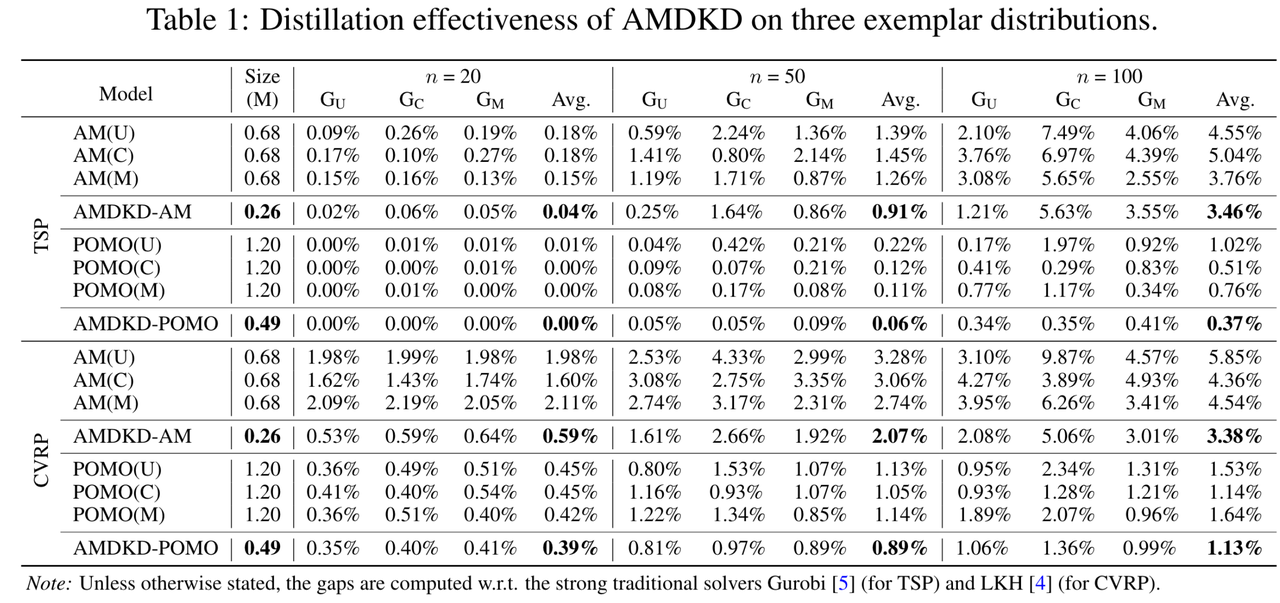 图4:AMDKD在三个示范分布上的蒸馏有效性
图4:AMDKD在三个示范分布上的蒸馏有效性
对于TSP和CVRP而言,作者首先研究了AMDKD应用于AM和POMO时的有效性。在图4中,作者展示了学习得到的学生模型与它们各自的教师模型在未见过的实例上的优度Gap,这些实例是根据三个示范分布(分别标记为 G U G_U GU、 G C G_C GC和 G M G_M GM)生成的,并且展示了每个模型的参数大小。可以看到,当教师模型在特定分布上进行训练时,它在其他分布上的泛化效果不佳(尤其是AM模型),导致整体性能较差。相比之下,AMDKD能够有效地缓解这个问题。虽然AMDKD学习得到的学生模型将AM的教师模型参数大小从0.68M降低到0.26M(减小了61.8%),将POMO的教师模型大小从1.20M降低到0.49M(减小了59.2%),但它在所有三种规模上的整体性能仍有提升。对于AMDKD-AM而言,AMDKD的学生模型不仅在TSP和CVRP中明显优于其三个教师模型,而且在大多数情况下,它在教师模型先前训练过的分布上有更小的Gap。对于AMDKD-POMO而言,尽管POMO本身具有更好的泛化性能,但无论是在TSP还是CVRP上,AMDKD仍然可以通过更轻量级的学生网络来提高整体性能。以上结果验证了AMDKD不会过分拟合单一分布,并且经过多个在不同示范分布上具有专业知识的教师的指导,能够成功学习得到一个轻量且通用的学生模型。
3.2 AMDKD的泛化性分析
作者对AMDKD的跨分布泛化性能进行了评估分析。除了AM与POMO模型外,作者还与以下方法进行比较:
(1) 其他深度模型,包括DACT、LCP
(2)专门用于泛化的其他方法,包括HAC、DROP、GANCO和PSRO(又称LIH)
因为DROP、GANCO和PSRO并没有开源,作者只比较了它们在原论文中展示的几个基准实例上的结果(见图6)。
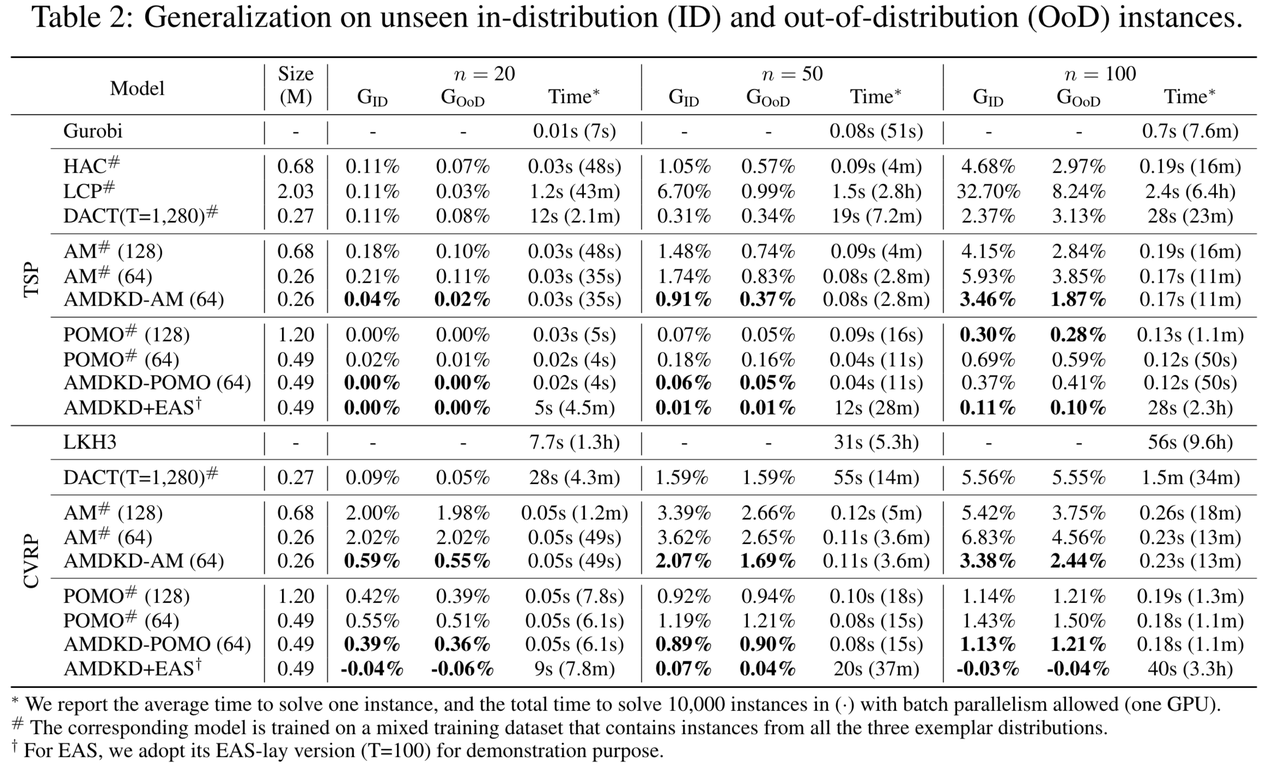
图5:AMDKD对ID和OoD算例的泛化性能分析
鉴于基线模型AM、POMO、DACT和LCP最初只在均匀分布上进行了训练,作者在三个示范分布的混合数据集上对上述模型进行了重新训练(用#标记)。同时,作者也将这个混合数据集用作HAC的初始训练实例(用#标记)。尽管这提高了POMO和AM在较大规模实例上的泛化性能,但情况并不总是如此,特别是对于具有改进组件的方法(例如DACT和LCP)。此外,对于 A M # AM^\# AM#和 P O M O # POMO^\# POMO#,作者分别展示了网络维度为128和64时的性能(与AMDKD学生的维度相同),以进行更全面的比较。
作者评估了以下指标:(1)参数大小;(2)未见过的同一分布实例的平均Gap,即 G I D G_{ID} GID;(3)未见过的不同分布实例的平均Gap,即 G O o D G_{OoD} GOoD;(4)求解单个实例的平均时间,以及批量并行处理解决10000个实例所需的总时间(单个GPU)。
从图5可以看出,作者的AMDKD在未见过的同一分布和不同分布实例上均取得了出色的结果,并且在所有基线模型上均表现优异。对于TSP而言,AMDKD-AM(64)在 G I D G_{ID} GID和 G O o D G_{OoD} GOoD的所有规模上都明显优于基线 A M # AM^\# AM#(128)和 A M # AM^\# AM#(64),而且参数更少,推断速度更快。与此同时,它在优度Gap和时间效率上始终优于 H A C # HAC^\# HAC#。对于POMO而言,基线 P O M O # POMO^\# POMO#(128)已经能够在TSP实例上获得接近最优解的解,并具有良好的泛化性能。然而,AMDKD(64)在保证良好的泛化性能的同时,网络维度仅为其一半且推断速度更快。当作者将 P O M O # POMO^\# POMO#的网络维度降低到64(与AMDKD相同)时, P O M O # POMO^\# POMO#(64)在性能上远远低于AMDKD-POMO(64)。对于CVRP,作者也观察到了类似的现象,AMDKD-AM(64)和AMDKD-POMO(64)对于所有基线模型,均展现出了良好的泛化性能。上述两种方法在推断速度上显著快于改进方法LCP和DACT,且能获得更优解。
此外,作者将AMDKD-POMO(64)模型与最近提出的高效主动搜索(EAS)相结合,并在CVRP-100上取得了非常出色的效果,甚至超过了LKH3,并且所需时间更短。因此,利用主动搜索在推断特定实例时的优势,AMDKD+EAS能使得AMDKD的性能进一步提升。

图6:对TSPLIB和CVRPLIB数据集的泛化性能分析
如图6所示,作者在基准数据集TSPLIB和CVRPLIB上对AMDKD的泛化性能进行了评估。AMDKD-AM(64)显著提高了AM(128)的泛化性能,同时也优于其他基线方法。同样,AMDKD-POMO(64)也明显优于其他基线方法,除了在TSPLIB上的POMO#(128)。相较于所有其他基线算法,AMDKD+EAS在TSP和CVRP上都表现出了最好的性能。
3.3 AMDKD的进一步分析
不同组件的影响
作者在CVRP-50和TSP-50上进行了消融实验,验证了AMDKD的设计,作者分别去除了提出的自适应策略、知识蒸馏损失 L K D \mathcal{L}_{KD} LKD和任务损失 L T a s k \mathcal{L}_{Task} LTask。如图7所示,自适应策略的使用进一步提高了学习效果,而这两种损失在梯度更新阶段发挥了重要作用。同时,作者验证了off-policy与on-policy方案相比,会很大程度削减蒸馏的效果。
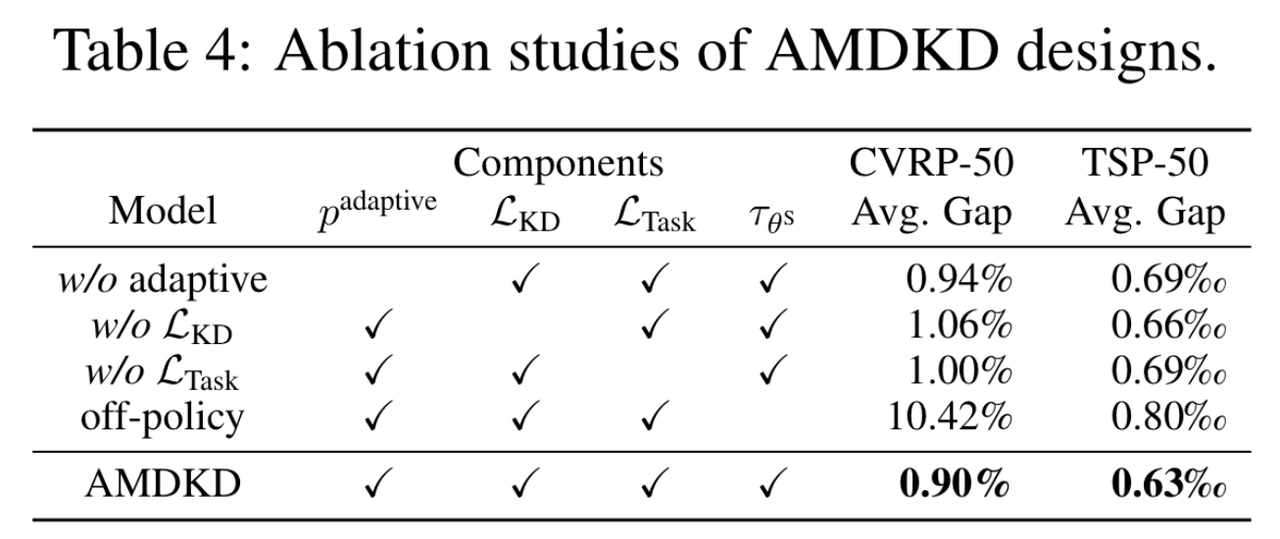
图7:AMDKD的消融实验
学生网络结构的影响
在图8中,作者展示了使用不同学生网络架构(不同网络维度和不同编码器层数)的AMDKD-POMO在求解CVRP-50时的平均优度箱线图。如图所示,模型越大,性能越好。因此,作者认为当学生(64)与其教师(128)使用相同的结构时,AMDKD的性能可以进一步提升。具体而言,对于CVRP-50,AMDKD-POMO(128)的平均Gap为0.81%,低于AMDKD-POMO(64)的0.90%。然而,该优势以三方面计算成本的增加为代价:(1)更多的训练时间;(2)更多的参数;(3)更慢的推断时间。因此,求解性能和计算成本之间需要进行权衡。
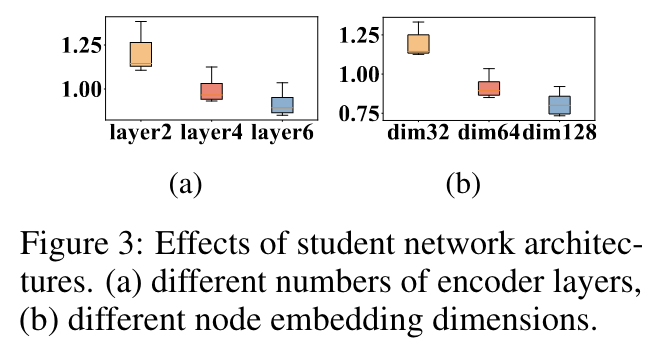
图8:学生网络结构对性能的影响
不同示范分布的影响
作者通过改变示范分布的选择来验证AMDKD的有效性。以POMO和CVRP-50为例,作者将Expansion、Implosion、Explosion和Grid作为示范分布的模型称为AMDKD-POMO*。结果如图9所示,AMDKD-POMO*的整体性能仍然优于在这四个分布上单独训练的POMO。因此,AMDKD在不同的示范分布下均可以对跨分布泛化性能进行改善。
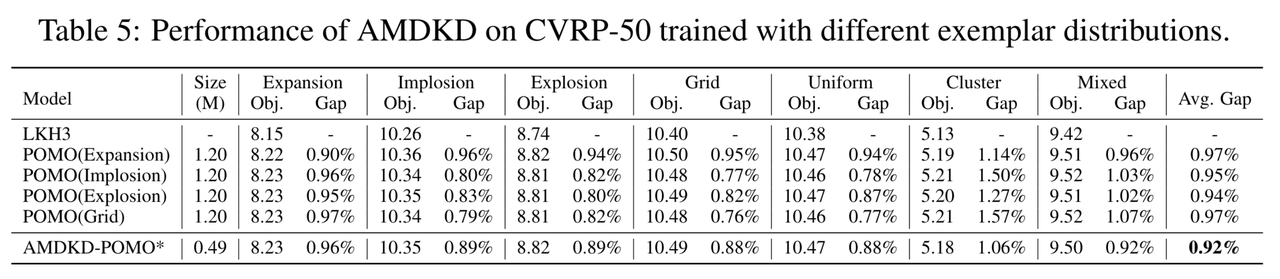
图9:利用不同示范分布训练的AMDKD在CVRP-50上的性能表现
4. 总结
在本文中,作者提出了一种自适应多分布知识蒸馏(AMDKD)方案,以改善VRP的深度模型在不同分布下的泛化问题。与现有的泛化方法不同,作者旨在通过一种高效的知识蒸馏方案,将从示范分布中学到的各种策略转移到同一个分布中,以增强分布泛化性能。为了促进学习的有效性,作者设计了一种自适应策略,即多个教师轮流训练一个学生网络。实验结果显示,AMDKD在推广到其他未见分布的实例时拥有出色的性能,且需要较少的计算资源。
尽管AMDKD是通用的,但它在未见分布上的性能提升并不总是显著。因此,对于未来的研究,作者将会围绕以下方面展开研究:(1)将AMDKD推广到不同/更大规模的问题;(2)考虑将类似DACT这样的改进模型作为主体模型;(3)利用在线蒸馏对教师和学生模型共同训练;(4)评估验证数据集质量对蒸馏的影响;(5)加强AMDKD的可解释性。
参考文献:
Bi, Jieyi, et al. “Learning generalizable models for vehicle routing problems via knowledge distillation.” Advances in Neural Information Processing Systems 35 (2022): 31226-31238.