MapReduce编程:检索特定群体搜索记录和定义分片操作
文章目录
- MapReduce 编程:检索特定群体搜索记录和定义分片操作
- 一、实验目标
- 二、实验要求及注意事项
- 三、实验内容及步骤
- 附:系列文章
MapReduce 编程:检索特定群体搜索记录和定义分片操作
一、实验目标
- 熟悉MapReduce编程涉及的主要类和接口的含义和用法
- 熟练掌握Mapper类,Reducer类和main函数的编写
- 熟练掌握在本地测试方法
- 熟练掌握集群上进行分布式程序测试
二、实验要求及注意事项
- 给出每个实验的主要实验步骤、实现代码和测试效果截图。
- 对本次实验工作进行全面的总结分析。
- 所有程序需要本地测试和集群测试,给出相应截图。
- 建议工程名,类名或包名等做适当修改,显示个人学号或者姓名
三、实验内容及步骤
实验任务1:检索特定偏好用户和群体操作:使用mapreduce编程,读取文本文件sogou.500w.utf8,查找搜索过“仙剑奇侠传”用户的uid,利用mapreduce的特性对uid进行去重并输出,实现效果参考图1。
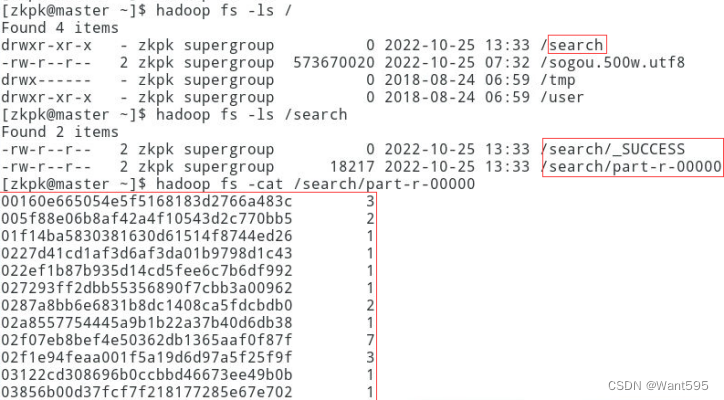
图1 搜索过“仙剑奇侠传”用户的uid及搜索次数输出结果
主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
SearchMap
package hadoop;
import java.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.io.*;public class WjwSearchMap extends Mapper<Object, Text, Text, Text>{public void map(Object key, Text value, Context context) throws IOException,InterruptedException{String arr[] = value.toString().split("\t");if(arr != null && arr.length==6){String uid = arr[1];String keyword = arr[2];if(keyword.indexOf("仙剑奇侠")>=0){context.write(new Text(uid), new Text(keyword));}}}
}
SearchReduce
package hadoop;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import java.io.*;public class WjwSearchReduce extends Reducer<Text, Text, Text, IntWritable>{@SuppressWarnings("unused")protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException{int s=0;for(Text word:values){s++;}context.write(key, new IntWritable(s));}
}
SearchMain
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;@SuppressWarnings("unused")
public class WjwSearchMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IllegalArgumentException,IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input args");}Job job = new Job(new Configuration(), "WjwSearchMain");job.setJarByClass(WjwSearchMain.class);job.setMapperClass(WjwSearchMap.class);job.setReducerClass(WjwSearchReduce.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true)?0:1);}
}
(4)测试程序,并查看输出结果。
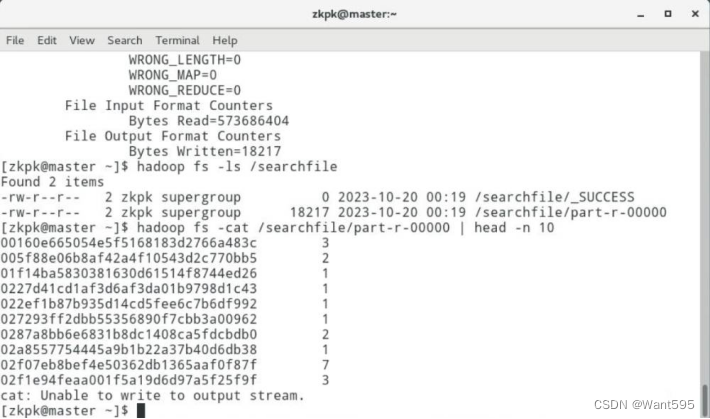
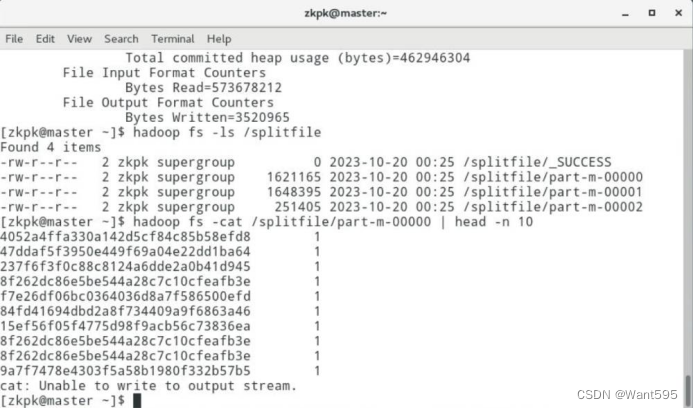
实验任务2:MapReduce自定义分片(Split)操作:使用mapreduce编程,设置mr过程中Map Task读取文件时的split大小。实现效果:

主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
SplitMap
package hadoop;
import java.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.io.*;public class WjwSplitMap extends Mapper<Object, Text, Text, IntWritable>{public void map(Object key, Text value, Context context) throws IOException,InterruptedException{String arr[] = value.toString().split("\t");if(arr != null && arr.length==6){String uid = arr[1];String keyword = arr[2];if(keyword.indexOf("电影")>=0){context.write(new Text(uid), new IntWritable(1));}}}
}
SplitMain
package hadoop;
import java.io.IOException;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.fs.*;@SuppressWarnings("unused")
public class WjwSplitMain {@SuppressWarnings("deprecation")public static void main(String[] args) throws IllegalArgumentException,IOException,ClassNotFoundException,InterruptedException{if(args.length != 2 || args == null){System.out.println("please input args");}Job job = new Job(new Configuration(), "WjwSplitMain");job.setJarByClass(WjwSplitMain.class);job.setMapperClass(WjwSplitMap.class);job.setNumReduceTasks(0);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.setMinInputSplitSize(job, 256*1024*1024);FileInputFormat.addInputPath(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));System.exit(job.waitForCompletion(true)?0:1);}
}
(4)测试程序,并查看输出结果。
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |
| 实验06 | SequenceFile、元数据操作与MapReduce单词计数 | https://want595.blog.csdn.net/article/details/133926246 |
| 实验07 | MapReduce编程:数据过滤保存、UID 去重 | https://want595.blog.csdn.net/article/details/133947981 |
| 实验08 | MapReduce 编程:检索特定群体搜索记录和定义分片操作 | https://want595.blog.csdn.net/article/details/133948849 |
| 实验09 | MapReduce 编程:join操作和聚合操作 | https://want595.blog.csdn.net/article/details/133949148 |
| 实验10 | MapReduce编程:自定义分区和自定义计数器 | https://want595.blog.csdn.net/article/details/133949522 |