5+非肿瘤分析,分型+WGCNA+机器学习筛选相关基因

糖尿病肾病(DKD)是糖尿病的长期并发症,引起肾脏微血管病变。它也是终末期肾脏疾病(ESRD)的主要原因之一,其病理生理过程复杂。及时预防和治疗对延缓DKD的发展具有重要意义。本研究旨在利用生物信息学分析找到可能成为DKD治疗靶点的关键诊断标志物。
1. 数据处理
作者从GEO数据库下载了七个数据集,共计214个样本,并使用“sva” R软件包的“ComBat”函数去除来自不同来源的数据的批次效应。PCA图表显示了在去除批次效应之前和之后的数据分布(分别为图1A、B),结果表明批次效应已经得到有效纠正。在合并数据后,可以准确区分DKD和正常样本(图1C)。使用“limma” R软件包进行差异分析, 作者鉴定出共计772个差异表达基因(其中381个上调,391个下调),如火山图所示(图1D)。接下来, 作者对差异基因进行ORA富集分析。从圆形网络图中可以看出,这些基因富集在“炎症反应”、“上皮间质转化”、“凋亡”和“TNFA信号通路通过NFKB”等途径中(图1E)。TreeMap显示,上调基因主要参与免疫激活、T细胞激活和细胞黏附等生物过程,而下调基因主要富集在与代谢调节相关的生物功能中(图1F)。这些发现通过Kyoto Encyclopedia of Genes and Genomes (KEGG)通路富集分析得到了相应的验证(图1G)。

图1 糖尿病肾病(DKD)的差异表达基因(DEG)鉴定和富集分析
2. DKD的不同亚组的鉴定
首先, 作者将氧化应激和炎症反应相关基因(OS Infla)与先前获得的差异表达基因(DEGs)进行交叉,并获得了84个差异表达的氧化应激和炎症反应相关基因(DEOIGs)(图2A)。接下来, 作者使用R软件包“ConsensusClusterPlus”根据这84个DEOIGs将DKD患者分为不同的亚组。当一致性矩阵k值为2时,DKD样本之间的交叉最小,符合选择标准(图2B-E)。因此,113个DKD样本被分为两个明显的聚类,即DKD亚型1和2(分别为C1和C2)。热图显示大多数DEOIGs在C1亚型中上调,在C2亚型和正常样本中下调(图2F)。GSEA富集分析表明,C1亚型富集了细胞外基质受体相互作用,而C2亚型富集了代谢途径(图2G)。 作者量化了不同免疫细胞亚群的ssGSEA富集分数,以用于研究DKD亚型与免疫细胞之间的关系。结果表明,C1亚型在更多与免疫相关的细胞中富集,如调节性T细胞、巨噬细胞、活化的B细胞和浆细胞样树突状细胞。然后, 作者通过查阅文献并使用ssGSEA分析量化结果,找到了近年来与DKD密切相关的通路。山地图显示了两个亚型和正常样本的通路ssGSEA得分,揭示了Wnt、Notch和凋亡通路在C1亚型中较高,而过氧化物酶活化受体(PPAR)、过氧化物酶体、哺乳动物雷帕霉素靶蛋白(mTOR)、自噬、AMPK和其他通路在C1亚型中较低(图2H)。

图2 DKD亚型的鉴定
3. 构建WGCNA并识别关键模块
作者使用了来自七个不同数据集的113个DKD样本,使用中位数绝对偏差对前5000个基因进行了WGCNA分析的筛选。随后, 作者根据尺度自由拟合指数和不同软阈值幂的平均连接度,基于尺度自由R2进行了评估。 作者的研究选择了软阈值幂β = 6和尺度自由R2 = 0.8744133来构建一个标准的尺度自由网络,使用Pick Soft Threshold函数(图3A)。最终, 作者确定了六个模块(图3B)。 作者使用相关热图来探索每个模块与糖尿病肾病的相关性,发现MEblue模块与C1和C2亚型的相关性最高(图3C)。基因重要性评分被用来分析基因与DKD亚型之间的关联,结果显示MEblue模块具有最高的基因重要性评分(图3D)。相关散点图进一步证明了MEblue模块中的基因不仅与MEblue模块强相关,而且与糖尿病肾病亚型显著相关(图3E)。因此, 作者提取了MEblue模块中的基因进行后续分析。

图3 加权基因共表达网络分析(WGCNA)
4. 糖尿病肾病的诊断标志物鉴定
作者通过对糖尿病肾病的两个亚型进行差异分析,获得了473个差异基因(|log2FC| > 1,padj < 0.05)。Venn图显示,在与MEblue模块中的1458个基因相交后,发现了347个相交基因。使用STRING在线网络工具构建了上述347个基因的PPI网络图,并在Cytoscape软件中进行了分析。使用Upset图选择满足CytoHubba插件的12种算法的相交基因,最终获得了279个基因(附图4)。基于这279个基因, 作者进一步使用不同的生物信息学方法筛选出诊断标志物。使用LASSO回归算法,挑选出了12个潜在生物标志物(图4A、B)。随机森林(RF)算法确定了15个候选基因(图4C、D)。SVM-RFE算法显示,当特征基因数为64时,准确率最高达到0.956(图4E)。最终, 作者获得了四个基因作为DKD的诊断标志物(图4F)。

图4 诊断标记物的鉴定
5. 四个诊断标志物的诊断价值和验证
箱线图显示了在七个合并的GEO数据集中四个标志基因的表达情况(图5A)。可以看出,DKD样本中四个基因的表达高于正常样本。Nephroseq v5在线数据库中的样本也验证了它们的高表达(图5B),表明它们在DKD的发生和发展过程中可能起到重要作用。在合并的GEO数据集中,当将所有四个基因作为一个变量进行拟合时,ROC曲线下面积(AUC)为0.808,比单独使用它们作为诊断变量时获得了更好的结果(图5C)。 作者还评估了这四个基因在来自GSE142025数据集的独立患者队列中的诊断效能。每个基因的ROC曲线下面积(AUC)值都大于0.8,表明这四个基因可以诊断DKD(图5D)。相关分析显示,四个基因的表达与肌酐呈正相关(图5E),与肾小球滤过率呈负相关(图5F)。

图5 诊断效能和诊断标志物的外部验证
6. 基于特征基因的DKD诊断模型的Nomogram构建
基于四个诊断标志物的表达, 作者基于逻辑回归构建了一个诊断模型,并绘制了一个图表(图6A)。在这个图表中,参与构建诊断模型的每个基因对应一个分数,它们的分数相加得到一个总分,该总分对应不同的DKD诊断效果。校准曲线显示该图表能可靠地诊断DKD(图6B)。ROC曲线表明该模型的AUC值为0.801(图6C)。DCA结果通过四个单独的基因或它们的组合来评估DKD患者的结果,显示了净效益(NB)。结果表明,组合的图表模型能显著增加净效益(图6D)。

图6 DKD诊断模型的构建
7. 诊断标志物的功能富集分析
为了探索与诊断标志物相关的生物过程, 作者分析了这四个诊断标志物与免疫细胞的相关性。结果表明,它们与大多数免疫细胞浸润呈正相关(图7A),如活化的CD4 T细胞、活化的树突状细胞、调节性T细胞、巨噬细胞等。接下来, 作者根据基因表达将DKD样本分为高表达组和低表达组。对高表达组和低表达组中的差异表达基因进行GSEA分析,以探索可能涉及的信号通路,结果发现这四个基因的通路富集是一致的。因此,它们在TNFA SIGNALING VIA NFKB、KRAS SIGNALING UP、INTERFERON GAMMA RESPONSE、INFLAMMATORY RESPONSE、EPITHELIAL MESENCHYMAL TRANSITION等方面均显著富集(图7B)。功能富集分析显示,这四个基因的高表达组均富集在ADAPTIVE IMMUNE RESPONSE、T CELL ACTIVATION、IMMUNE RESPONSE REGULATING CELL SURFACE RECEPTOR SIGNALING PATHWAY等方面。低表达组在生物过程中富集了一些如SMALL MOLECULE CATABOLIC PROCESS、FATTY ACID CATABOLIC PROCESS、INNER MITOCHONDRIAL MEMBRANE PROTEIN COMPLEX等的过程(图7C)。

图7 诊断标志物的生物学功能富集
8. 动物模型中的验证
为了进一步验证这四个标志物在早期DKD诊断中的诊断价值, 作者利用12周龄的db/db小鼠作为自发性DKD模型。 作者发现,与正常对照组小鼠相比,DKD组小鼠的体重、血糖、HbA1c、血清肌酐、血尿素氮和尿白蛋白/肌酐水平显著增加(图8A)。病理染色还显示DKD组小鼠的肾组织中有系膜细胞增生、系膜基质扩张以及肾小球和肾小管基底膜不规则增厚(图8B),表明自发性DKD模型已成功建立。接下来, 作者检测了四个生物标志物(包括TNC、PXDN、TIMP1和TPM1)的mRNA表达水平。结果显示,TNC、TPM1和PXDN在小鼠模型中显著升高。不幸的是,TIMP1呈上升趋势,两组之间没有差异(图8C)。 作者还检测了小鼠血液和尿液中的四个生物标志物中的三种分泌蛋白。结果显示,TNC和PXDN在血液和尿液中持续升高,而TIMP1在尿液中显著升高,但在血液中没有显著差异(图8D)。相关分析显示,无论是血液样本还是尿液样本,这些标志物与尿白蛋白/肌酐比值明显呈正相关。至于血糖和HbAc1,这些标志物与它们之间没有显著相关性。免疫组化结果显示,TNC、TPM1、TIMP1和PXDN的表达水平在DKD小鼠模型中升高(图8E)。为了进一步验证上述变化与DKD而不是糖尿病有关, 作者的研究还添加了两组6周龄的db/db小鼠和正常小鼠。 作者发现,与正常对照小鼠相比,DM小鼠的体重、血糖和HbA1c显著增加,但两组小鼠的血清肌酐、血尿素氮和尿白蛋白/肌酐水平之间没有差异。同时,在肾脏病理染色中没有发现显著差异。qRT-PCR的结果显示,TPM1和TIMP1的mRNA表达水平在两组之间没有统计学差异。TNC和PXDN的表达在DM组中增加。此外,检测了DM组小鼠的血液和尿液样本中三种分泌蛋白的表达水平,并发现只有血液样本中的TNC在DM小鼠中显著增加。对于尿液样本,DM小鼠中的TNC和TIMP1的升高存在显著差异。
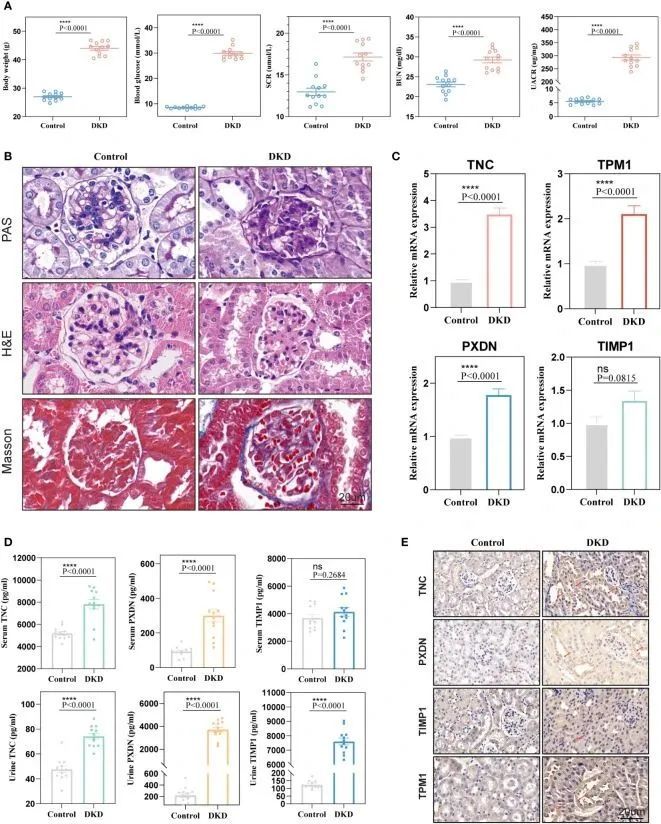
图8 动物实验中诊断标志物的验证
总结
总之, 作者通过全面系统的生物信息学分析和实验验证,确定了TNC、PXDN、TIMP1和TPM1作为DKD的潜在诊断标志物,并建立了一个包含这四个诊断标志物的图表,并初步探讨了它们在DKD的发生和发展中可能的生物学功能。这些发现将为DKD的早期诊断和治疗提供新的思路。