kafka 相关概念
1 kafka 生产者
kafka 用push的方式把消息推送到topic
每个topic下可以有多个分区,
可以用hash 也可以用轮询的方式指定分区
每个分区内部是可以保证顺序的,但是整体无法保证顺序,除非设置成一个topic只有一个分区。
kafka这种多分区的设置 带来的好处:
1.一般来说每个分区下面代表的是一台机器,对于生产者来说相当于提升了kafka的写速度。
2.对于生产者来说增加分区,还提升了存储能力。
3.对于消费者来说,一般是每台机器对应一个分区,所以提升了kafka的读能力。
其实就是高吞吐量
生产者分区&日志

消费者

高速写入
kafka的日志是以磁盘的方式保存的,一般认为在磁盘写速度较低
kafka 使用了顺序写,并且使用了MMFile (memory,mapped File)内存映射空间。来实现高速写入
内存映射技术原理就是,kafka在操作系统内核开辟了一个空间,这个空间关联了一个磁盘空间,每次写入的时候直接操作这个内核空间,然后由操作系统决定什么时候真正写入磁盘。
这种设计由一个问题,就是写入内核后,还没来得及同步就宕机了,数据会丢失。
解决的方式就是不写入内核,直接写入磁盘。
嗯,然后 写速度大大下降。可能得不偿失。
任何设计都不可能完美,在安全与速度之间会有取舍。
高速读取
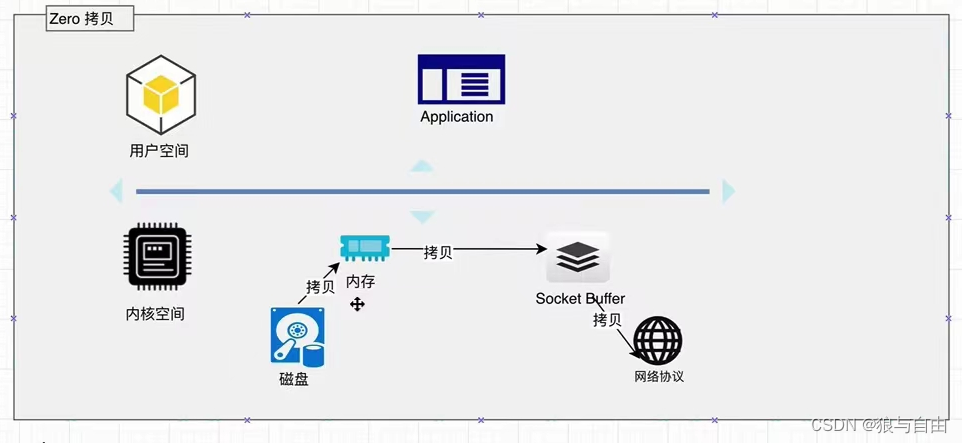
kafka在响应客户读取的时候使用zerocopy技术,直接将数据通过内核空间传递出去。数据并没有抵达用户空间
传统io:
1.磁盘中的数据copy到内核缓冲区
2.内核缓冲区copy到用户缓冲区
3.用户缓冲区copy到socket缓冲区
4.socket copy到相关协议发送区

zeroCopy
1.磁盘中的数据copy到内核缓冲区
2.内核copy到socket相关缓冲区
3.socket copy到相关协议发送区