spark读取hive表字段,区分大小写问题
背景
spark任务读取hive表,查询字段为小写,但Hive表字段为大写,无法读取数据
问题错误:
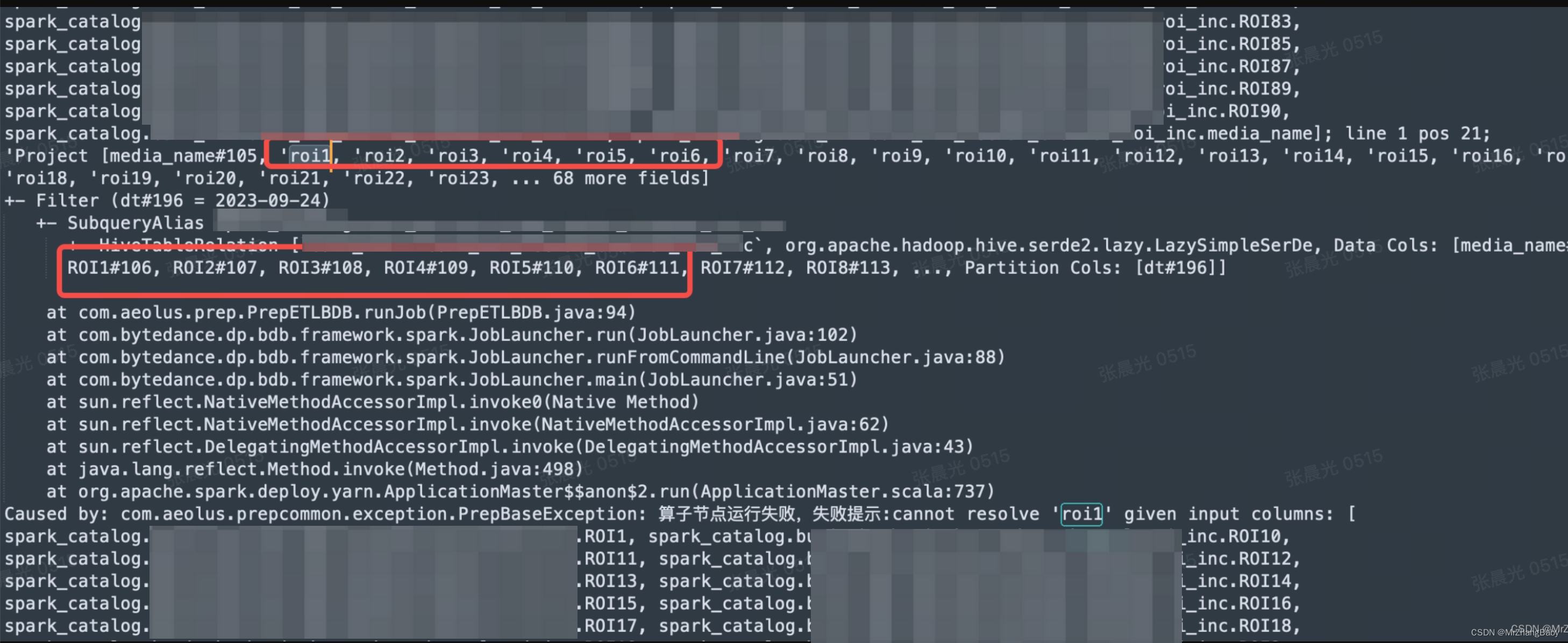
如何解决呢?
- In version 2.3 and earlier, when reading from a Parquet data source table, Spark always returns null for any column whose column names in Hive metastore schema and Parquet schema are in different letter cases, no matter whether
spark.sql.caseSensitiveis set totrueorfalse. Since 2.4, whenspark.sql.caseSensitiveis set tofalse, Spark does case insensitive column name resolution between Hive metastore schema and Parquet schema, so even column names are in different letter cases, Spark returns corresponding column values. An exception is thrown if there is ambiguity, i.e. more than one Parquet column is matched. This change also applies to Parquet Hive tables whenspark.sql.hive.convertMetastoreParquetis set totrue.
# 在程序或者sql中添加这个参数即可
set spark.sql.caseSensitive = false参考地址:
Migration Guide: SQL, Datasets and DataFrame - Spark 3.2.0 Documentation