如何实现chatGPT批量问答,不用token
一、背景
因为需要批量提取一本教材里的概念做成知识图谱,想用chatGPT做概念提取。
- 调用api?别想了… 免费帐户的api慢得一批
- 于是想用模仿人类交互的方法来调用,本来想用pyautogui的,但是主要是与浏览器交互,还是用selenium比较方便。但看了下现在公开出来的selenium的方法代码,都不太能用(可能是网站更新?),所以还不如自己手撸一个。
下面代码使用的python库是 selenium(用来模拟浏览器浏览、输入、点击、读取等行为)、undetected_chromedriver(用来规避selenium默认的浏览器驱动会导致的跳不过人机识别的问题)
二、步骤
1. 确保库安装好了
执行下面代码安装
pip install selenium
pip install undetected_chromedriver
2. 测试能否使用浏览器驱动
执行下面代码,后台应该可以自动打开浏览器,并跳转到openai界面。(该方法虽然不需要用token,但需要进入chatGPT界面,它只是模拟人重复的与chatGPT交互)
import time # 用来之后做等待
import undetected_chromedriver as uc # 不会被监测的浏览器驱动from selenium.webdriver.remote.webdriver import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys# 浏览器打开openai界面
options = uc.ChromeOptions()
options.headless = False
driver = uc.Chrome(options=options,version_main=117)
driver.get("https://chat.openai.com")
3. 准备input.txt
准备好我们想要问的问题,下面是我自己写的一个输入测试文档,在不同的问题之间,用--- 进行分隔。

4. 执行第二段代码,开启自动循环
## ------------- 1. 需要解析的文档路径 (第二步:配置好input文档后,执行下面所有代码)-------------
input_file = r'input.txt'# 0.1. 用utf-8的编码读取上述md文件
try:# 使用UTF-8编码打开文件with open(input_file, 'r', encoding='utf-8') as file:md_content = file.read()
except FileNotFoundError:print(f"文件 '{input_file}' 未找到.")
except Exception as e:print(f"发生错误: {str(e)}")# 0.2 按照\n---\n分割文本,得到文本列表
text_list = md_content.split("\n---\n")
response_list = []
talk_num = 3 # 对话次数,初始化为3(经验值)
for a_text in text_list:result = extract_small(a_text, driver, talk_num)response = result[0]talk_num = result[1] # 会迭代增加。#response_list.append(response) # 将回复添加到列表# 0.3 重新构造output输出
output_str = ''
for i in range(len(text_list)):output_str += text_list[i] + '\n'output_str += '🤖:' + response_list[i]output_str += '\n---\n'
# 讲上面构造的output_str输出到文件里面
# 将output_str写入文件
output_file = r'output.txt' # 定义输出文件的路径和名称
try:with open(output_file, 'w', encoding='utf-8') as file:file.write(output_str)print(f"已将结果写入文件 '{output_file}'")
except Exception as e:print(f"写入文件时发生错误: {str(e)}")
三、源码使用说明
extract_small() 函数还包括了识别chatGPT有没有回答完成的功能,有效避免睡眠固定时间导致的时间浪费问题。extract_small() 已经放在源码中了。感兴趣的同学可以去看源码。>>> 源码链接
源码使用方法
-
解压压缩包;在Pycharm打开这个文件夹
-
执行 pip install undetected_chromedriver 和 pip install selenium

-
执行第1到63行代码,后台会自动打开浏览器,需要手动登录账号和点掉系统的弹窗;
-
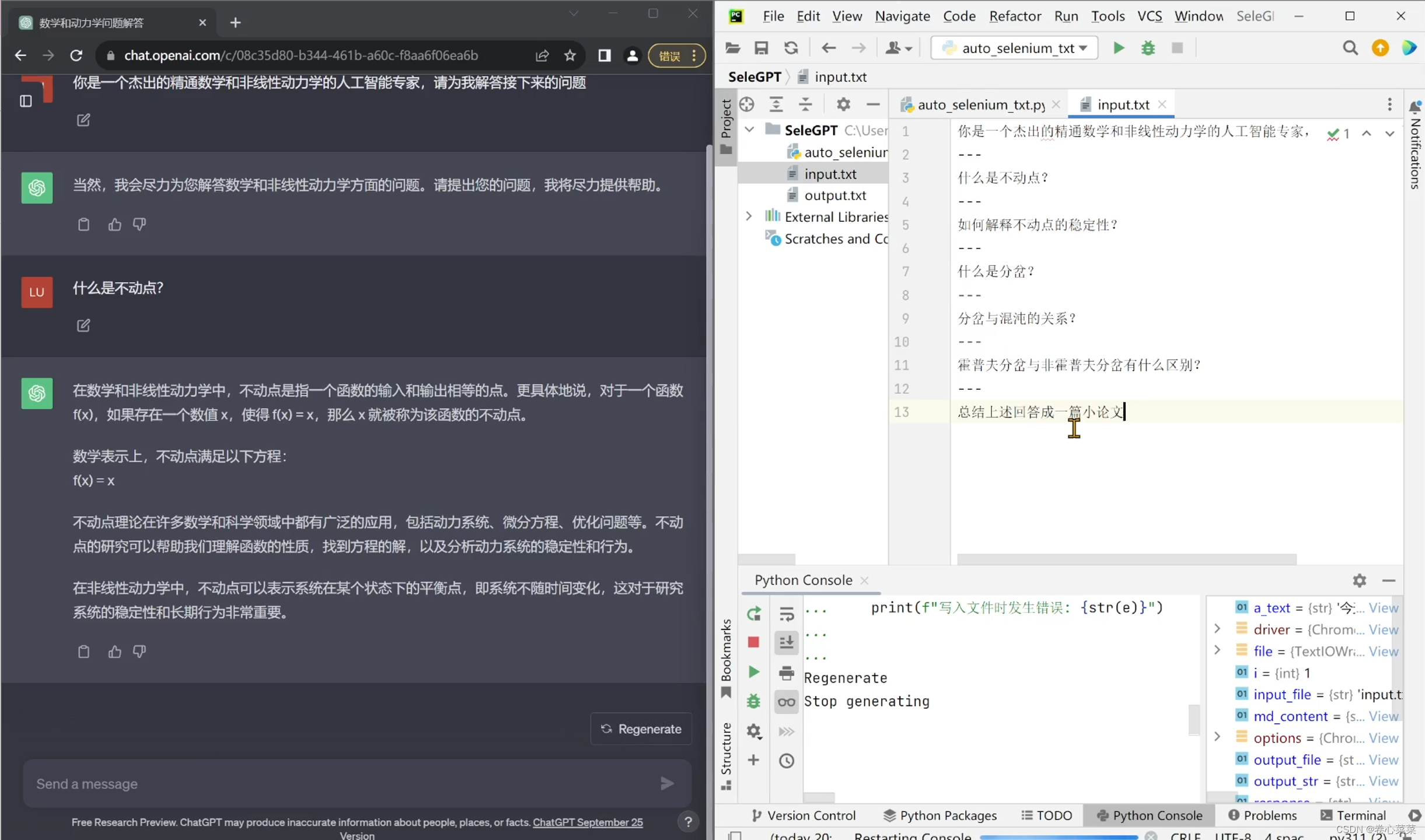
按照模板准备好input.txt文件后,执行剩下的代码;可以看到程序自动执行了。
效果视频展示:
3分钟,教你做个GPT批量问答还不用token | 有源码
总结
该程序实现了无需token批量与chatGPT交互的方法,一共分为两个步骤:打开auto_selenium_txt.py
先运行第一步的代码,执行之后会自动打开浏览器,需要手动配置好浏览器界面;
再运行的第二步代码,配置好文件夹中的input文档,执行之后会开始自动批量问答。结束之后会保存的output文档