Python为Excel中每一个单元格计算其在多个文件中的平均值
本文介绍基于Python语言,对大量不同的Excel文件加以跨文件、逐单元格平均值计算的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中有如下所示的大量Excel文件,我们这里就以.csv文件为例来介绍。其中,每一个.csv文件的名称都是如下图所示的Ref_XXX_Y.csv格式的,其中XXX表示三个字母,后面的Y则表示若干位数字。
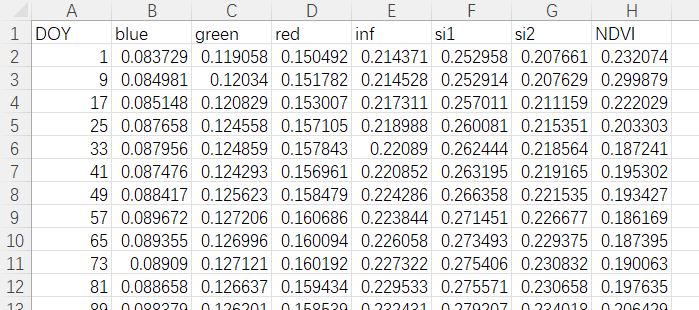
对于其中的每一个.csv文件,都有着如下图所示的数据格式。

我们现在的需求是,希望对于每一个名称为Ref_GRA_Y.csv格式的.csv文件,求取其中每一个单元格在所有文件中数据的平均值。例如,对于上图中DOY为1的blue这个单元格,那么求出来的平均值就是在全部名称为Ref_GRA_Y.csv格式的.csv文件之中,DOY为1且列名为blue的单元格的平均值。此外,如果像上图一样,出现了部分单元格数值为0的情况,表明在当前文件夹下,这个单元格是没有数据的,因此需要在计算的时候舍去(并且取平均值时候的分母也要减小1)。
知道了需求,我们就可以开始代码的书写。其中,本文用到的具体代码如下所示。此外,本文实现的需求也和我们之前的文章基于Python读取多个Excel文件数据并跨越不同xlsx表格文件计算平均值(https://blog.csdn.net/zhebushibiaoshifu/article/details/115533619)有些类似,大家如果有需要,也可以参考之前的这一篇文章。
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 6 13:07:48 2023@author: fkxxgis
"""import os
import glob
import pandas as pdfolder_path = "E:/04_Reconstruction/02_Data/01_RGBNINDVI_History"
output_path = "E:/04_Reconstruction/02_Data"
file_pattern = "Ref_GRA_*.csv"file_paths = glob.glob(os.path.join(folder_path, file_pattern))combined_data = pd.DataFrame()for file_path in file_paths:df = pd.read_csv(file_path)df_filtered = df[df != 0]combined_data = pd.concat([combined_data, df_filtered])average_values = combined_data.groupby('DOY').mean()output_file = "04_Data_YearAverage.csv"
average_values.to_csv(os.path.join(output_path,output_file), index=True)
其中,上述代码的具体介绍如下。
首先,我们导入必要的库——os库用于文件路径操作,glob库用于文件匹配,pandas库用于数据处理和分析。同时,我们定义文件夹路径folder_path,代表存储.csv文件的文件夹路径;定义输出路径output_path,代表保存结果文件的路径;定义文件匹配模式file_pattern,用于匹配需要处理的.csv文件的文件名模式。
随后,我们使用glob.glob()函数结合文件夹路径和文件匹配模式,获取满足条件的.csv文件的路径列表,存储在file_paths变量中。创建一个空的数据框combined_data,用于存储所有文件的数据。
接下来,我们使用一个循环,遍历file_paths列表中的每个文件路径。对于每个文件路径,使用pd.read_csv()函数加载.csv文件,并将其存储在名为df的数据框中。其次,使用条件筛选语句df[df != 0]排除值为0的数据,并将结果存储在名为df_filtered的数据框中。紧接着,将当前文件的数据框df_filtered合并到总数据框combined_data中,这一步骤使用pd.concat()函数实现。
完成所有文件的处理后,使用combined_data.groupby('DOY').mean()计算所有文件的平均值,按照DOY列进行分组并求平均值。随后,定义输出文件名output_file,代表保存平均值结果的文件名。
最后,使用os.path.join()函数结合输出路径和输出文件名,生成保存路径,并使用average_values.to_csv()函数将平均值数据框average_values保存为一个新的.csv文件,指定index=True以包含索引列。
运行上述代码,我们即可得到结果文件。如下图所示,可以看到结果文件中,已经是计算之后的平均值结果了。
至此,大功告成。
欢迎关注:疯狂学习GIS