数据结构与算法(七)--使用链表实现栈
一、前言
之前我们已经学习了链表的所有操作及其时间复杂度分析,我们可以了解到对于链表头的相关操作基本都是O(1)的,例如链表头增加、删除元素,查询元素等等。那我们其实有一个数据结构其实可以完美利用到这些操作的特点,都是在某一段进行操作,那就是栈。本章我们通过链表去实现栈。并且比较用数组实现和用链表实现他们之间的差异。
二、用链表实现栈
2.1、代码实现
那么通过链表实现栈就很简单了,我们知道入栈和出栈都是从链表的同一端进行操作,那么我们只需调用链表的addFirst/removeFirst的方法即可,查找同理。
首先我们将链表栈命名为LinkedListStack,并且实现我们Stack的抽象类,然后设置一个内部属性为我们之前实现的链表,通过该链表完成实现需要重写的方法即可,代码如下:
public class LinkedListStack<T> implements Stack<T> {private LinkedList<T> linkedList;public LinkedListStack() {this.linkedList = new LinkedList<>();}@Overridepublic int getSize() {return linkedList.getSize();}@Overridepublic boolean isEmpty() {return linkedList.isEmpty();}@Overridepublic void push(T t) {linkedList.addFirst(t);}@Overridepublic T pop() {return linkedList.removeFirst();}@Overridepublic T peek() {return linkedList.getFirst();}@Overridepublic String toString() {StringBuilder stringBuilder = new StringBuilder();stringBuilder.append("Stack: top ");stringBuilder.append(linkedList);return stringBuilder.toString();}
}测试一下:
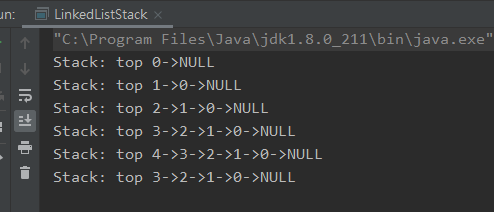
public static void main(String[] args) {LinkedListStack<Integer> integerArrayStack = new LinkedListStack<>();for (int i = 0; i < 5; i++) {integerArrayStack.push(i);System.out.println(integerArrayStack);}integerArrayStack.pop();System.out.println(integerArrayStack);}
结果没有问题,通过链表实现栈就这样简单的实现了。
2.2、和数组栈比较性能
这个代码和之前数组队列和循环队列效率的对比很接近:
public class TestStackCompare {private static double testQueue(Stack<Integer> s, int opCount){long startTime = System.currentTimeMillis();Random random = new Random();for (int i = 0; i < opCount; i++) {s.push(random.nextInt(Integer.MAX_VALUE));}for (int i = 0; i < opCount; i++) {s.pop();}long endTime = System.currentTimeMillis();return (endTime - startTime)/1000.0;}public static void main(String[] args) {ArrayStack<Integer> integerArrayStack = new ArrayStack<>();LinkedListStack<Integer> integerLinkedListStack = new LinkedListStack<>();System.out.println("arrayStack,time:"+testQueue(integerArrayStack,1000000)+"s");System.out.println("linkedListStack,time:"+testQueue(integerLinkedListStack,1000000)+"s");}
}
那么我们运行下,发现两者效率近乎一致:
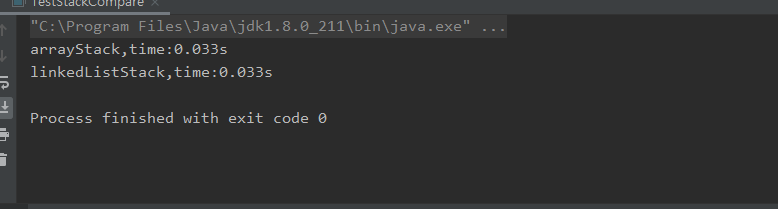
当然也有可能得到的结果是有差距的,对于arrayStack来说,时不时就需要扩容,这个对于某些操作系统来说比较耗费时间,而对于linkedListStack来说,它每次new Node就需要不断的开辟空间,这个操作又对于某些操作系统来说更耗费时间;而且这两者的差距会随着操作次数的增多不断拉大,因为扩容并不是每次扩容,而new Node确实是需要每次都new一个,例如我将操作次数放大为10000000次,这个时候两者的时间差距就比较大了:
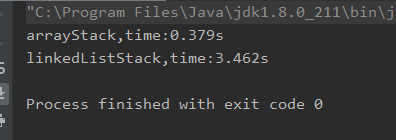
所以仍然取决于你测试使用的操作系统,配置,jvm版本等等。但是其实我想强调的是,对于数组栈和链表栈来说,他们的各项操作的时间复杂度其实是一致的。他们之间没有复杂度之间的巨大差异。不像数组队列和循环队列,一个6s,一个0.01s,这之间的差距是非常大的。