Java面试数据库
目录
一、关系型数据库
数据库权限
表设计及创建
表数据相关
数据库架构优化
二、非关系型数据库
redis
今天给大家稍微整理了一下,内容有数据表设计的三大范式原则、sql查询如何优化、redis数据的击穿、穿透、雪崩等...,以及相关的面试题,希望即将面试的朋友们看了后能有帮助。
一、关系型数据库
关系型数据库有SQLserver、Oracle、MySQL
问题一:关系型数据库与非关系型数据库区别?
都是数据库,用来存储数据;关系型数据库存储数据是以表的形式进行存储,表之间有存在主外键关系,那也就是说数据之间存在关系;
非关系型数据库数据存储是以键值对的形式存储;数据之间没有关系/联系;
数据库权限
mysql
端口号:3306
数据库权限分类:mysql库
user、db、table_priv表权限表、columns_priv
生产环境:
项目经理:Create、drop、grant、select、Update、delete、insert...
项目组长:select、Update、delete、insert...
普通开发:select
测试环境:一般也是拥有所有权限
开发环境:一切自己说了算,拥有所有权限
表设计及创建
工具:powerdesign
#三大范式
第一范式:列不可再分
例:地址填时湖南省长沙市岳麓区天顶街道浪琴湾清水22栋,用一个字段address存储,违反了第一范式,应该用四个字段Provence---湖南省 city---长沙市 area---岳麓区 address---天顶街道浪琴湾清水22栋。
为什么要遵循第一范式?
如果要统计湖南省的某物品销量时,可以直接统计Provence字段。
把表设计字段力度越大,未来应对变化的可能性越强。
第二范式:主键约束 非主属性与非主属性不能存在关系
例:购物车下单,多个订单项对应一个订单,当订单入库时,数据库表设计字段是以下两种
违反:在建表中设计4个字段:名称 数量 单价 小计
遵循:在建表中设计3个字段:名称 数量 单价
第三范式:外键约束 关联表的数据不一致
举例:看病流程表:Doctorid,userId
如果需要在页面上显示医生的姓名以及患者的姓名的话,需要连接看病流程表,医生表,患者档案表;有以下表设计
违反:Doctorid,DoctorName,userId,userName
遵循:Doctorid,userId
六大约束:
NOT NULL (非空约束)、unique(唯一约束)、primary key(主键约束)、Foreignkey(外键约束)、CHECK (检查约束)、default(默认约束)
表数据相关
问题二:drop/delete/truncate的区别
drop删除表和数据,delete删除数据和索引,truncate删除数据不包括索引。
如果现在有一个表,表里面有10条数据,drop连着表和数据一起删除,delete删除where条件后面的数据,当这个时候后面表再有新增的话,会在where已经删除数据的索引上进行新增;而truncate相反。
查询笔试题
链表查询:子查询、外连接、内连接、Union all
问题三:sql查询如何优化
1.该sql语句是否建立索引
2.如果有索引,是否失效 如:like '%%'已失效
3.索引泛滥 通过explain执行计划查询sql语句的执行效率
数据库架构优化
方法一:集群
(读写分离)
将数据库读与写解耦,一定程度上提高性能;
成本降低,可以资源在利用
技术实现:数据库中间件Mycat方法二:分库分表
(水平分库)
场景:当遇到大量需要查询数据时,我们可以按月份分库,如果需要查找指定数据,可以按月份进行查询。实现:
1.每月凌晨00:00代码自动构建新表====>通过用任务调用框架quartz实现create t_order_${month} as
select * from t_order where 1=2
2.insert into t_order_${month} values(?,?,?)
(垂直分库)按照数据区分:热数据与冷数据分开,将一张表拆成两张一对一关系的表,分别是常用数据表与冷数据表。一般情况下,只需要查询常用数据表就行了,提升数据查询效率。如果需要查询冷数据表时,也可以进行连表查询。
二、非关系型数据库
redis
存储类型:string、set、hash、zset、list
作用:redis作为缓存就是为了减少对数据库的访问压力,当我们访问一个数据的时候,首先我们从redis中查看是否有该数据,如果没有,则从数据库中读取,将从数据库中读取的数据存放到缓存中,下次再访问同样的数据的是,还是先判断redis中是否存在该数据,如果有,则从缓存中读取,不访问数据库了。
#问题四:击穿、穿透、雪崩
图解如下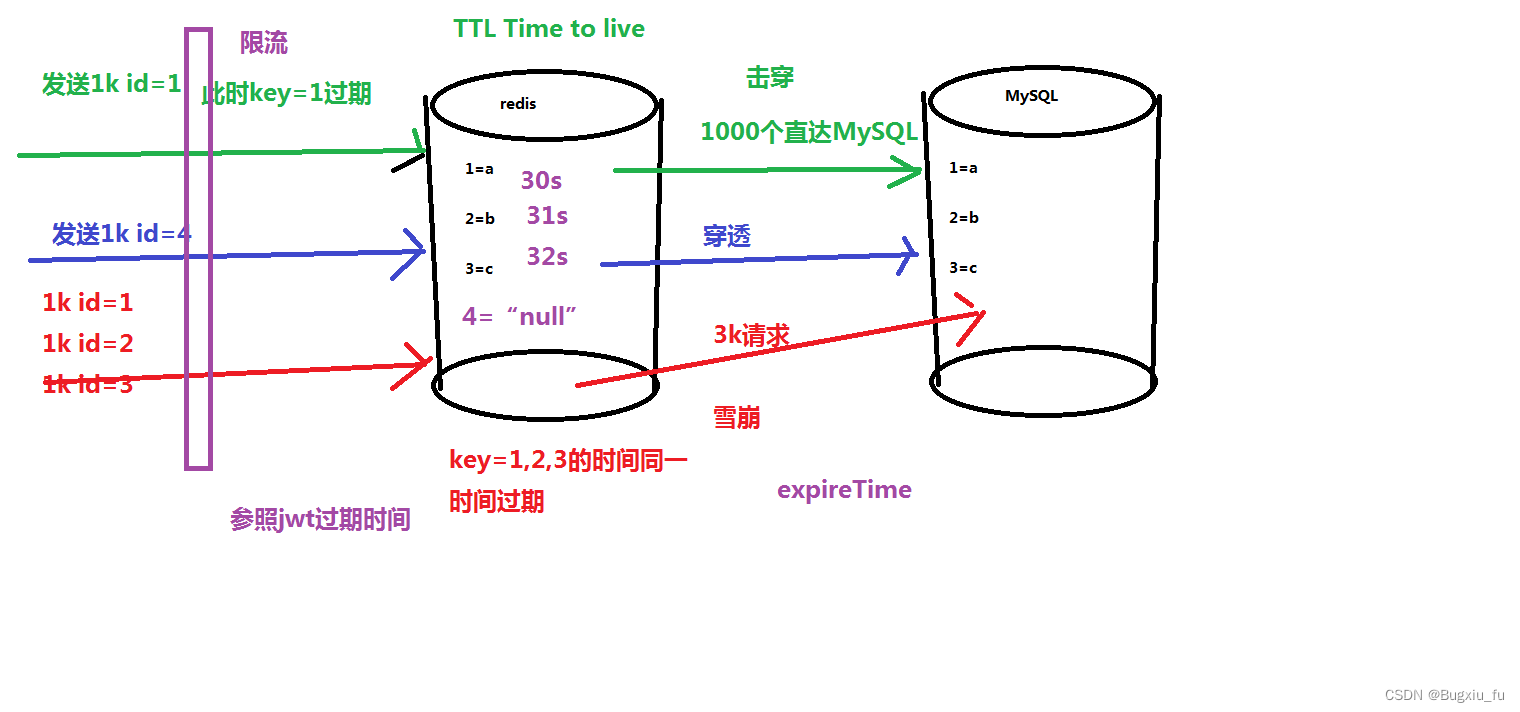
击穿------就是大量请求到达redis,正好该请求的key过期,大量请求到达Mysql数据库。
穿透-----指的是访问一个压根不存在的数据,那么每一次请求都会穿透redis,到达MySQL。
解决方法就是给不存在的数据设置一个默认值;
雪崩-----就是大量请求到达redis,访问的不同的key时在同一时间失效,如果在redis拿不到值,那么大量的请求会到达MySQL,导致MySQL宕机。
解决就是给不同的缓存key,设置不同的时间;