机器学习笔记之近似推断(一)从深度学习角度认识推断
机器学习笔记之近似推断——从深度学习角度认识推断
- 引言
- 推断——基本介绍
- 精确推断难的原因
- 虽然能够表示,但计算代价太大
- 无法直接表示
引言
本节是一篇关于推断总结的博客,侧重点在于深度学习模型中的推断任务。
推断——基本介绍
推断(Inference\text{Inference}Inference)——我们并不陌生,在介绍的每一个概率模型,基本都涉及到推断问题。关于概率模型的三大核心问题分别是:表示(Representation\text{Representation}Representation),推断,学习(Learning\text{Learning}Learning)。我们从深度模型,主要是深度生成模型所涉及的推断任务出发,对推断进行描述。
首先,是什么样的原因,导致了推断这个任务的发生?换句话说,推断的动机是什么。
-
我们基于可观察的样本特征X\mathcal XX,构建概率图模型。如果包含隐变量Z\mathcal ZZ,而隐变量Z\mathcal ZZ绝大多数情况下没有物理意义,它只是我们建模过程中人工设置出来的随机变量。
Z\mathcal ZZ一上来就是未知的,但为了完善被构建的模型,我们有必要了解隐变量Z\mathcal ZZ的特征信息。从哪里去了解/通过什么渠道去了解Z\mathcal ZZ? 从 样本X\mathcal XX。
当样本X\mathcal XX进入到模型后,Z\mathcal ZZ会产生什么样的反映,而这个反映就是隐变量Z\mathcal ZZ的特征信息,即P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)。而推断就是求解Z\mathcal ZZ特征信息P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)的手段。因此:推断的第一个动机就是推断自身。我们需要通过样本X\mathcal XX的渠道,将Z\mathcal ZZ的特征信息描述出来。
-
关于推断的另一个动机来自于模型的学习任务。也就是说,在模型参数θ\thetaθ的学习过程中,可能存在 不可避免地使用推断。
一个经典例子就是受限玻尔兹曼机(Restricted Boltzmann Machine,RBM\text{Restricted Boltzmann Machine,RBM}Restricted Boltzmann Machine,RBM)。在受限玻尔兹曼机基于极大似然估计来求解对数似然梯度∇θ[logP(v(i);θ)]\nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right]∇θ[logP(v(i);θ)]的过程中,可将对数似然梯度描述为如下形式:
需要注意的是,针对某个观测样本v(i)v^{(i)}v(i),我们并没有将所有参数的对数似然梯度都求出来,仅求解的是v(i)v^{(i)}v(i)中某一随机变量vj(i)v_j^{(i)}vj(i)与对应模型中隐变量h(i)h^{(i)}h(i)的某一随机变量hk(i)h_k^{(i)}hk(i)之间的模型参数Wvj(i)⇔hk(i)\mathcal W_{v_j^{(i)} \Leftrightarrow h_k^{(i)}}Wvj(i)⇔hk(i)的对数似然梯度。关于hj(i)h_j^{(i)}hj(i)是一个服从‘伯努利分布’的随机变量,完整推导过程见上述链接。
∇θ[logP(v(i);θ)]⇒∂∂Wvj(i)⇔hk(i)[logP(v(i);θ)]=P(hk(i)=1∣v(i))⋅vj(i)⏟第一项−∑v(i)P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)⏟第二项\begin{aligned} \nabla_{\theta} \left[\log \mathcal P(v^{(i)};\theta)\right] & \Rightarrow \frac{\partial}{\partial \mathcal W_{v_j^{(i)} \Leftrightarrow h_k^{(i)}}} \left[\log \mathcal P(v^{(i)};\theta)\right] \\ & = \underbrace{\mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}}_{第一项} - \underbrace{\sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}}_{第二项} \end{aligned}∇θ[logP(v(i);θ)]⇒∂Wvj(i)⇔hk(i)∂[logP(v(i);θ)]=第一项P(hk(i)=1∣v(i))⋅vj(i)−第二项v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)
关于上述的对数似然梯度结果,第一项中的P(hk(i)=1∣v(i))\mathcal P(h_k^{(i)} = 1 \mid v^{(i)})P(hk(i)=1∣v(i))就用到了后验概率的推断结果:
推导过程详见受限玻尔兹曼机——推断任务(后验概率),这里nnn表示v(i)v^{(i)}v(i)中随机变量结点的个数。
P(hk(i)=1∣v(i))=Sigmoid(∑j=1nWhk(i)⇔vj(i)⋅vj(i)+ck(i))\mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) = \text{Sigmoid}\left(\sum_{j=1}^n \mathcal W_{h_k^{(i)}\Leftrightarrow v_j^{(i)}} \cdot v_j^{(i)} + c_k^{(i)}\right)P(hk(i)=1∣v(i))=Sigmoid(j=1∑nWhk(i)⇔vj(i)⋅vj(i)+ck(i))
这明显是一个精确推断(Precise Inference\text{Precise Inference}Precise Inference)。相反,同样使用推断的方式进行求解,使用对比散度这种近似推断的方式加快采样速度。
由于这里重点描述的是‘推断’与‘学习任务’之间的关联关系,这里就不展开求解了.另一个经典例子就是EM\text{EM}EM算法(Expectation Maximization,EM\text{Expectation Maximization,EM}Expectation Maximization,EM)。它的E\text{E}E步可表示为如下形式:
logP(X;θ)=∫ZQ(Z)⋅logP(X∣θ)dZ=∫ZQ(Z)logP(X,Z;θ)Q(Z)dZ⏟ELBO+{−∫ZQ(Z)logP(Z∣X)Q(Z)dZ}⏟KL Divergence\begin{aligned} \log \mathcal P(\mathcal X ; \theta) & = \int_{\mathcal Z} \mathcal Q(\mathcal Z) \cdot \log \mathcal P(\mathcal X \mid \theta) d\mathcal Z \\ & = \underbrace{\int_{\mathcal Z} \mathcal Q(\mathcal Z) \log \frac{\mathcal P(\mathcal X,\mathcal Z;\theta)}{\mathcal Q(\mathcal Z)}d\mathcal Z}_{\text{ELBO}} + \underbrace{\left\{- \int_{\mathcal Z} \mathcal Q(\mathcal Z) \log \frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)} d\mathcal Z\right\}}_{\text{KL Divergence}} \end{aligned}logP(X;θ)=∫ZQ(Z)⋅logP(X∣θ)dZ=ELBO∫ZQ(Z)logQ(Z)P(X,Z;θ)dZ+KL Divergence{−∫ZQ(Z)logQ(Z)P(Z∣X)dZ}
其中X\mathcal XX是基于样本的随机变量集合;Q(Z)\mathcal Q(\mathcal Z)Q(Z)是人为设定的、关于隐变量Z\mathcal ZZ的分布;如果关于Z\mathcal ZZ的后验分布P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)可求解,即Q(Z)=P(Z∣X)\mathcal Q(\mathcal Z) = \mathcal P(\mathcal Z \mid \mathcal X)Q(Z)=P(Z∣X),那么此时KL Divergence=0\text{KL Divergence} = 0KL Divergence=0,自然可以使用参数迭代逼近 的方式对模型参数θ\thetaθ进行迭代求解:
其中的Q(Z)=P(Z∣X)\mathcal Q(\mathcal Z) = \mathcal P(\mathcal Z \mid \mathcal X)Q(Z)=P(Z∣X)明显是一种对P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)的精确推断。
{logP(X;θ)=ELBO(KL Divergence=0)θ(t+1)=argmaxθ[∫ZP(Z∣X,θ(t))logP(X,Z;θ)dZ]\begin{cases} \log \mathcal P(\mathcal X;\theta) = \text{ELBO} \quad (\text{KL Divergence} = 0) \\ \theta^{(t+1)} = \mathop{\arg\max}\limits_{\theta} \left[\int_{\mathcal Z} \mathcal P(\mathcal Z \mid \mathcal X,\theta^{(t)}) \log \mathcal P(\mathcal X , \mathcal Z;\theta) d\mathcal Z\right] \end{cases}⎩⎨⎧logP(X;θ)=ELBO(KL Divergence=0)θ(t+1)=θargmax[∫ZP(Z∣X,θ(t))logP(X,Z;θ)dZ]
但实际情况下,关于隐变量Z\mathcal ZZ的后验分布P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)可能无法精确求解,此时Q(Z)\mathcal Q(\mathcal Z)Q(Z)的作用就是逼近当前迭代步骤中的P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X),使得当前迭代步骤的ELBO\text{ELBO}ELBO达到最大;再将当前迭代步骤最优近似分布Q(Z)\mathcal Q(\mathcal Z)Q(Z)带回ELBO\text{ELBO}ELBO中,从而求出当前迭代步骤的最优参数。这就是广义EM\text{EM}EM算法:相对于EM算法过程,因P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)自身无法精确求解的问题,广义EM算法使得分布Q(Z)≈P(Z∣X)\mathcal Q(\mathcal Z) \approx \mathcal P(\mathcal Z \mid \mathcal X)Q(Z)≈P(Z∣X)这明显是一种近似推断。下面描述给定ttt时刻模型参数θ(t)\theta^{(t)}θ(t)的条件下,求解t+1t+1t+1时刻E\text{E}E步的近似分布Q^(t+1)(Z)\hat {\mathcal Q}^{(t+1)}(\mathcal Z)Q^(t+1)(Z)与t+1t+1t+1时刻M\text{M}M步最优参数θ(t+1)\theta^{(t+1)}θ(t+1)的过程。
{Q^(t+1)(Z)=argmaxQ(Z)∫ZQ(Z)logP(X,Z;θ(t))Q(Z)dZ⏟ELBO⇔argminQ(Z)−∫ZQ(Z)logP(Z∣X)Q(Z)dZ⏟KL Divergenceθ(t+1)=argmaxθ∫ZQ^(t+1)(Z)logP(X,Z;θ)Q^(t+1)(Z)dZ⏟ELBO\begin{cases} \hat {\mathcal Q}^{(t+1)}(\mathcal Z) = \mathop{\arg\max}\limits_{\mathcal Q(\mathcal Z)} \underbrace{\int_{\mathcal Z} \mathcal Q(\mathcal Z) \log \frac{\mathcal P(\mathcal X,\mathcal Z;\theta^{(t)})}{\mathcal Q(\mathcal Z)} d\mathcal Z}_{\text{ELBO}} \Leftrightarrow \mathop{\arg\min}\limits_{\mathcal Q(\mathcal Z)} \underbrace{- \int_{\mathcal Z} \mathcal Q(\mathcal Z) \log \frac{\mathcal P(\mathcal Z \mid \mathcal X)}{\mathcal Q(\mathcal Z)} d\mathcal Z}_{\text{KL Divergence}}\\ \theta^{(t+1)} = \mathop{\arg\max}\limits_{\theta} \underbrace{\int_{\mathcal Z} \hat {\mathcal Q}^{(t+1)}(\mathcal Z) \log \frac{\mathcal P(\mathcal X,\mathcal Z ;\theta)}{\hat {\mathcal Q}^{(t+1)}(\mathcal Z)}d\mathcal Z}_{\text{ELBO}} \end{cases}⎩⎨⎧Q^(t+1)(Z)=Q(Z)argmaxELBO∫ZQ(Z)logQ(Z)P(X,Z;θ(t))dZ⇔Q(Z)argminKL Divergence−∫ZQ(Z)logQ(Z)P(Z∣X)dZθ(t+1)=θargmaxELBO∫ZQ^(t+1)(Z)logQ^(t+1)(Z)P(X,Z;θ)dZ
这两个模型参数学习的例子(一个是学习参数梯度,一个是迭代学习参数),它们都不可避免地对隐变量的后验分布进行推断。
精确推断难的原因
虽然能够表示,但计算代价太大
为什么要近似推断?最核心的原因是:精确推断非常困难。也就是说,精确推断的代价太大了。
- 依然以上述受限玻尔兹曼机对数似然梯度求解过程中的第二项为例:
∑v(i)P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)\sum_{v^{(i)}} \mathcal P(v^{(i)}) \cdot \mathcal P(h_k^{(i)} = 1 \mid v^{(i)}) \cdot v_j^{(i)}v(i)∑P(v(i))⋅P(hk(i)=1∣v(i))⋅vj(i)
其中,∑v(i)\sum_{v^{(i)}}∑v(i)表示样本数量的连加项,有NNN项;如果观测变量V\mathcal VV中包含nnn个随机变量,即:v(i)=(v1(i),v2(i),⋯,vn(i))n×1Tv^{(i)} = (v_1^{(i)},v_2^{(i)},\cdots,v_n^{(i)})_{n \times 1}^Tv(i)=(v1(i),v2(i),⋯,vn(i))n×1T,并且各观测变量之间相互独立且均服从伯努利分布。那么P(v(i))\mathcal P(v^{(i)})P(v(i))可表示为如下形式:
P(v(i))=∏m=1nP(vm(i))\mathcal P(v^{(i)}) = \prod_{m=1}^n \mathcal P(v_m^{(i)})P(v(i))=m=1∏nP(vm(i))
仅仅P(v(i))\mathcal P(v^{(i)})P(v(i))一项的复杂度就是O(2n)\mathcal O(2^n)O(2n);暂时不考虑P(hk(i)=1∣v(i))\mathcal P(h_k^{(i)} = 1 \mid v^{(i)})P(hk(i)=1∣v(i))中Sigmoid\text{Sigmoid}Sigmoid函数内线性计算的复杂度,上式中的复杂度 至少是O(N⋅2n)\mathcal O(N\cdot 2^n)O(N⋅2n)。能算吗?能算,但样本足够多的情况下,代价可看作是无穷大。
这还仅仅是将随机变量设置成最简单的伯努利分布,如果复杂度出现‘指数级别’,就可看做是‘无法求解的’(Intractable\text{Intractable}Intractable).
上述的例子可以根据受限玻尔兹曼机自身关于随机变量的约束能够将复杂的概率分布进行分解,只是分解出的结果计算量太大;
无法直接表示
然而存在一些模型,模型内部随机变量关联关系复杂的同时,还十分没有章法。最终导致联合概率分布连分解都做不到。
-
例如玻尔兹曼机(Boltzmann Machine,BM\text{Boltzmann Machine,BM}Boltzmann Machine,BM),它本质上就是一个由观测变量、隐变量构成的马尔可夫随机场:
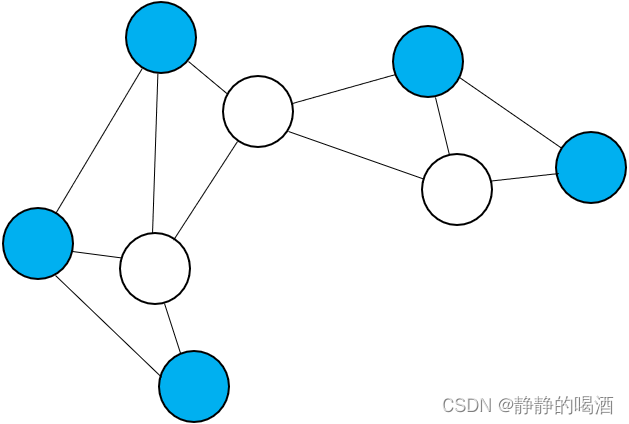
由于隐变量Z\mathcal ZZ、观测变量X\mathcal XX内部可能存在关联关系,因此关于该模型隐变量的后验概率P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X),干脆是无法用公式表达的。 -
还有一种就是以Sigmoid\text{Sigmoid}Sigmoid信念网络(Sigmoid Belief Network\text{Sigmoid Belief Network}Sigmoid Belief Network)为代表的包含隐变量、观测变量的贝叶斯网络:
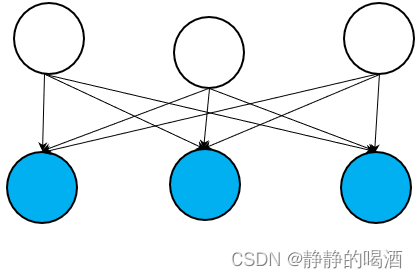
该模型同样无法对其联合概率分布P(X,Z)\mathcal P(\mathcal X,\mathcal Z)P(X,Z)进行分解,其核心原因是 指向同一观测变量的隐变量结点之间属于V\mathcal VV型结构。而V\mathcal VV型结构意味着隐变量结点之间不是相互独立的,因而无法分解。
关于V\mathcal VV型结构 -> 贝叶斯网络的条件独立性描述详见贝叶斯网络的结构表示,也称作Explain Away\text{Explain Away}Explain Away问题. -
最后一种情况就是上述两种情况的混合情况。代表模型是深度信念网络(Deep Belief Network,DBN\text{Deep Belief Network,DBN}Deep Belief Network,DBN),这里就不再赘述了。
由于受限玻尔兹曼机的条件约束,使得隐变量、观测变量内部均条件独立。但并不是说受限玻尔兹曼机比玻尔兹曼机性能更强大(powerful\text{powerful}powerful),而是玻尔兹曼机仅是理论上的产物,太过于理想化。在真实环境中没有实际作用;
相反受限玻尔兹曼机通过增加约束,使得隐变量的后验分布P(Z∣X)\mathcal P(\mathcal Z \mid \mathcal X)P(Z∣X)能够准确表示出来。相当于 放弃了模型复杂度,而去追求计算上的可行性。
与之相似的还有‘隐马尔可夫模型’中的齐次马尔可夫假设与观测独立性假设,它们都是放弃复杂度、追求计算可行性的典型示例。
可以看出,无向图模型无法直接表示后验概率的主要原因在于随机变量结点之间关联关系过于复杂,从而无法实现条件独立性;而有向图模型无法直接表示后验概率的主要原因在于随机变量之间的结构关系,从而无法实现条件独立性。
相关参考:
(系列二十五)近似推断1-介绍