基于知识蒸馏的两阶段去雨去雪去雾模型学习记录(三)之知识测试阶段与评估模块
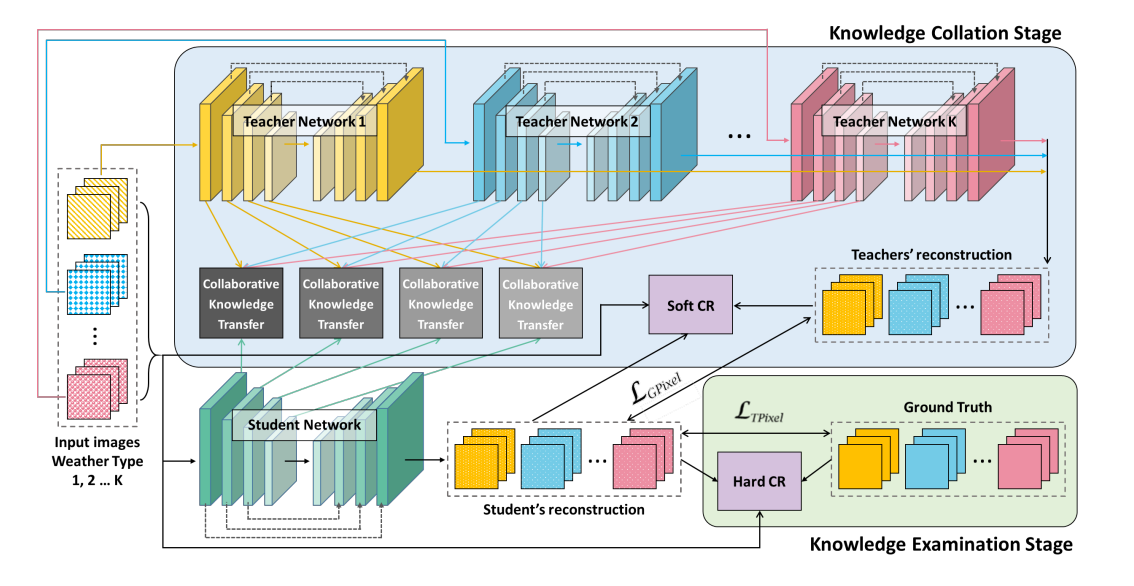
去雨去雾去雪算法分为两个阶段,分别是知识收集阶段与知识测试阶段,前面我们已经学习了知识收集阶段,了解到知识阶段的特征迁移模块(CKT)与软损失(SCRLoss),那么在知识收集阶段的主要重点便是HCRLoss(硬损失),事实上,知识测试阶段要比知识收集阶段简单,因为这个模块只需要训练学生网络即可。
模型创新点
在进行知识测试阶段的代码学习之前,我们来回顾一下去雨去雪去雾网络的创新点:
首先是提出两阶段的知识蒸馏网络,即构建三个教师网络与一个学生网络,设置总训练次数为250,其中前125个epoch教师网络与学生网络一同训练,这里的训练是指将图像输入教师网络,随后将教师网络的输出结果与中间特征图保留,将其作为真值指导学生网络进行训练。
其次便是提出知识迁移模块(CKT)该模块的作用是将教师网络的特征迁移到学生网络。
随后便是软损失与硬损失计算了,这个其实是知识蒸馏中的概念。
总体来看去雨去雾去雪网络的设计虽然较为新颖,但事实上就是知识蒸馏网络的架构,本着这一点,程序理解起来也就容易多了。
接下来开始代码的学习:
小插曲(算力不足)
首先需要指出,前面将batch-size设置为4,但却会报错:
RuntimeError: cuDNN error: CUDNN_STATUS_NOT_INITIALIZED
开始时博主以为是cuDNN与CUDA版本不匹配导致的,但后来一想不对呀,先前已经运行过呀,那么问题很可能便是batch出问题了,果然将batch改为3后就正常了,这是由于算力不足导致的,注意算力不足和显存不足还是有区别的。
将batch-size改为3后重新运行,开始知识测试阶段的探索。
知识测试阶段
事实上,知识测试阶段的实现与知识收集阶段几乎相同,并且要比知识收集阶段简单,其只是训练学生网络,并计算一个硬损失而已。
由于知识测试阶段与知识收集阶段几乎相同,因此有许多地方是重复的,这里博主便会简要介绍。
首先相同的是使用train_loader进行训练集的加载,并使用tqdm进行封装。
随后便是遍历过程,这个过程就要简单很多了,没有使用到教师网络,直接将图像输入学生网络进行预测即可,这里的学生网络与教师网络的构造是完全相同的,将结果分别计算L1损失与HCR_loss即可。不过需要注意的是由于该阶段不需要与教师网络进行特征迁移,因此就不需要返回中间特征图了,即设置return_feat=False
for target_images, input_images in pBar:if target_images is None: continuetarget_images = target_images.cuda()input_images = torch.cat(input_images).cuda()preds = model(input_images, return_feat=False)G_loss = criterion_l1(preds, target_images)HCR_loss = 0.2 * criterion_hcr(preds, target_images, input_images)total_loss = G_loss + HCR_loss
至于其他的基本就相同了,需要注意的是这里的batch设置为3。接下来记录一下数据的变化情况:
input_images:输入图像,torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度
target_images:目标图像(真值),torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度
preds:预测图像(去噪后的图像),torch.Size([3, 3, 224, 224])第一个3是指图像数量,第二个3是指通道维度

随后计算L1损失与HCRLoss,由于在学生网络中使用的事实上是混合数据集,即不区分去噪类型,因此输入图像等都是直接使用tesnor格式,而非list格式。
G_loss:tensor(0.5621, device='cuda:0', grad_fn=<L1LossBackward>)
HCRLoss
与SCRLoss相同,HCRLoss也是先将图像进行特征转换后再计算损失的
HCRLoss((vgg): Vgg19((slice1): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True))(slice2): Sequential((2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True))(slice3): Sequential((7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True))(slice4): Sequential((12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(17): ReLU(inplace=True)(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True))(slice5): Sequential((21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(24): ReLU(inplace=True)(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(26): ReLU(inplace=True)(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)))(l1): L1Loss()
)
HCRLoss:tensor(0.3274, device='cuda:0', grad_fn=<MulBackward0>)
评估模块
至此,知识测试阶段便完成了,随后便是模型评估了。这里默认设置评估时的batch-size为1,即每次输入一张图像。
所谓的评估指的是对学生网络的评估,该模块其实与知识测试阶段类似,不同之处在于这里是需要计算SSIM与PSNR的。至于其他则是完全相同,核心代码如下:
for target, image in pBar:if torch.cuda.is_available():image = image.cuda()target = target.cuda()pred = model(image) psnr_list.append(torchPSNR(pred, target).item())ssim_list.append(pytorch_ssim.ssim(pred, target).item())
由于batch-size设置为1,因此target为torch.Size([1, 3, 480, 640]),image也为torch.Size([1, 3, 480, 640]),这里需要注意的是,在训练阶段(包含知识收集与知识测试阶段),数据集中的图像都要转换为224x224的大小,而在评估阶段则不需要进行转换了,即使用的是原图像的大小。
直接将输入图输入模型,获的去噪后的图像pred大小为torch.Size([1, 3, 480, 640])
pred = model(image)

随后将预测图像与真值图像进行计算PSNR与SSIM
psnr_list.append(torchPSNR(pred, target).item())
ssim_list.append(pytorch_ssim.ssim(pred, target).item())
PSNR计算
@torch.no_grad()
def torchPSNR(prd_img, tar_img):if not isinstance(prd_img, torch.Tensor):prd_img = torch.from_numpy(prd_img)tar_img = torch.from_numpy(tar_img)imdff = torch.clamp(prd_img, 0, 1) - torch.clamp(tar_img, 0, 1)rmse = (imdff**2).mean().sqrt()ps = 20 * torch.log10(1/rmse)return ps
SSIM计算
class SSIM(torch.nn.Module):def __init__(self, window_size = 11, size_average = True):super(SSIM, self).__init__()self.window_size = window_sizeself.size_average = size_averageself.channel = 1self.window = create_window(window_size, self.channel)def forward(self, img1, img2):(_, channel, _, _) = img1.size()if channel == self.channel and self.window.data.type() == img1.data.type():window = self.windowelse:window = create_window(self.window_size, channel) if img1.is_cuda:window = window.cuda(img1.get_device())window = window.type_as(img1) self.window = windowself.channel = channelreturn _ssim(img1, img2, window, self.window_size, channel, self.size_average)
def ssim(img1, img2, window_size = 11, size_average = True):(_, channel, _, _) = img1.size()window = create_window(window_size, channel) if img1.is_cuda:window = window.cuda(img1.get_device())window = window.type_as(img1)return _ssim(img1, img2, window, window_size, channel, size_average)
将每个循环得到的psnr与ssim加入列表
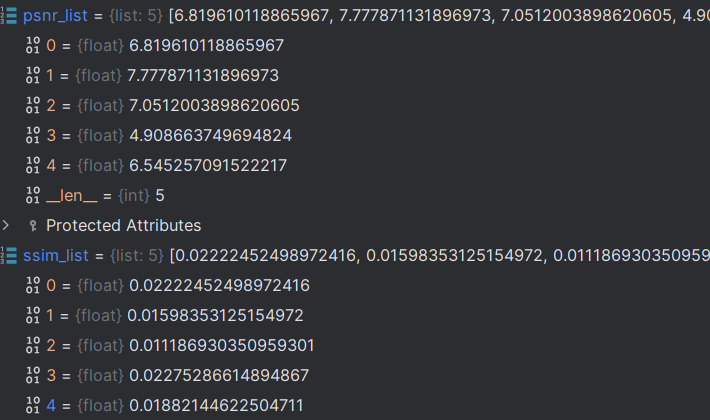
最后的PSNR与SSIM是对list中的所有值求平均:
print("PSNR: {:.3f}".format(np.mean(psnr_list)))
print("SSIM: {:.3f}".format(np.mean(ssim_list)))
至此,知识测试阶段与评估模块就讲解完成了,接下来博主将对该模型进行改进。