机器学习基础之《分类算法(8)—随机森林》
一、什么是集成学习方法
1、定义
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测
谚语:三个臭皮匠顶个诸葛亮、众人拾柴火焰高
二、什么是随机森林
1、定义
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定
森林:包含多个决策树的分类器
2、什么是众数
例如,如果你训练了5个树,其中有4个树的结果是True,1个数的结果是False,那么最终投票结果就是True
三、随机森林原理过程
1、如何随机
我们都是根据特征值和目标值进行预测的
我们面临的训练集是一致的,如何对同样的训练集去产生多棵树呢
两个随机:
训练集随机
特征随机
训练集:有N个样本,M个特征
2、训练集随机
bootstrap:随机有放回抽样
例子:[1, 2, 3, 4, 5]
新的树的训练集:
[2, 2, 3, 1, 5],先抽到2,把2放回去,可能又抽到2,把2放回去,抽到3,把2放回去。。。以此类推
从N个样本中随机有放回的抽样N个
3、特征随机
从M个特征中随机抽取m个特征
M >> m
4、算法归纳
训练集:有N个样本,M个特征
(1)从N个样本中随机有放回的抽样N个
(2)从M个特征中随机抽取m个特征,并且M 要远远大于 m
(3)M >> m,起到了降维的作用
5、为什么要这样做
因为笨的树都在乱蒙,聪明的树结果总是相同,最终会实现投票的众数结果是相对正确的
四、API
1、class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
随机森林分类器
n_estimators:设定要选几颗树,可选,默认=10,森林里的树木数量 120,200,300,500,800,1200
criterion:划分决策树的依据,可选,默认='gini'(基尼系数)
max_depth:树的深度,可选,默认=None 5,8,15,25,30
bootstrap:可选,默认=True,是否在构建树时使用放回抽样
max_features;默认=auto,每个决策树的最大特征数量,从M个特征中选择m个特征
If "auto", then max_features=sqrt(n_features).
If "sqrt", then max_features=sqrt(n_features) (same as "auto").
If "log2", then max_features=log2(n_features).
If None, then max_features=n_features.
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
五、随机森林预测案例
1、代码
在前一篇决策树的代码后面加上:
# 随机森林对泰坦尼克号乘客的生存进行预测from sklearn.ensemble import RandomForestClassifier# 实例化,和决策树用相同的参数
estimator = RandomForestClassifier(criterion='entropy',max_depth=8)
estimator.fit(x, y)
# 模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(m)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", n == y_predict)
# 方法2:计算准确率
score = estimator.score(m, n)
print("准确率为:\n", score)
2、运行结果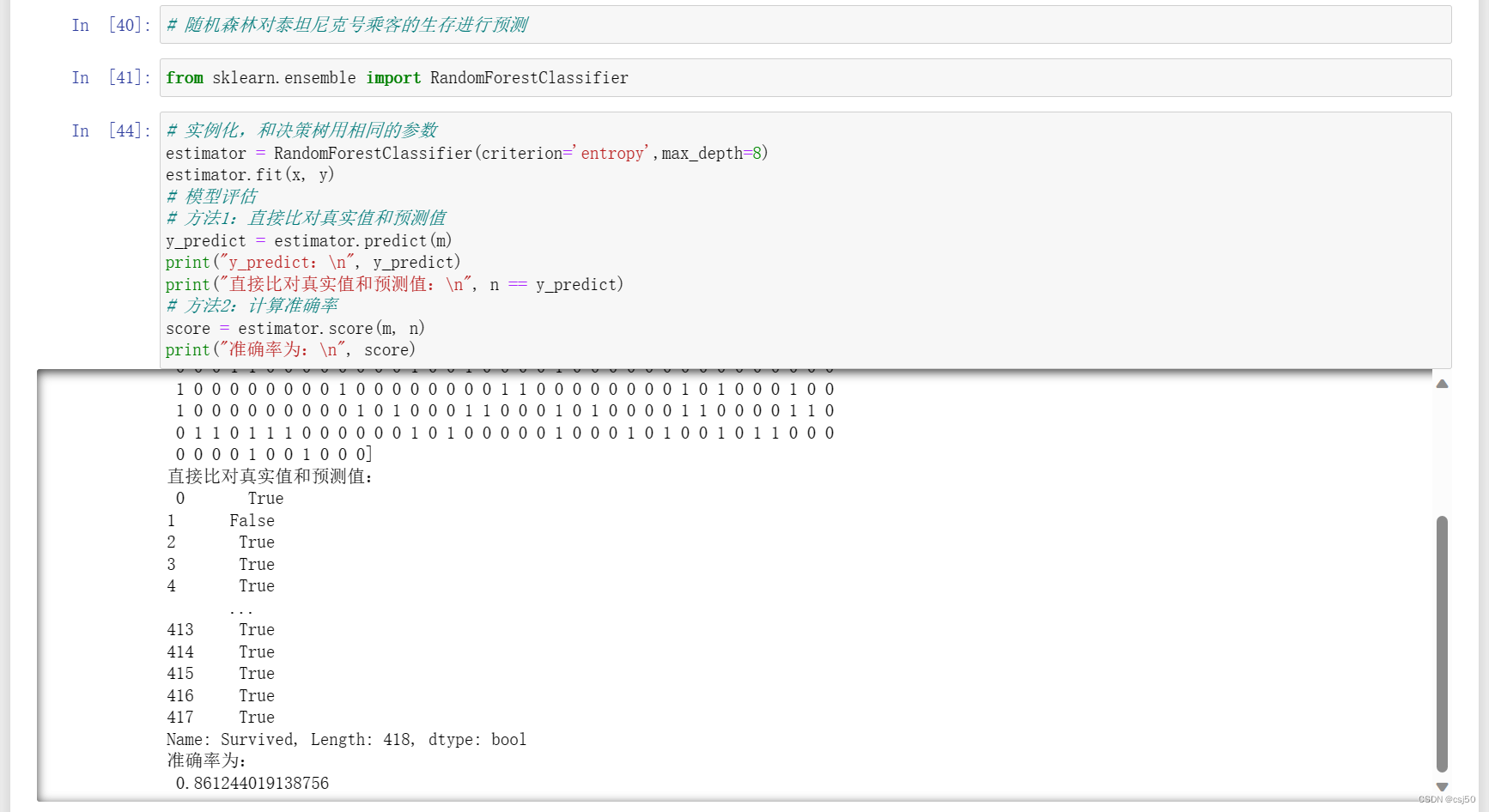
回顾下:
x是训练集的特征值,y是训练集的目标值,m是测试集的特征值,n是测试集的目标值
但是对比决策树的94%准确率,随机森林反而降低了
六、总结
1、在当前所有算法中,具有极好的准确率
2、能够有效地运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维
3、能够评估各个特征在分类问题上的重要性