mybatise-plus的id过长问题
一、问题情景
笔者在做mp插入数据库(id已设置为自增)操作时,发现新增数据的id过长,结果导致前端JS拿到的数据出现了精度丢失问题,原因是后端id的类型是Long。在网上查了一下,只要在该属性上加上如下注解就可以
@TableId(value = "id",type = IdType.AUTO)private Long id;但加入后,我又新增了一条数据,结果数据库id依旧是mp雪花算法生成的id
二、问题解决
查阅资料发现,是因为之前使用的还是过长的id,我们即使在数据库中直接添加数据,也会是长的自增id,只有重置id才可以
如何重置数据库id?笔者在论坛上查到以下方法
alter table 你的表名字 drop 你的表的主键;
alter table 你的表的名字 add 你的表的主键 int not null primary key auto_increment first;
效果如下

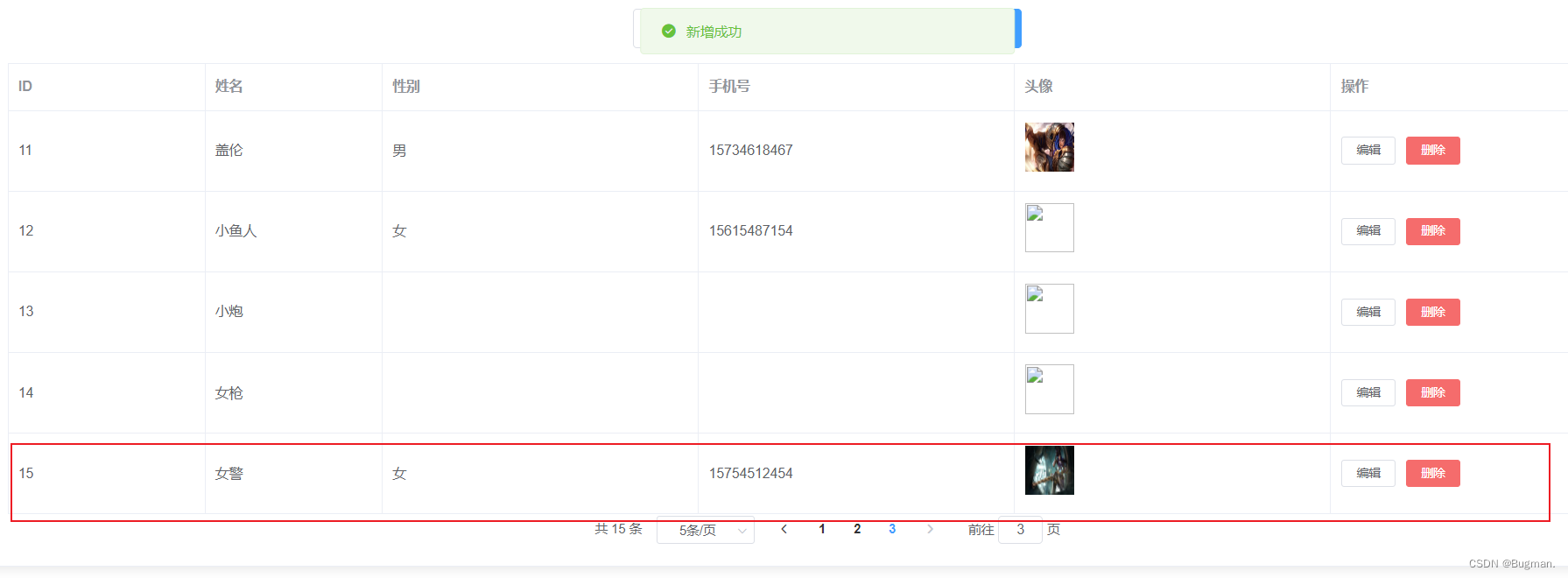
发现id果然重置了,新增一条数据,结果id自增结果是14,那么到这里问题就解决了。我重启项目,前端添加用户,数据库id是15,完成了表id自增效果。
效果如下
三、总结反思
mybatise-plus的雪花算法自增id,产生的id数太大,超过了JavaScript能够解析的最大范围,这样会导致精度丢失,前台获取到的id和后台数据库中不一致,从而导致无法进行增删改操作。当id定义为Long类型后,生成的id是一个19位数,而 js 能够支持解析的范围是在-9007199254740992到+9007199254740992之间,最大值才16位数。
如果前面不小心使用了mp自增策略,感觉id过长,想使用数据库自增id,就必须重置id,重置方法如下
alter table 你的表名字 drop 你的表的主键;
alter table 你的表的名字 add 你的表的主键 int not null primary key auto_increment first;