ElasticSearch - 基于 DSL 、JavaRestClient 实现数据聚合
目录
一、数据聚合
1.1、基本概念
1.1.1、聚合分类
1.1.2、特点
1.2、DSL 实现 Bucket 聚合
1.2.1、Bucket 聚合基础语法
1.2.2、Bucket 聚合结果排序
1.2.3、Bucket 聚合限定范围
1.3、DSL 实现 Metrics 聚合
1.4、基于 JavaRestClient 实现聚合
1.4.1、组装请求
1.4.2、解析响应
1.5、黑马旅游案例
1.5.1、需求
1.5.2、对接前端接口
1.5.3、编写 controller
1.5.4、添加 filters 接口
1.5.5、实现接口
一、数据聚合
1.1、基本概念
1.1.1、聚合分类
聚合(aggregations),就是用来对文档数据的统计分析和运算. 就像之前我们学习过的 mysql,也是有聚合功能,比如可以使用 avg 求平均值,max 求最大值等等,并且需要搭配着 group by 分组使用,而 es 也具备类似这些功能,并且更加丰富.
es 中聚合有以下三大类:
1. 桶(Bucket)聚合:用来对文档分组. 这就类似于 MySQL 中的 group by 了,取名为 “桶”,就好比对垃圾分类一样,对不同的文档起到分类分组的作用.
桶聚合分组最常用的有两个类型:
TermAggregation:按照文档字段值分组(这个实际上就和 mysql 中的 group by 效果是一样的).
Data Histogram:按照日期阶梯分组,例如一周为一组,或者一个月为一组.
2. 度量(Metric)聚合:对分组的每组文档数据做计算,比如 最大值、最小值、平均值等.
这里就和 mysql 中是一样的,比如 avg、max、min...
并且 es 这里还有一个特殊的度量聚合—— "stats",它可以用来同时求平均值、最大值、最小值等等.
3. 管道(pipeline)聚合:用来对其他聚合的结果做聚合.
比如对酒店数据按照品牌进行一个分组,也就是 bucket 聚合,接着算算不同品牌酒店的价格平均值怎么样,这个时候就需要使用到 度量聚合 了,之后如果还需要按照不同品牌价格的平均值进行排序,那么就需要对度量结果再次聚合了.
Ps:管道聚合的方式用到的比较少,不是后面学习的重点.
1.1.2、特点
这里不难看出,刚刚我们所讲到的聚合,是通过 term 对字符串进行分组,也就是说,将来是不能分词的,那么日期、数值、布尔类型就更不用说了.
因此参与聚合的字段一定是不能分词的.
1.2、DSL 实现 Bucket 聚合
1.2.1、Bucket 聚合基础语法
Bucket 聚合语法如下:
GET /索引库名/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"自定义聚合名": { //给聚合起个名字(自定义)"terms": { // 聚合的类型,按照品牌值聚合,所以选择 terms"field": "字段名", // 参与聚合的字段"size": 20 // 希望获取的聚合结果数量(值设置超过总数,也没有影响)}}}
}
可以看出,聚合的三要素:聚合名称、聚合类型、聚合字段.
例如要按照酒店的品牌对酒店信息进行分类.
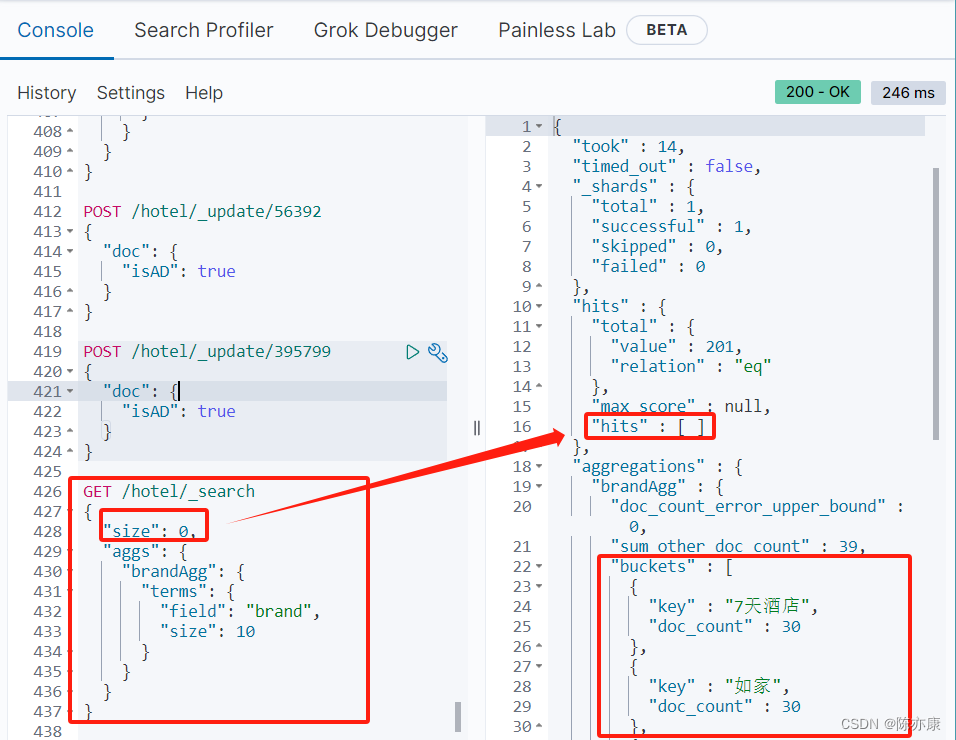
1.2.2、Bucket 聚合结果排序
默认情况下,Bucket 聚合会统计 Bucket 内的文档数量,记为 _count,并且按照 _count 降序排序.
例如对酒店品牌分组,并按照每个品牌的酒店数量按照升序排序:
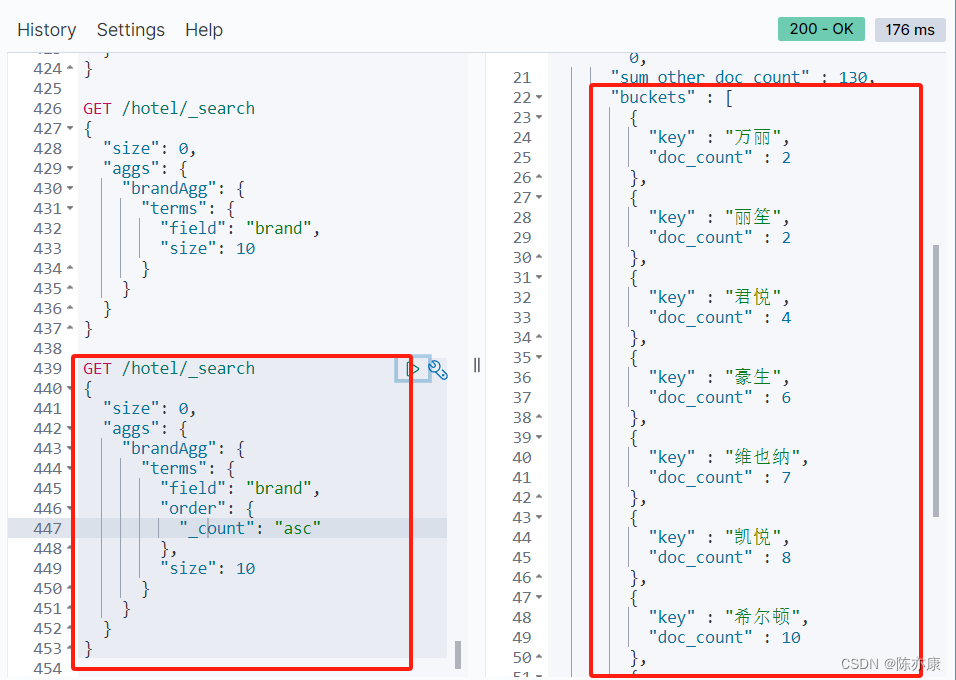
1.2.3、Bucket 聚合限定范围
默认情况下,Bucket 聚合对索引库的所有文档做聚合. 这里我们可以限定要聚合的文档范围,只需要添加 query 条件即可.
Ps:Bucket 聚合限定范围有一个好处:如果说你这个索引库中有上亿条数据,那么找个聚合对内存的消耗还是非常大的,因此,通过 query 限定搜索范围,就可以大大减少对内存的消耗.
例如搜索价格 小于等于 200 的酒店,并按照品牌分类.
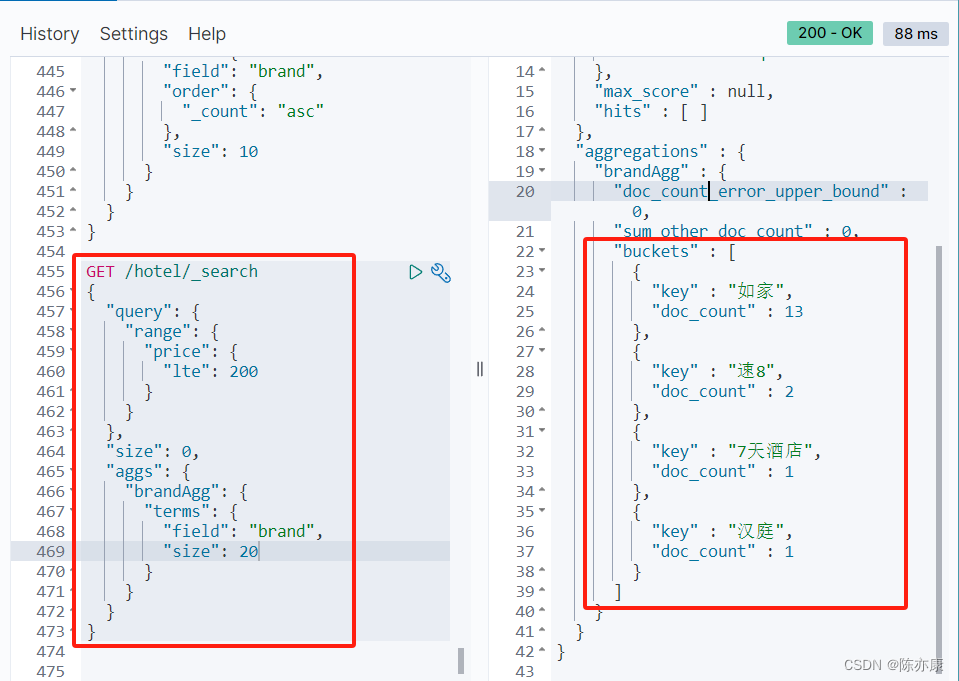
1.3、DSL 实现 Metrics 聚合
度量聚合就是在分组后对每组分别进行计算(需要在 aggs 中嵌套一个 aggs,进行子查询).
例如,搜索每个品牌的用户评分(字段是 score)的 min、max、avg 等值.
这里就可以使用 stats 聚合

当然,这里也可以根据用户评分平均值来升序排序,如下

1.4、基于 JavaRestClient 实现聚合
1.4.1、组装请求
示例:按照酒店的品牌对酒店信息进行分类.
@Testpublic void testAggregation() throws IOException {//1.准备 SearchRequestSearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().size(0);request.source().aggregation(AggregationBuilders.terms("brandAgg") //自定义聚合名.field("brand") //根据 brand 的字段聚合.size(10) //展示 10 组数据);//3.发送请求,接收响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析handlerResponse(response);}
可以对比着 DSL 语句来看

1.4.2、解析响应
//3.解析聚合查询Aggregations aggregations = response.getAggregations();Terms terms = aggregations.get("brandAgg");List<? extends Terms.Bucket> buckets = terms.getBuckets();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();System.out.println(key);}
这里可以对照的 DSL 语法来看

1.5、黑马旅游案例
1.5.1、需求
以下搜索页面的品牌、城市、星级信息不因该页面写死的,而是通过聚合索引库中的酒店数据得来的.
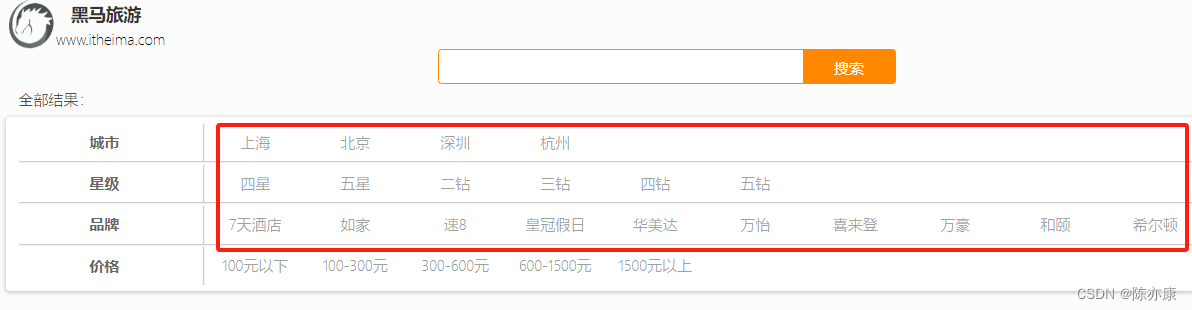
1.5.2、对接前端接口
前端页面会向服务器发起一个请求,查询品牌、城市、星级等字段的聚合结果.

这里请求参数和之前的 search 的 RequestParam 完全一样.

这里的响应返回的格式因该是:
{"城市": ["上海","北京"],"品牌": [....]...... }
就是 Map<String, List<String>> 的结构.
1.5.3、编写 controller
这里用来接收前端请求,代码如下.
@RequestMapping("/filters")public Map<String, List<String>> filters(@RequestBody RequestParams params) {return hotelService.filters(params);}
1.5.4、添加 filters 接口
public interface IHotelService extends IService<Hotel> {PageResult search(RequestParams params);Map<String, List<String>> filters(RequestParams params);}
1.5.5、实现接口
这里构建查询请求的时候先经过条件过滤(前端传入参数),然后分别对 品牌、城市、星级聚合.
Ps:这里一定要检查 品牌、星级、城市,构建索引库时的 type 类型是否为 keyword ,也就是不可分词. 否则不可以进行聚合.
@Overridepublic Map<String, List<String>> filters(RequestParams params) {try {//1.构造请求SearchRequest request = new SearchRequest("hotel");//2.准备参数// 1) 查询handlerBoolQueryBuilder(request, params);// 2) 设置 sizerequest.source().size(0);// 3)聚合buildAggregation(request);//3.发送请求,接收响应SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.处理响应Map<String, List<String>> result = new HashMap<>();Aggregations aggregations = response.getAggregations();List<String> brandAgg = getAggListByName(aggregations, "brandAgg");result.put("brand", brandAgg);List<String> cityAgg = getAggListByName(aggregations, "cityAgg");result.put("city", cityAgg);List<String> starAgg = getAggListByName(aggregations, "starAgg");result.put("starName", starAgg);return result;} catch (IOException e) {System.out.println("[HotelService] 酒店数据聚合失败!");e.printStackTrace();return null;}}private List<String> getAggListByName(Aggregations aggregations, String aggName) {Terms terms = aggregations.get(aggName);List<? extends Terms.Bucket> buckets = terms.getBuckets();List<String> brandList = new ArrayList<>();for (Terms.Bucket bucket : buckets) {String key = bucket.getKeyAsString();brandList.add(key);}return brandList;}private void buildAggregation(SearchRequest request) {// 1) 聚合品牌request.source().aggregation(AggregationBuilders.terms("brandAgg").field("brand").size(100));// 2) 聚合城市request.source().aggregation(AggregationBuilders.terms("cityAgg").field("city").size(100));//3) 聚合星级request.source().aggregation(AggregationBuilders.terms("starAgg").field("starName").size(100));}
