【论文阅读】(CVPR2023)用于半监督医学图像分割的双向复制粘贴
目录
- 前言
- 方法
- BCP
- Mean-teacher and Traning Strategy
- Pre-Training via Copy-Paste
- Bidirectional Copy-Paste Images
- Bidirectional Copy-Paste Supervisory Signals
- Loss Function
- Testing Phase
- 结论

先看这个图,感觉比较清晰。它整个的思路就是把有标签的图片和无标签的图片拼在一起,送入学生网络,输出 Q o u t Q^{out} Qout Q i n Q^{in} Qin。把无标签的图片送入教师网络得到输出 Y ~ p u \tilde{Y}^{u}_{p} Y~pu Y ~ q u \tilde{Y}^{u}_{q} Y~qu。 Y ~ p u \tilde{Y}^{u}_{p} Y~pu Y ~ q u \tilde{Y}^{u}_{q} Y~qu与GT与输入一样拼接得到 Y o u t Y^{out} Yout Y i n Y^{in} Yin作为监督信号,监督模型训练。student网络的参数经过EMA滑动移动平均得到的参数来更新teacher模型。
问题:
- 怎么选择拼接的区域的?
- label图像是否得到了充分利用?因为只使用了label image的一部分。
- 这样做的原理是什么?是假设labeled的image和unlabeled的image在同一个分布下吗?
- 损失函数有没有改进?
- 之前没有学习过teacher-student model,参数是怎么更新的用的什么函数?
- 这样做与原来半监督的方法相比,优势是什么?
前言
问题:半监督医学图像分割,有标记数据分布与无标记数据分布之间存在经验失配的问题。如果将有标签数据和无标签数据分开处理或以不一致的方式处理,从有标签数据中学习到的只是可能被大量丢弃。
方法:BCP在一个简单的Mean Teacher架构下,鼓励未标记数据从有标记的数据中向内和向外两个方向学习综合的共同语义。
对标记和未标记的数据一直学习过程可以在很大程度上减少经验分布差距。
具体:将标记图像(前景)中的随机裁剪复制粘贴到未标记图像(背景)中,未标记图像(前景)随机裁剪粘贴到标记图像(背景)中。
效果:在有5 %标注数据的ACDC数据集上, Dice性能提升超过21 %。足够好。
方法

这个图是给我们展示半监督倾斜设置下的失配问题。我们假设训练数据是从(a)这个分布中获得的,但是有标签的和没有标签的样本的分布分别为(b)和©。很难有很少的标记数据来构建整个数据集的精确分布。(d)通过使用BCP,标记和未标记的经验分布是对齐的,但是其他方法例如SSNet或交叉未标记的数据复制粘贴无法解决经验分布不匹配的问题。

可以看出BCP在标记数据和未标记数据性能差距小。

具体的数学表达式大家看原文吧。
这里简单介绍一下思想和方法。
BCP
Mean-teacher and Traning Strategy
首先使用标记的数据来预训练模型,然后使用预训练模型作为teacher network,给伪标记的图像生成伪标签。每次迭代中首先通过随机梯度下降来优化学生网络参数Θs。最后,我们使用学生参数 Θs 的 EMA 更新教师网络参数 Θt。最后测试使用的Θs。
Pre-Training via Copy-Paste
对标记数据进行了复制粘贴增强以训练监督模型,监督模型将在自我训练期间为未标记的数据生成伪标签。效果:增强了分割性能。
Bidirectional Copy-Paste Images
长话短说,是由一个0中心标签的M矩阵,这个M矩阵中间部分是0,四周是1(指示体素来自前景图片还是背景图片)。
x i n = x j l ⊙ M + x p u ⊙ ( 1 − M ) x^{in}=x^{l}_j\odot M+x^{u}_p\odot (1-M) xin=xjl⊙M+xpu⊙(1−M)
M是0中心,所以点乘M是得到的边界,点乘(1-M)得到的是中心。和图上的情况一样 x j l x^{l}_j xjl中间部分复制粘贴到 x p u x^{u}_p xpu图像上。
Bidirectional Copy-Paste Supervisory Signals
监督信号也通过BCP生成。伪标签是通过在 P u P_u Pu上使用公共阈值0.5来确定的,对于二进制分割任务,或者在 Pu 上对多类分割任务采用 argmax 操作来确定。最终的伪标签 ̃ Yu 是通过选择 ̂ Yu 的最大连接分量获得的,这将有效地去除异常体素。
将伪标签和真实标签和student network输入的图片一样进行BCP。
Loss Function
标记图像的GT比未标记图像的伪标签准确,所以有一个系数 α \alpha α来控制标记图像的体素和未标记图像的体素对loss的贡献大小。
损失函数计算也用到 M M M。损失函数是Dice loss和Cross-entropy loss的线性组合。
预测是用student network预测的。
计算完loss,经过梯度反向传播和优化器更新,更新student network的参数,之后通过EMA更新teacher network。
Testing Phase
Qtest = F(Xtest; ̂ Θs)
其中̂ Θs是训练良好的学生网络参数。最终的标签图可以通过Qtest轻松确定,进行后处理即可。
后面讲了一些参数的选择,一些实验结果。
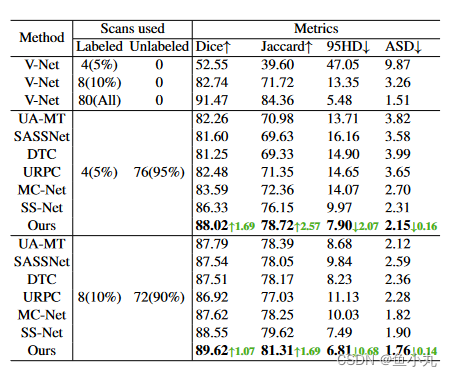
结论
总结:我们使用BCP,这减少了标记和未标记数据之间的分布差距。获得了很好的性能。
局限:我们没有专门设计一个模块来增强局部属性学习。虽然性能优于所有竞争对手,对比度极低的目标部件仍然难以很好地细分。