yolox相关
yolox
- YOLOX
- YOLOX-DarkNet53
- yolov3作为baseline
- 输入端
- Strong data augmentation
- Mosaic数据增强
- MixUp数据增强
- 注意
- Backbone
- Neck
- Prediction层
- Decoupled head
- Decoupled Head 细节
- Anchor-free
- Anchor Based方式
- Anchor Free方式
- 标签分配
- 初步筛选
- 精细化筛选 SimOTA
- SimOTA
- Other Backbones
- Yolox-s、l、m、x系列
参考:
B站论文详解
YOLOX解读与感想
江大白 深入浅出Yolo系列之Yolox核心基础完整讲解
windows10搭建YOLOx环境 训练+测试+评估
江大白 深入浅出Yolox之自有数据集训练超详细教程
YOLOX
yolox主要提出解耦Head、anchor-free和SimOTA
Yolox-s是在Yolov5-s的基础上,进行的改进
YOLOX-DarkNet53
Yolox-Darknet53是在Yolov3的基础上,进行的改进
yolov3作为baseline
用BCE的loss训练分类和objectness置信度 的分支 ,用IOU的loss训练Regesison。对IOU的改进可以大大提高yolo系列网络收敛的速度,成为改进yolov3 的标配。
会使用一些mosaic和RandomHorizontalFlip的augmentation的方式
FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。
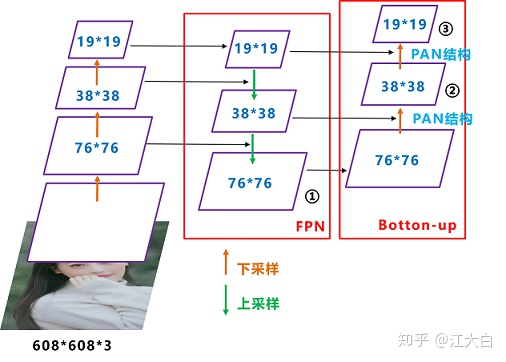
而在Yolov4、Yolov5、甚至Yolox-s、l等版本中,都是采用FPN+PAN的形式,这里需要注意。
Yolov3_spp网络
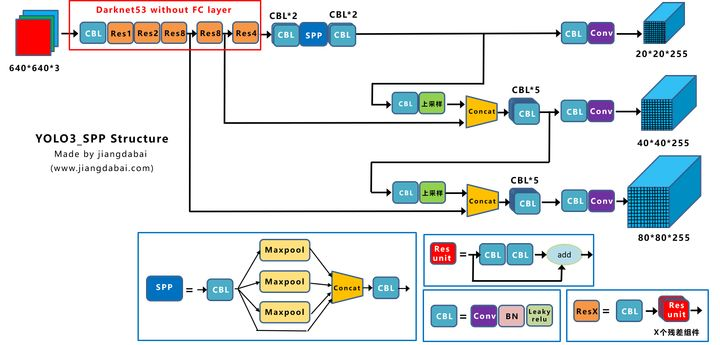
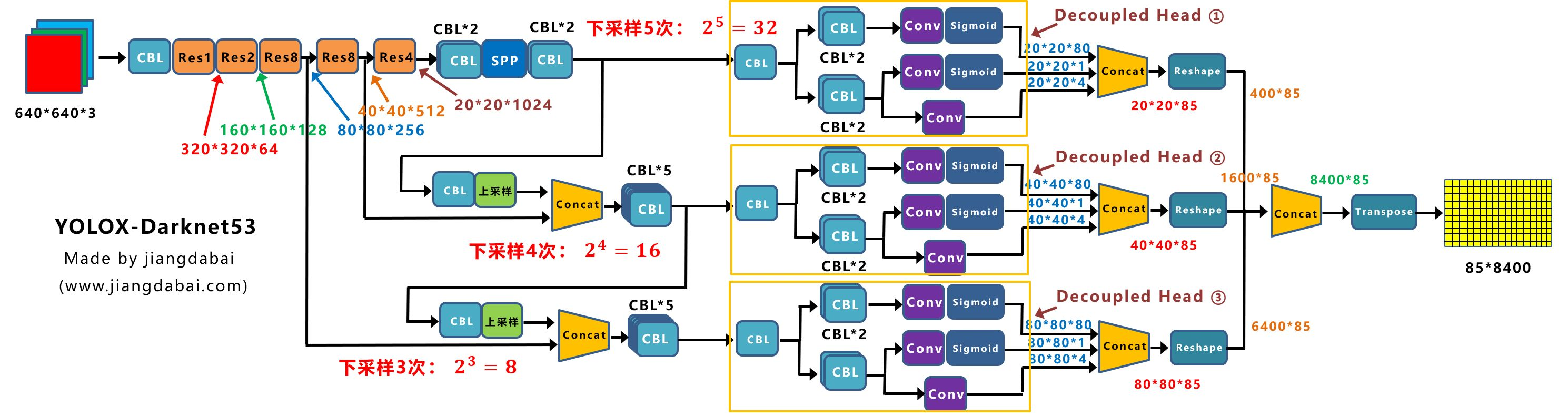
Yolox-Darknet53网络结构
对Yolox-Darknet53网络结构进行拆分,变为四个板块:
① 输入端:Strong augmentation数据增强
② BackBone主干网络:主干网络没有什么变化,还是Darknet53。
③ Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
④ Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
输入端
Strong data augmentation
加入了 Mosaic 和 MixUp,和yolov5一样。
Mosaic数据增强
随机缩放、随机裁剪、随机排布
MixUp数据增强
将Image_1和Image_2,加权融合
注意
在最后的15个epoch关掉。
由于采取了更强的数据增强方式,使用强大的数据增强后,发现ImageNet预训练没有用了,所以所有的模型都是从头训练。
Backbone
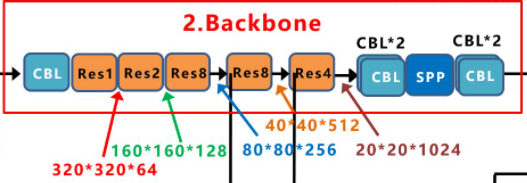
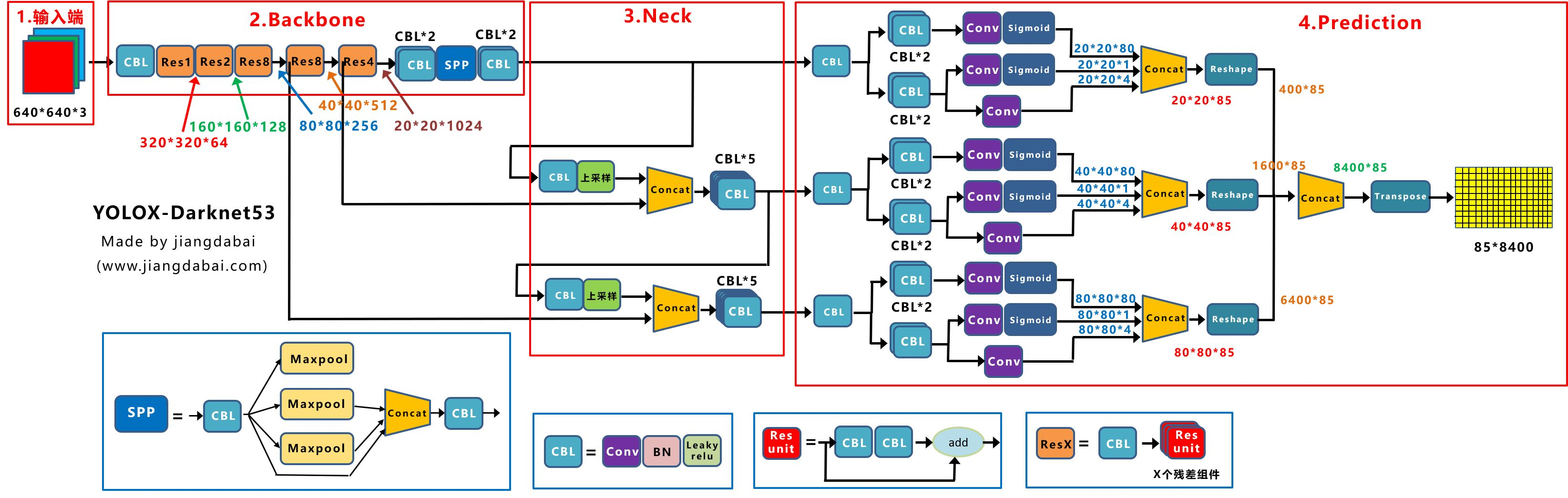
Yolox-Darknet53的Backbone主干网络,和原本的Yolov3 baseline的主干网络都是一样的
Neck
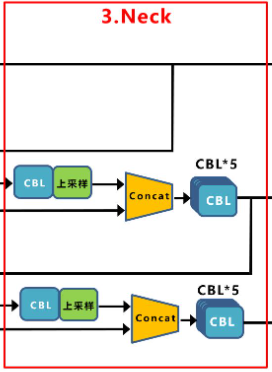
Yolox-Darknet53和Yolov3 baseline的Neck结构,也是一样的,都是采用FPN的结构进行融合
FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。
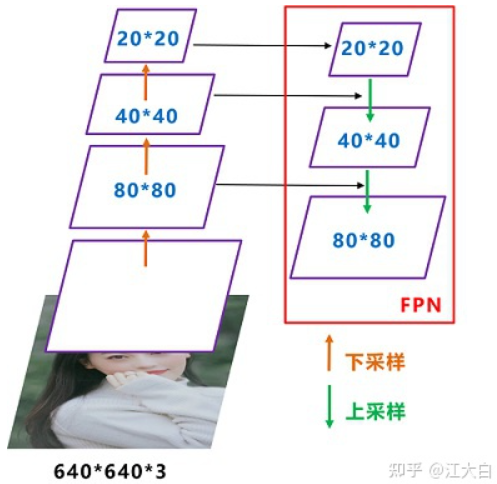
而在Yolov4、Yolov5、甚至后面讲到的Yolox-s、l等版本中,都是采用FPN+PAN的形式,这里需要注意。
Prediction层
输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算。
Decoupled head
随着yolo系列的backbone和特征金字塔(FPN,PAN)不断演变,他们都是耦合。实验表明,耦合探测头可能会损害性能
Decoupled head对于端到端版本的YOLO至关重要,才能进行anchor free。
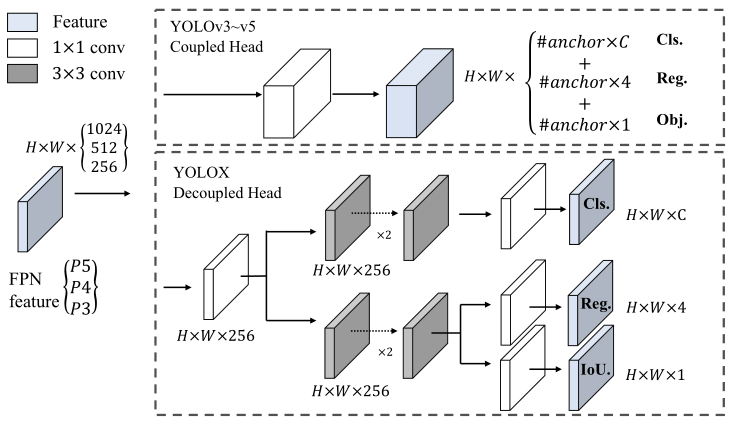
对于每一层FPN特征。包含一个1×1 conv层以减小通道尺寸(将特征通道减少到256),然后是两个分别具有两个3×3 conv层的并行分支(分别用于分类和回归),IoU分支添加到回归分支上。
yolov3~v5就是把FPN的输出放到head里面输出,这个矩阵的大小是HW(C+4+1)

上图右面的Prediction中,我们可以看到,有三个Decoupled Head分支。
但是需要注意的是:将检测头解耦,会增加运算的复杂度。
因此作者经过速度和性能上的权衡,最终使用 1个1x1 的卷积先进行降维,并在后面两个分支里,各使用了 2个3x3 卷积,最终调整到仅仅增加一点点的网络参数。
Decoupled Head 细节
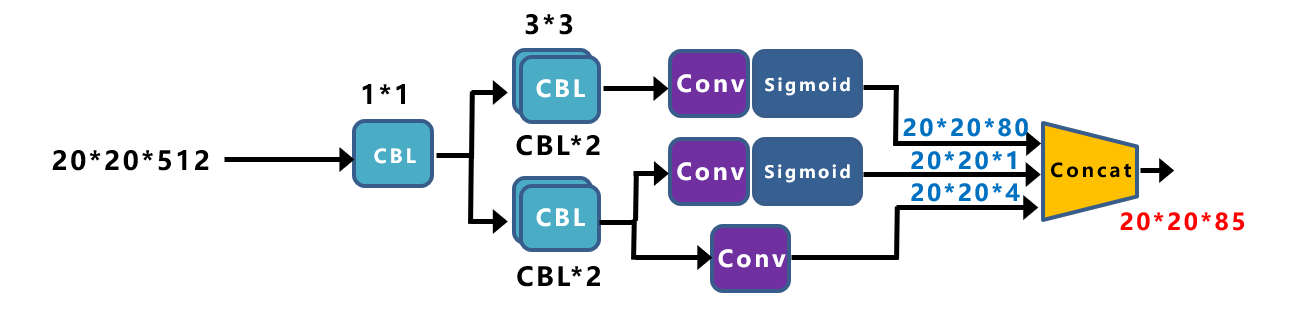
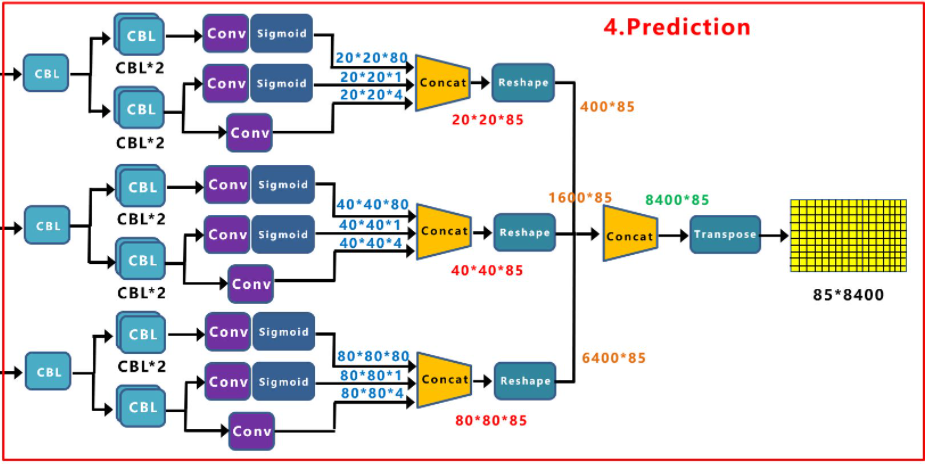
将Yolox-Darknet53中,Decoupled Head①提取出来,经过前面的Neck层,这里Decouple Head①输入的长宽为2020。
从图上可以看出,Concat前总共有三个分支:
(1)cls_output:主要对目标框的类别,预测分数。因为COCO数据集总共有80个类别,且主要是N个二分类判断,因此经过Sigmoid激活函数处理后,变为202080大小。
(2)obj_output:主要判断目标框是前景还是背景,因此经过Sigmoid处理好,变为20201大小。
(3)reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测,因此大小为20204。
最后三个output,经过Concat融合到一起,得到2020*85的特征信息。
Decoupled Head②输出特征信息,并进行Concate,得到404085特征信息。
Decoupled Head③输出特征信息,并进行Concate,得到808085特征信息。
再对①②③三个信息,进行Reshape操作,并进行总体的Concat,得到840085的预测信息。
并经过一次Transpose,变为858400大小的二维向量信息。
这里的8400,指的是预测框的数量,而85是每个预测框的信息(reg,obj,cls)。
有了预测框的信息,下面了解如何将这些预测框和标注的框,即groundtruth进行关联,从而计算Loss函数,更新网络参数
Anchor-free
Anchor Based方式
Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。这时,就要设置一些Anchor规则,将预测框和标注框进行关联。从而在训练中,计算两者的差距,即损失函数,再更新网络参数。
比如在yolov3_spp,最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。
Anchor Free方式
锚定机制增加了检测头的复杂性,以及每个图像的预测数量。
减少了设计参数的数量
每个位置的预测从三个变成一个,同时输出四个值:网格左上角的两个偏移量以及预测框的高度和宽度。
直接把每个物体的中心点当做正样本。预先定义比例范围,以指定每个对象的FPN级别
yolox把原来的yolo的anchor-based框架改成了anchor-free框架。
最后黄色的858400,不是类似于Yolov3中的Feature Map,而是特征向量。当输入为640640时,最终输出得到的特征向量是85*8400。
将前面Backbone中,下采样的大小信息引入进来。最上面的分支,下采样了5次,2的5次方为32。并且Decoupled Head①的输出,为202085大小。
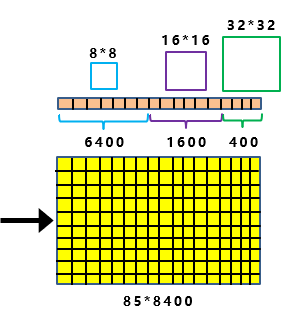
因此如上图所示:
最后8400个预测框中,其中有400个框,所对应锚框的大小,为3232。
同样的原理,中间的分支,最后有1600个预测框,所对应锚框的大小,为1616。
最下面的分支,最后有6400个预测框,所对应锚框的大小,为8*8。
当有了8400个预测框的信息,每张图片也有标注的目标框的信息。
这时的锚框,就相当于桥梁。
这时需要做的,就是将8400个锚框,和图片上所有的目标框进行关联,挑选出正样本锚框。
而相应的,正样本锚框所对应的位置,就可以将正样本预测框,挑选出来。
这里采用的关联方式,就是标签分配。
标签分配
当有了8400个Anchor锚框后,这里的每一个锚框,都对应85*8400特征向量中的预测框信息。
不过需要知道,这些预测框只有少部分是正样本,绝大多数是负样本。
需要利用锚框和实际目标框的关系,挑选出一部分适合的正样本锚框。
如何挑选正样本锚框,涉及到两个关键点:初步筛选、SimOTA
初步筛选
指出了yolov3里的问题,仅为每个对象选择一个正样本(中心位置),同时忽略其他高质量预测框,但是这些高质量预测框是有助于网络收敛的。
Multi positives:将中心3×3区域指定为正(落在这个区域所有的预测框),在FCOS中也称为“中心采样”
初步筛选的方式主要有两种:根据中心点来判断、根据目标框来判断
根据中心点来判断:寻找anchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors。groundtruth的矩形框范围确定了,再根据范围去选择适合的锚框。
根据目标框来判断:以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。groundtruth正方形范围确定了,再根据范围去挑选锚框。
经过上面两种挑选的方式,就完成初步筛选了,挑选出一部分候选的anchor,进入下一步的精细化筛选。
精细化筛选 SimOTA
主要分为四个阶段:
a.初筛正样本信息提取
b.Loss函数计算
c.cost成本计算
d.SimOTA求解
SimOTA
label assignment 标签分配四个关键
1). loss/quality aware,
2). center prior,
3). dynamic number of positive anchors for each ground-truth (abbreviated as dynamic top-k),
4). global view.
满足这四个条件就会有比较好的 label assignment
流程如下:
设置候选框数量
通过cost挑选候选框
过滤共用的候选框
Loss计算(可以看到:检测框位置的iou_loss,Yolox中使用传统的iou_loss,和giou_loss两种,可以进行选择。而obj_loss和cls_loss,都是采用BCE_loss的方式。)
Other Backbones
除了DarkNet53之外还测试了其他不同尺寸的主干上的YOLOX
YOLOv5中改进的CSPNet
Tiny and Nano detectors
模型大小和数据扩充
Yolox-s、l、m、x系列
Yolov5s的网络结构
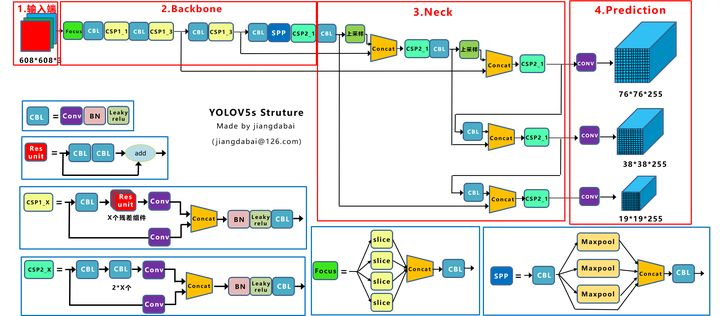
Yolox-s的网络结构
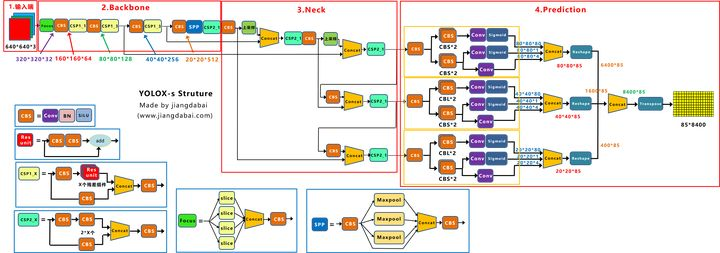
Yolox-s:
(1)输入端:在Mosac数据增强的基础上,增加了Mixup数据增强效果;
(2)Backbone:激活函数采用SiLU函数;
(3)Neck:激活函数采用SiLU函数;
(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。
官方数据集结果
