YOLOv7改进:GAMAttention注意力机制
1.背景介绍
为了提高各种计算机视觉任务的性能,人们研究了各种注意机制。然而,以往的方法忽略了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深度神经网络的性能。我们沿着卷积空间注意子模块引入了用于通道注意的多层感知器3D置换。
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information

GAMAttention注意力机制原理图
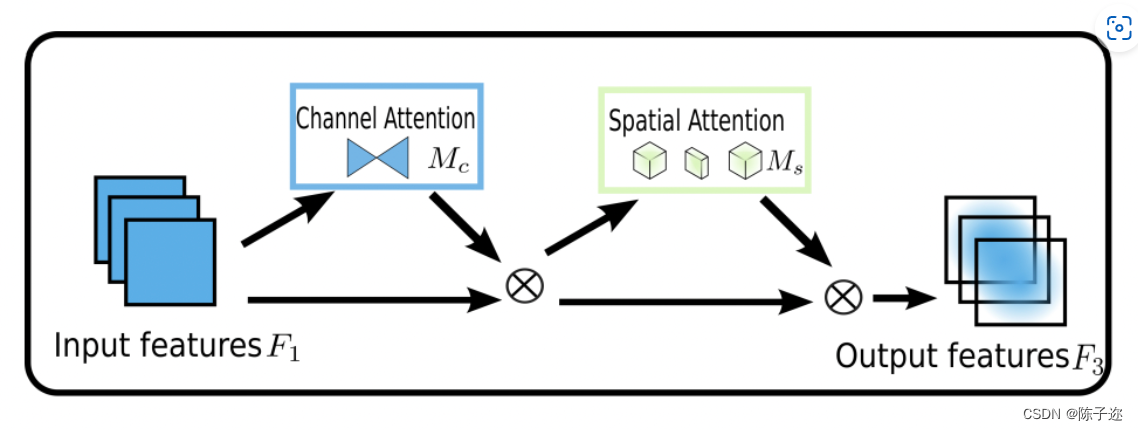
对于ImageNet-1K,我们将图像预处理为224×224(He et al.[2016])。我们包括ResNet18和ResNet50(He et al.[2016]),以验证不同网络深度的方法推广。对于ResNet50,我们将其与群卷积进行了比较,以防止参数显著增加。我们将起始学习率设置为0.1,并每隔30个阶段降低一次。我们总共使用90个训练时段。在空间注意子模块中,我们将第一个块的第一步从1切换到2,以匹配特征的大小。为了进行公平比较,CBAM保留了其他设置,包括在空间注意子模块中使用最大池。3 MobileNet V2是用于图像分类的最高效的轻量级模型之一。我们对MobileNet V2使用相同的ResNet设置,只是使用了0.045的初始学习率和4×10的权重衰减−5.对ImageNet-1K的评估如表所示。它表明GAM可以稳定地提高不同神经架构的性能。尤其是对于ResNet18,GAM以更少的参数和更好的效率优于ABN。
相关实验结果
对ImageNet-1K的评估如表2所示,它表明GAM可以稳定地提高不同神经体系结构的性能。特别是,对于ResNet18,GAM的性能优于ABN,参数更少,效率更高。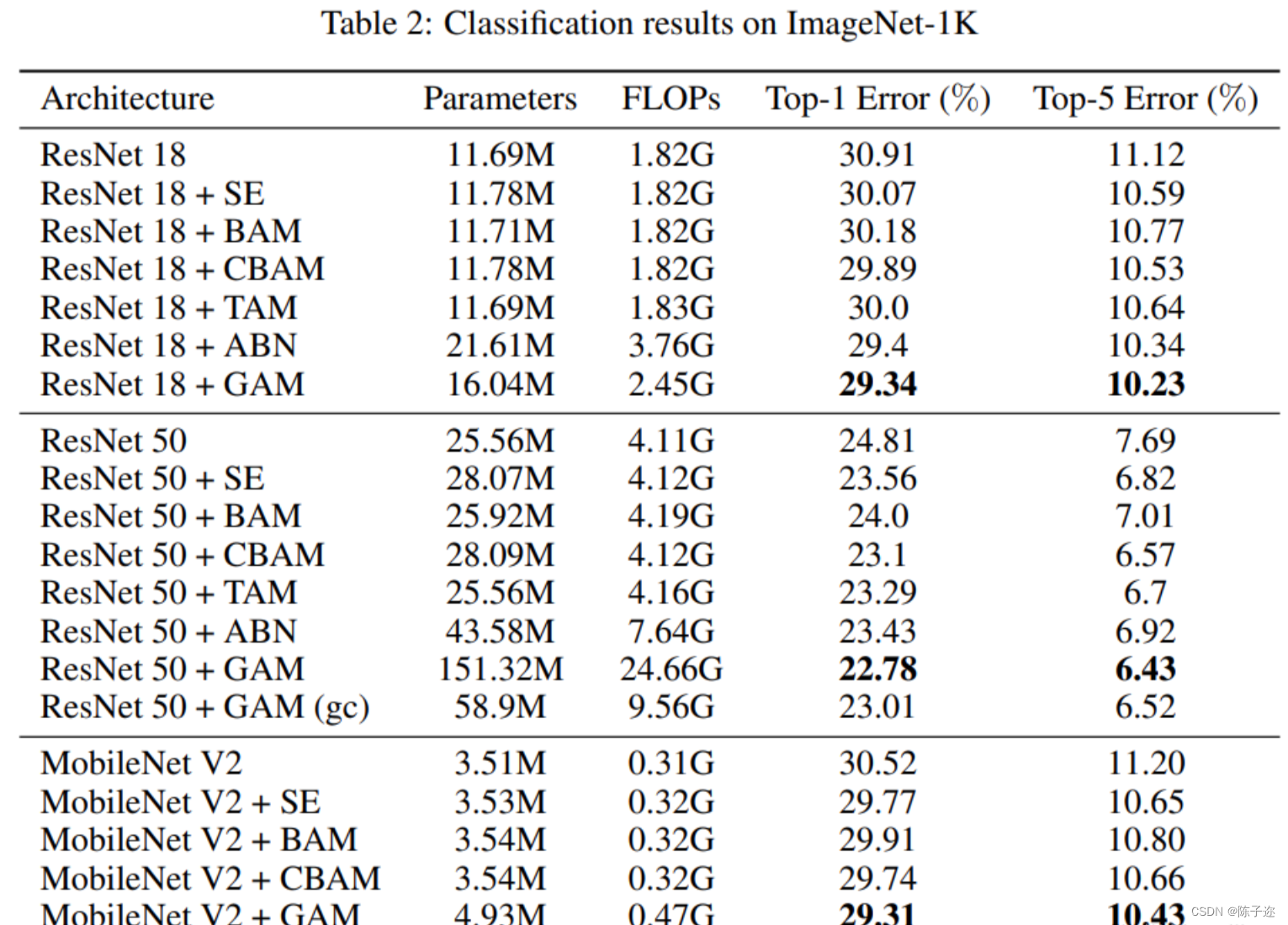
为了更好地理解空间注意和通道注意分别对消融的贡献,我们通过开启和关闭一种方式进行了消融研究。例如,ch表示空间注意力被关闭,而频道注意力被打开。SP表示通道关注已关闭,空间关注已打开。结果如表3所示。我们可以在两个开关实验中观察到性能的提高。结果表明,空间关注度和通道关注度对性能增益均有贡献。请注意,它们的组合进一步提高了性能。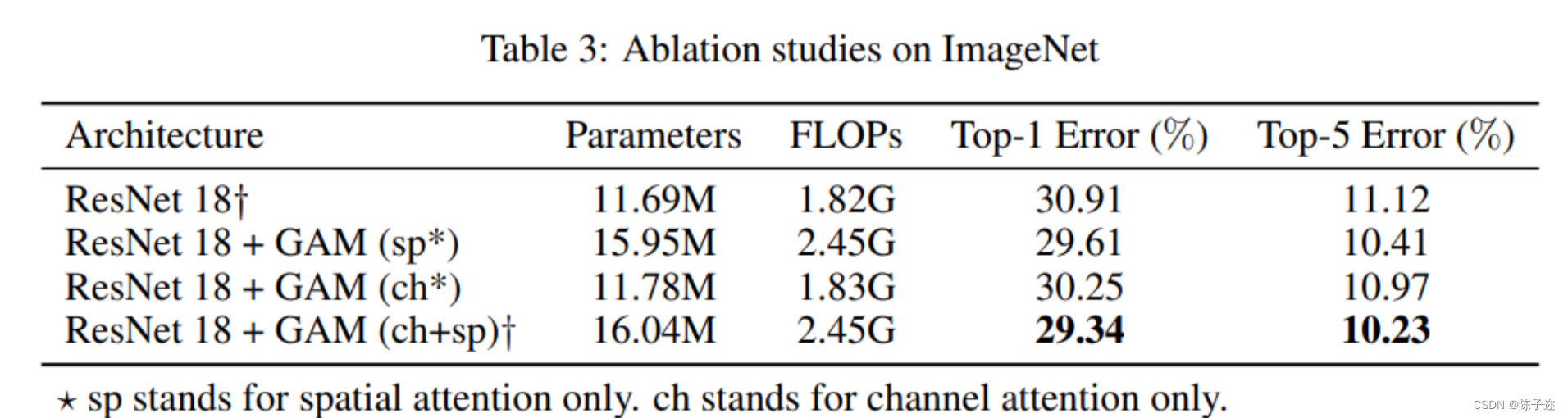
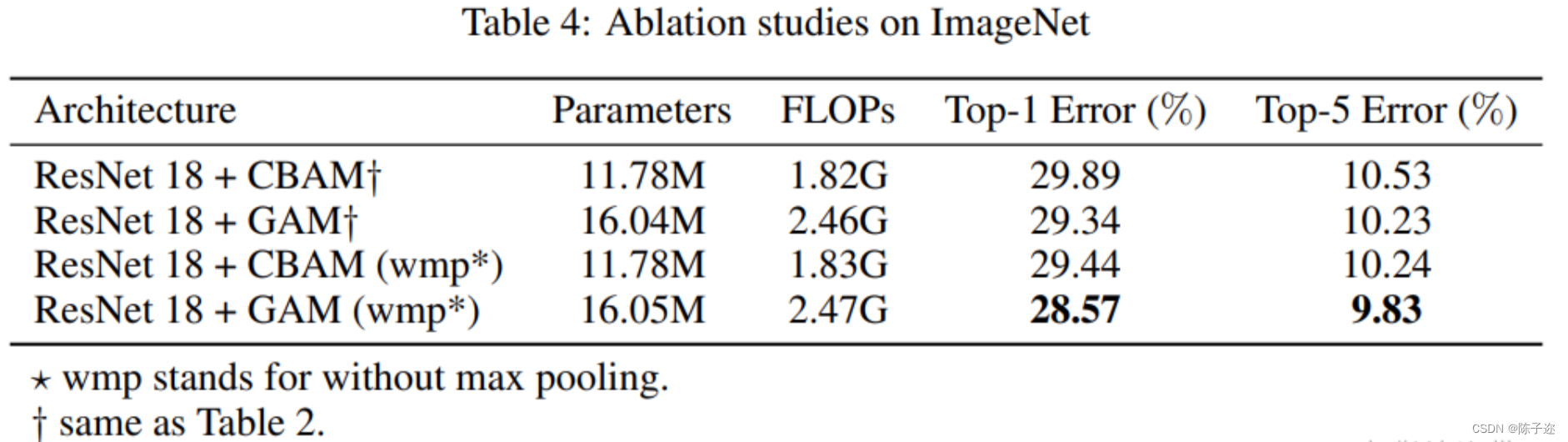
将GAM与CBAM在使用和不使用ResNet18最大池化的情况下进行比较。表4显示了结果。可以观察到,在这两种情况下,我们的方法都优于CBAM。
2.YOLOv7改进方法
2.1增加以下GAMAttention.yaml文件
# YOLOv7 🚀, GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone by yoloair
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4 [-1, 1, CNeB, [128]], [-1, 1, Conv, [256, 3, 2]], [-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], [-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]],[-1, 1, CNeB, [1024]],[-1, 1, Conv, [256, 3, 1]],]# yolov7 head by yoloair
head:[[-1, 1, SPPCSPC, [512]],[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[31, 1, Conv, [256, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3C2, [128]],[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[18, 1, Conv, [128, 1, 1]],[[-1, -2], 1, Concat, [1]],[-1, 1, C3C2, [128]],[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, GAMAttention, [128]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 44], 1, Concat, [1]],[-1, 1, C3C2, [256]], [-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]], [[-1, -3, 39], 1, Concat, [1]],[-1, 3, C3C2, [512]],# 检测头 -----------------------------[49, 1, RepConv, [256, 3, 1]],[55, 1, RepConv, [512, 3, 1]],[61, 1, RepConv, [1024, 3, 1]],[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]
2.2common.py配置
./models/common.py文件增加以下模块
import numpy as np
import torch
from torch import nn
from torch.nn import initclass GAMAttention(nn.Module):#https://paperswithcode.com/paper/global-attention-mechanism-retain-informationdef __init__(self, c1, c2, group=True,rate=4):super(GAMAttention, self).__init__()self.channel_attention = nn.Sequential(nn.Linear(c1, int(c1 / rate)),nn.ReLU(inplace=True),nn.Linear(int(c1 / rate), c1))self.spatial_attention = nn.Sequential(nn.Conv2d(c1, c1//rate, kernel_size=7, padding=3,groups=rate)if group else nn.Conv2d(c1, int(c1 / rate), kernel_size=7, padding=3), nn.BatchNorm2d(int(c1 /rate)),nn.ReLU(inplace=True),nn.Conv2d(c1//rate, c2, kernel_size=7, padding=3,groups=rate) if group else nn.Conv2d(int(c1 / rate), c2, kernel_size=7, padding=3), nn.BatchNorm2d(c2))def forward(self, x):b, c, h, w = x.shapex_permute = x.permute(0, 2, 3, 1).view(b, -1, c)x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)x_channel_att = x_att_permute.permute(0, 3, 1, 2)x = x * x_channel_attx_spatial_att = self.spatial_attention(x).sigmoid()x_spatial_att=channel_shuffle(x_spatial_att,4) #last shuffle out = x * x_spatial_attreturn out def channel_shuffle(x, groups=2):B, C, H, W = x.size()out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()out=out.view(B, C, H, W) return out
2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m is GAMAttention:c1, c2 = ch[f], args[0]if c2 != no:c2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]
修改完成