【GPU编程】Visual Studio创建基于GPU编程的项目
vs创建基于GPU编程的项目
- 🍊前言
- 🐸方法一-CUDA Runtime生成
- 😝debug设置
- 🍅方法二-空项目配置
- 🍉🍉🍉代码验证
🍊前言
cuda以及cudnn的安装以及系统环境变量的配置默认已经做完。如果没有安装好配置好的,可以参考其他的博客。本博客只为记录在完成以上配置后,如何在vs端创建GPU编程的项目。
🐸方法一-CUDA Runtime生成
我们打开vs,点击创建新项目:
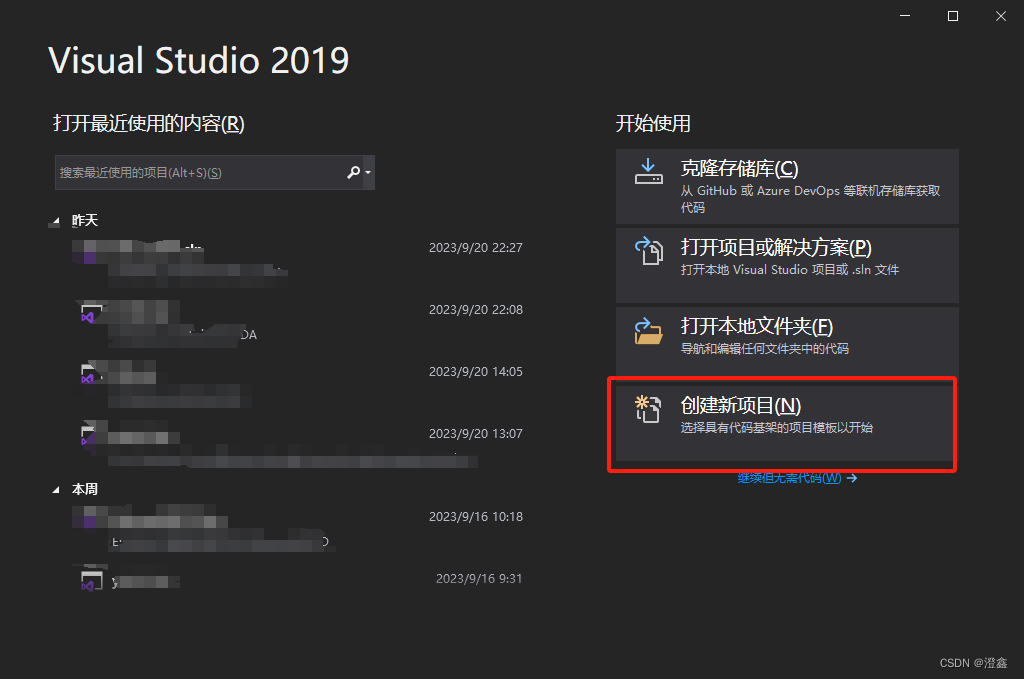
然后在右侧选择到cuda runtime,具体是什么版本 看你装的是什么版本 因人而异:
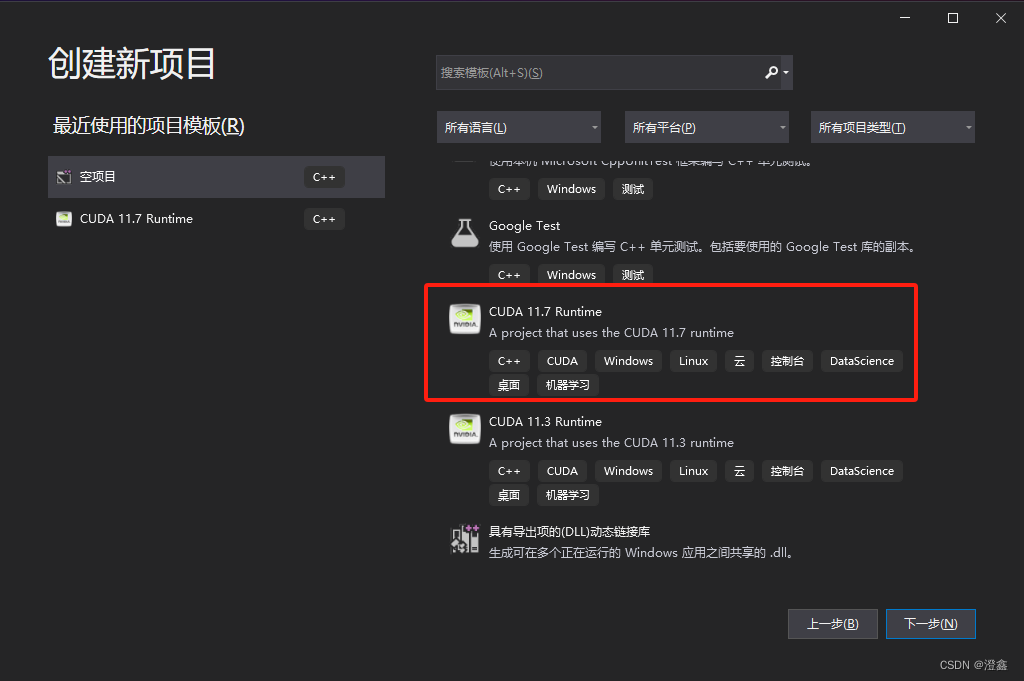
创建完毕后,软件会自动生成一段基于GPU编程的代码,运行之后如果能正常出结果,说明你的CUDA安装和CUDNN的安装与系统环境配置没有问题了:
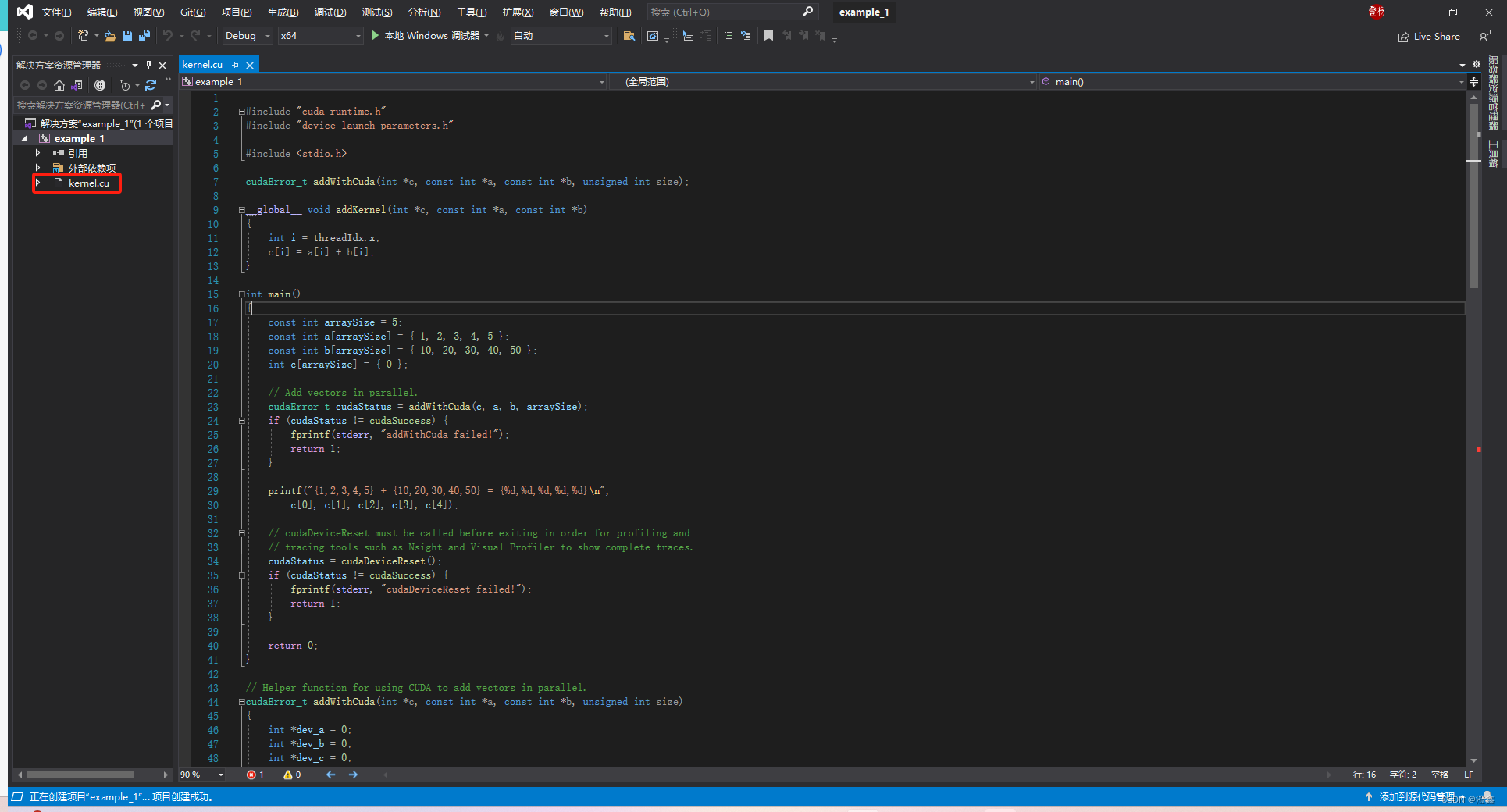
运行这个.cu后缀名的代码,得到结果:
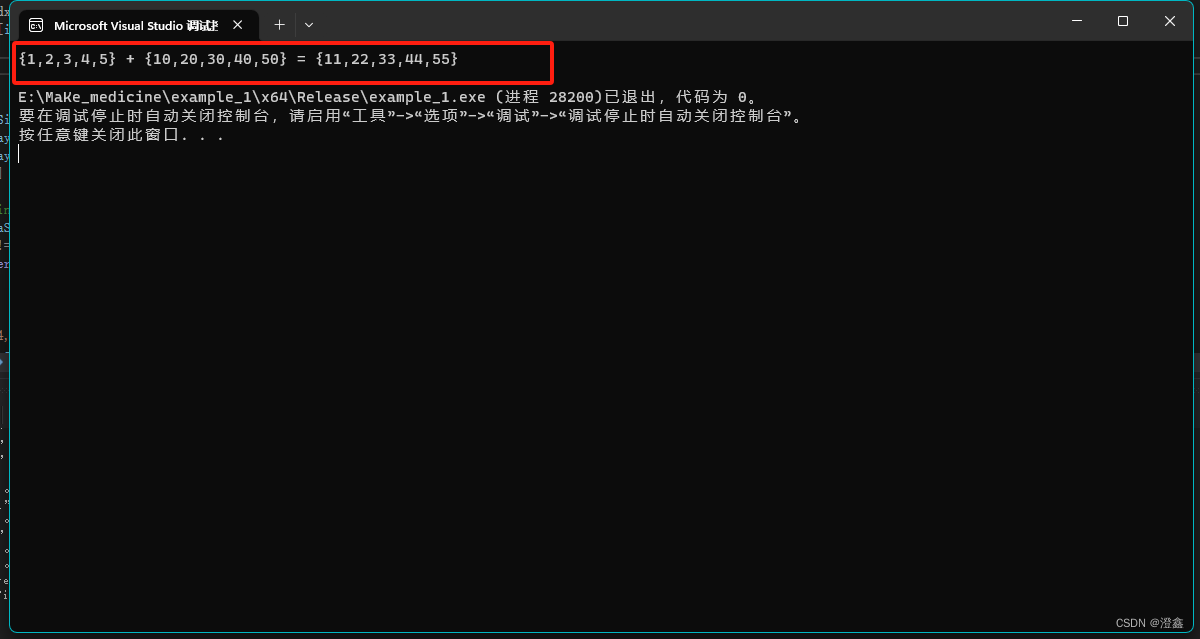
则说明我们的第一个CUDA编程的代码跑通了。
😝debug设置
我们创建完项目之后,正常运行没问题的话,就可以开始完成我们的GPU编程了,但在写代码的过程中,难免会遇到bug,这时候如果我们想通过打断点的方式去调试,程序却无法在断点处终止,而是每次都执行完毕,这是因为我们创建的项目默认给我们设置了无法debug的模式,我们只需要点击项目:
打开项目属性:
把红箭头指向的地方选择是。
这边也同样将选择的地方选择成是。
🍅方法二-空项目配置
创建好之后,我们右键项目名称,选择生成依赖项,再选择生成自定义:
勾选我们想要的CUDA版本。
点击空项目创建好项目之后,右键源文件,创建一个.cu为后缀名的代码文件:
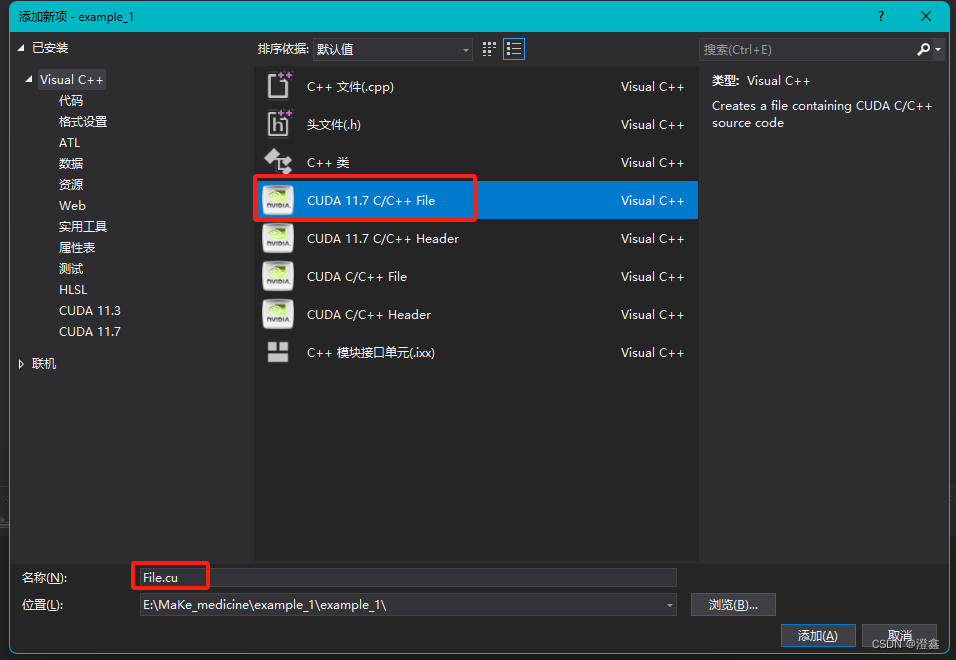
名称自己随便定义。
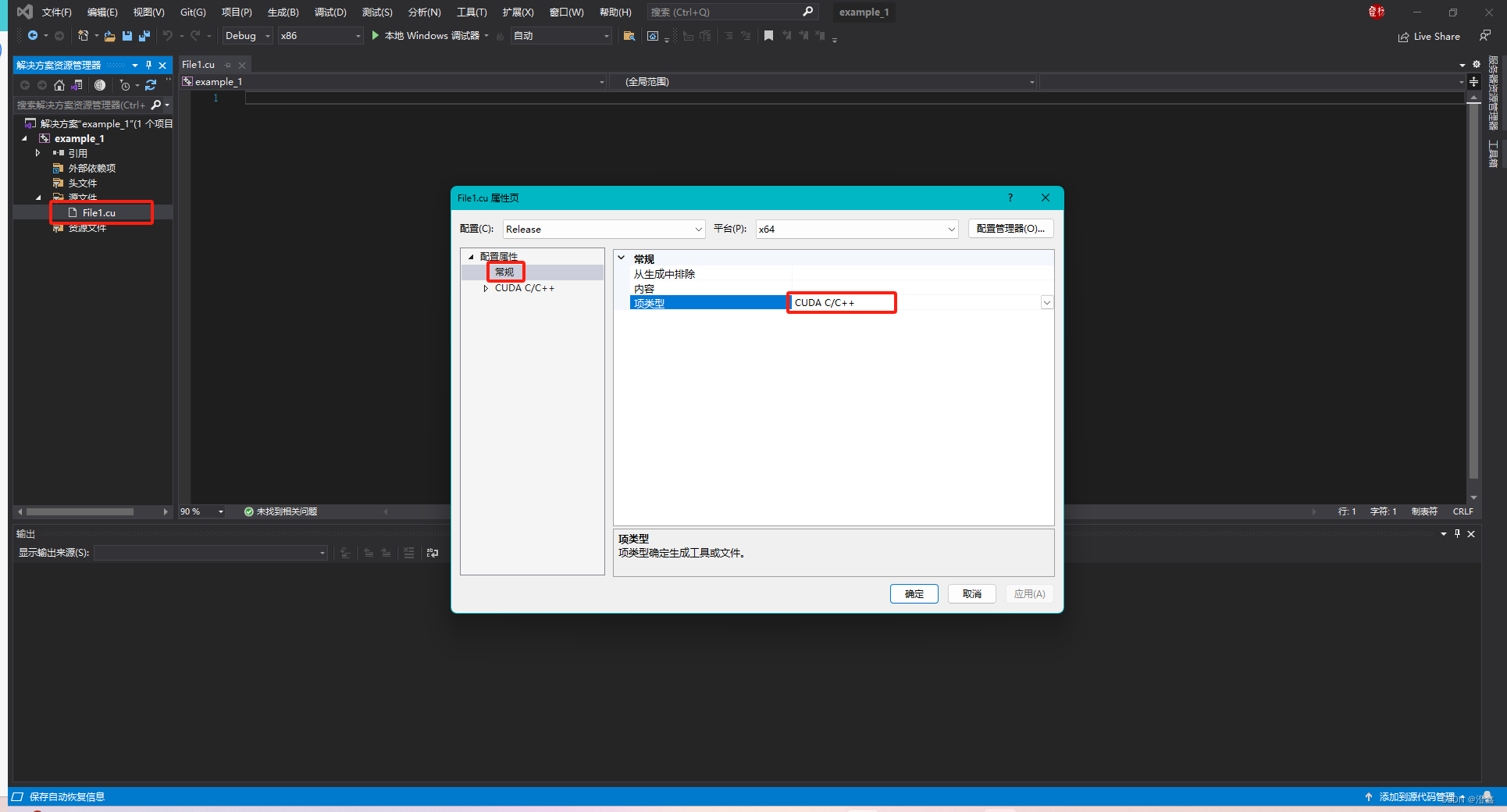
右键点击刚才创建好的.cu后缀名的文件,选择属性,点击常规,在项类型中选择CUDA C/C++即可:
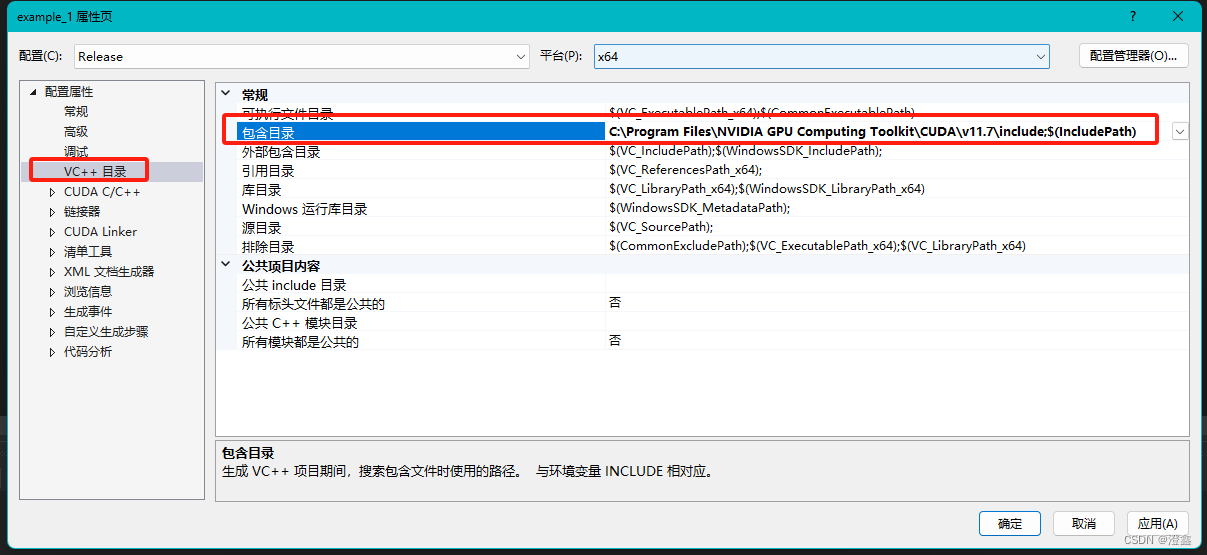
然后打开项目属性页,开始配置路径:
首先是包含目录:
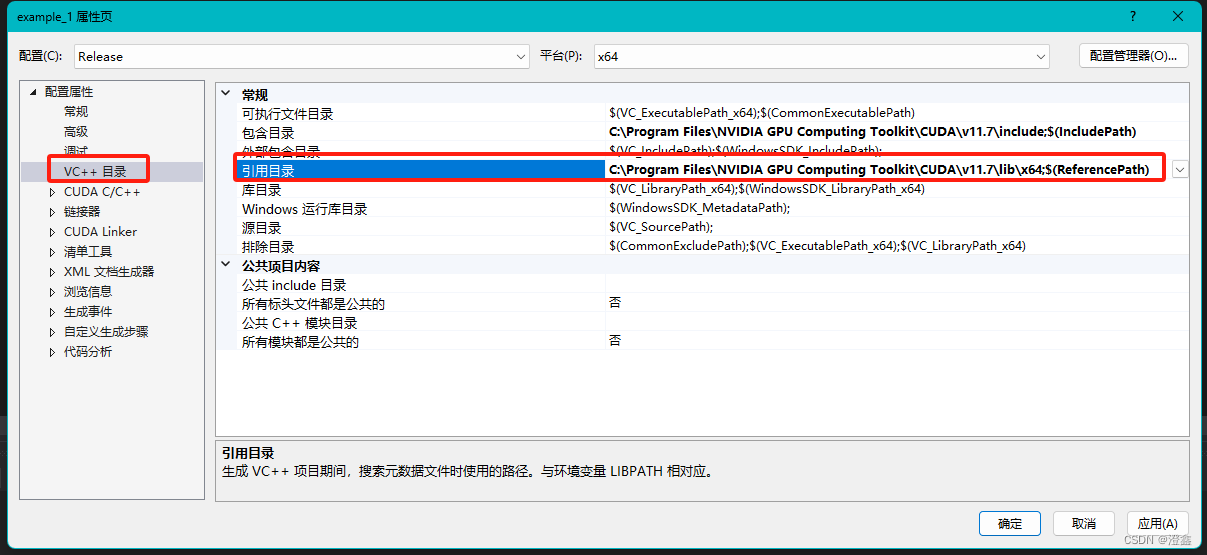
然后是库目录:
然后是链接器的附加库目录:
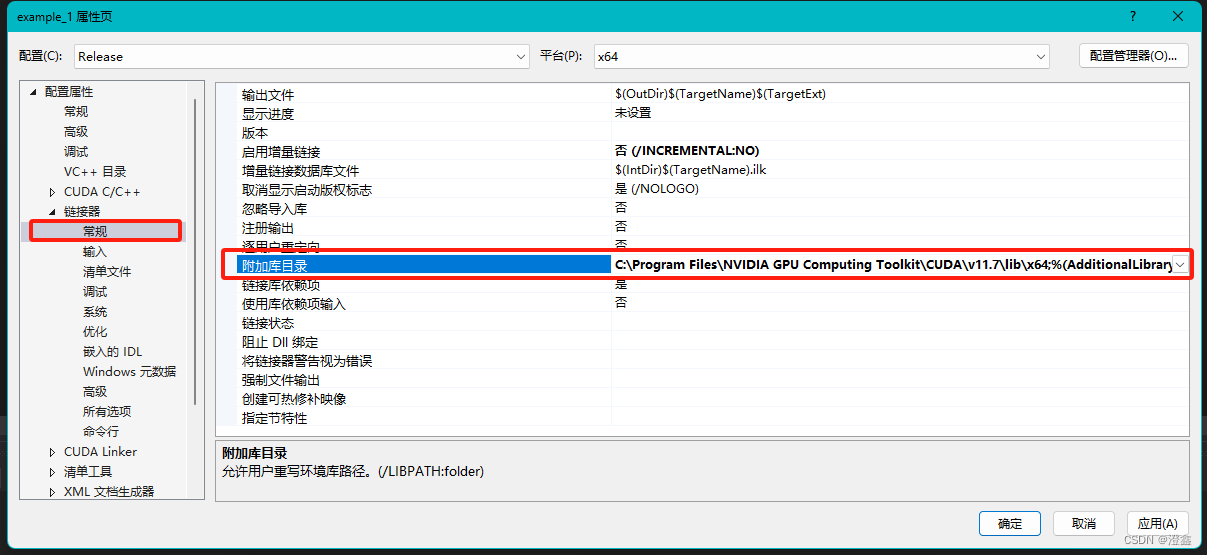
然后,我们在桌面或者随便在哪个可以创建txt的地方,新建一个txt文件夹,命名为res.txt:
将这个txt复制到这个路径下:
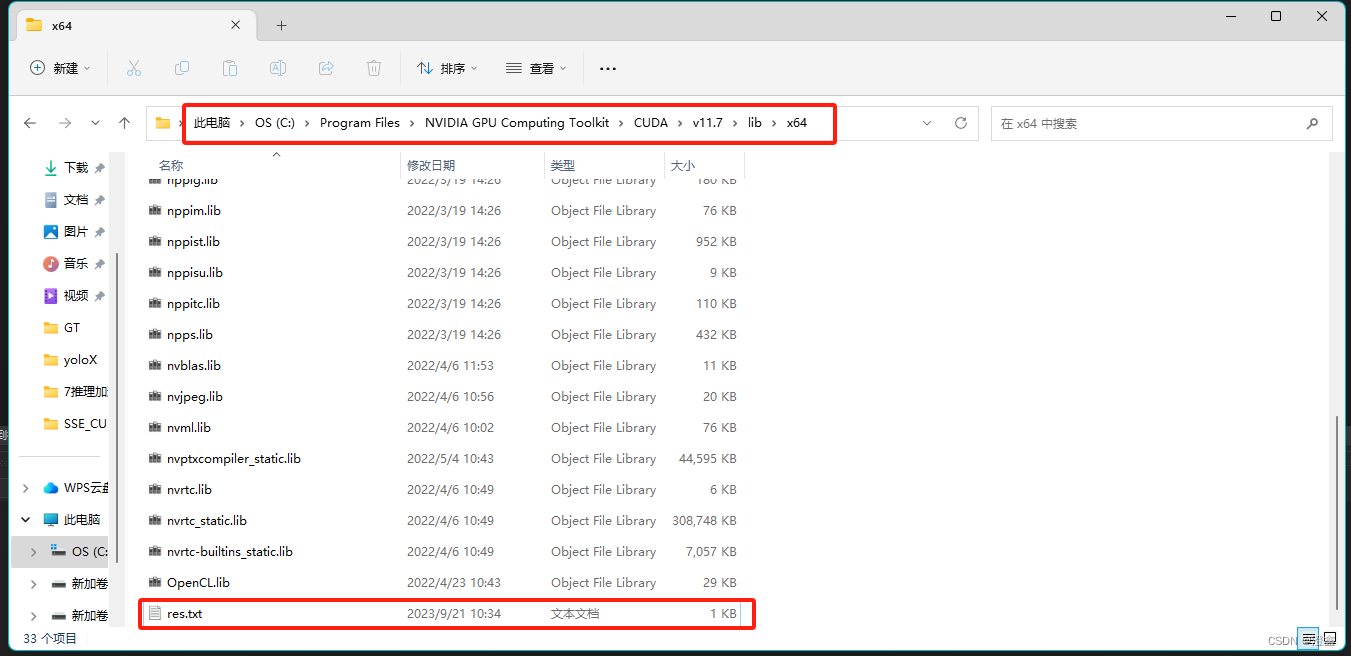
打开终端,cd到这个路径里面,输入:
DIR *.lib /B > res.txt
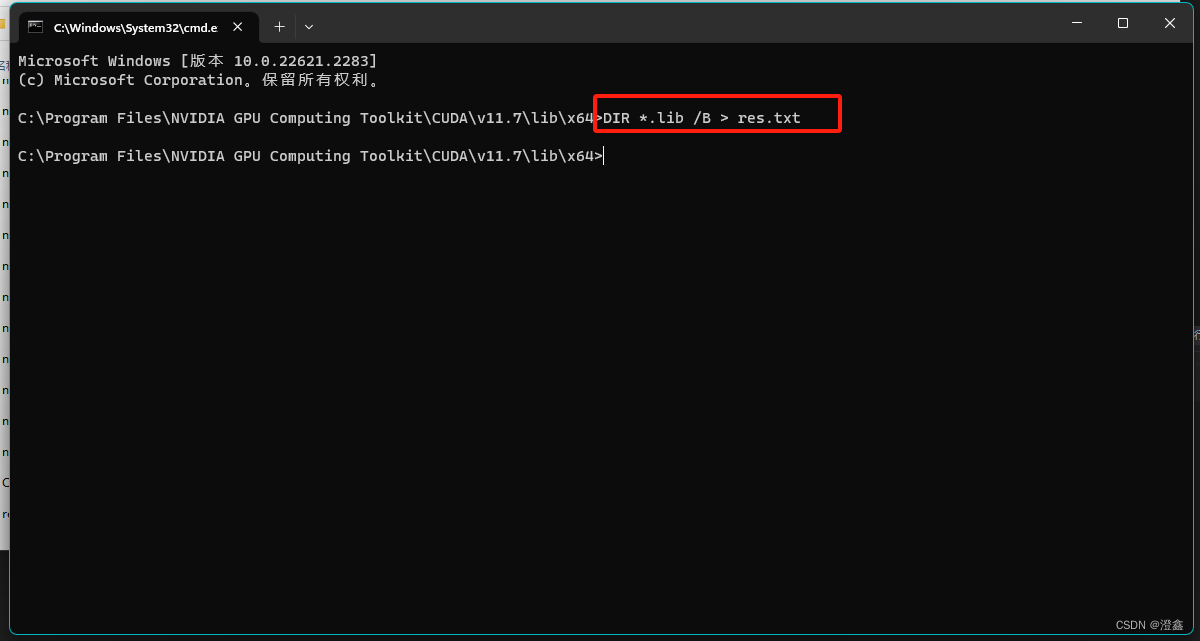
然后我们再打开res.txt,则可以发现里面已经写入了这个路径下的所有lib依赖项的名字了。
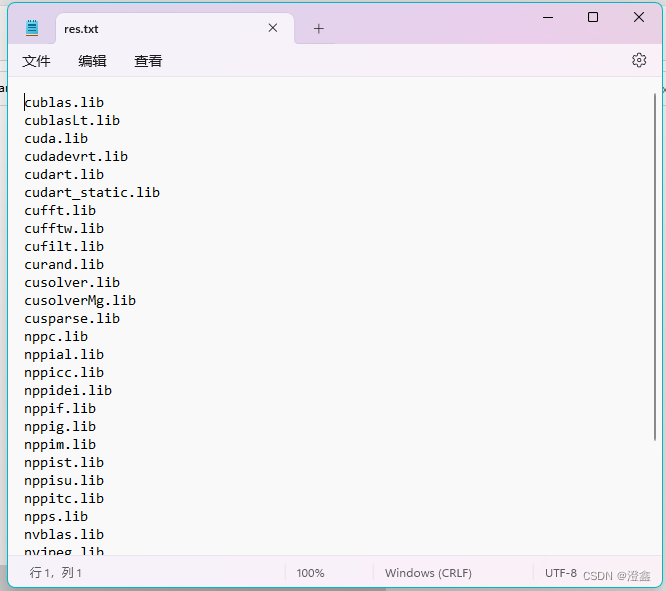
然后我们复制所有的这些名称,拷贝到链接器-输入的附加依赖项中:
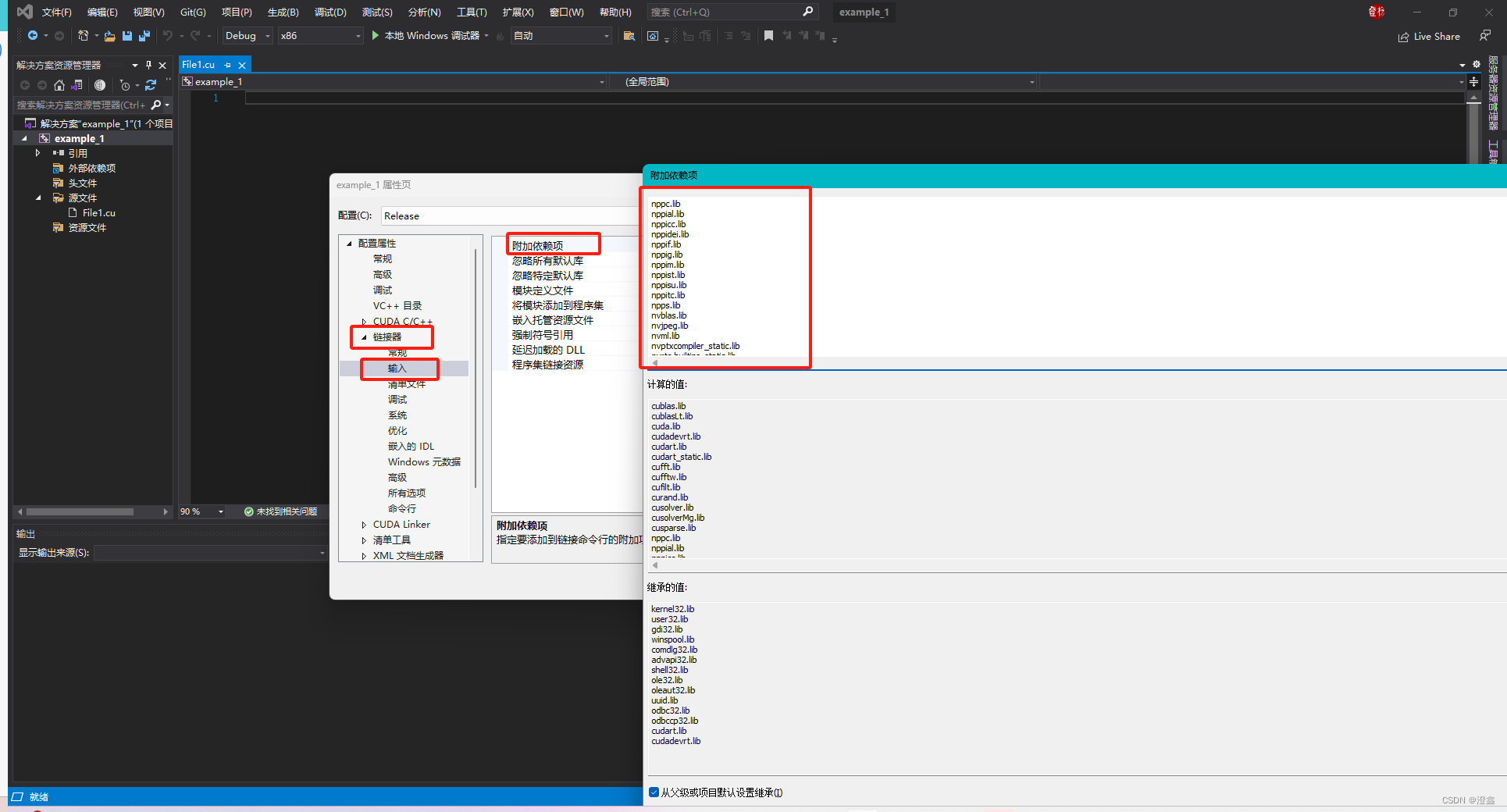
最后点击应用,然后确定。
最后记得将这两个位置设置成一样的:
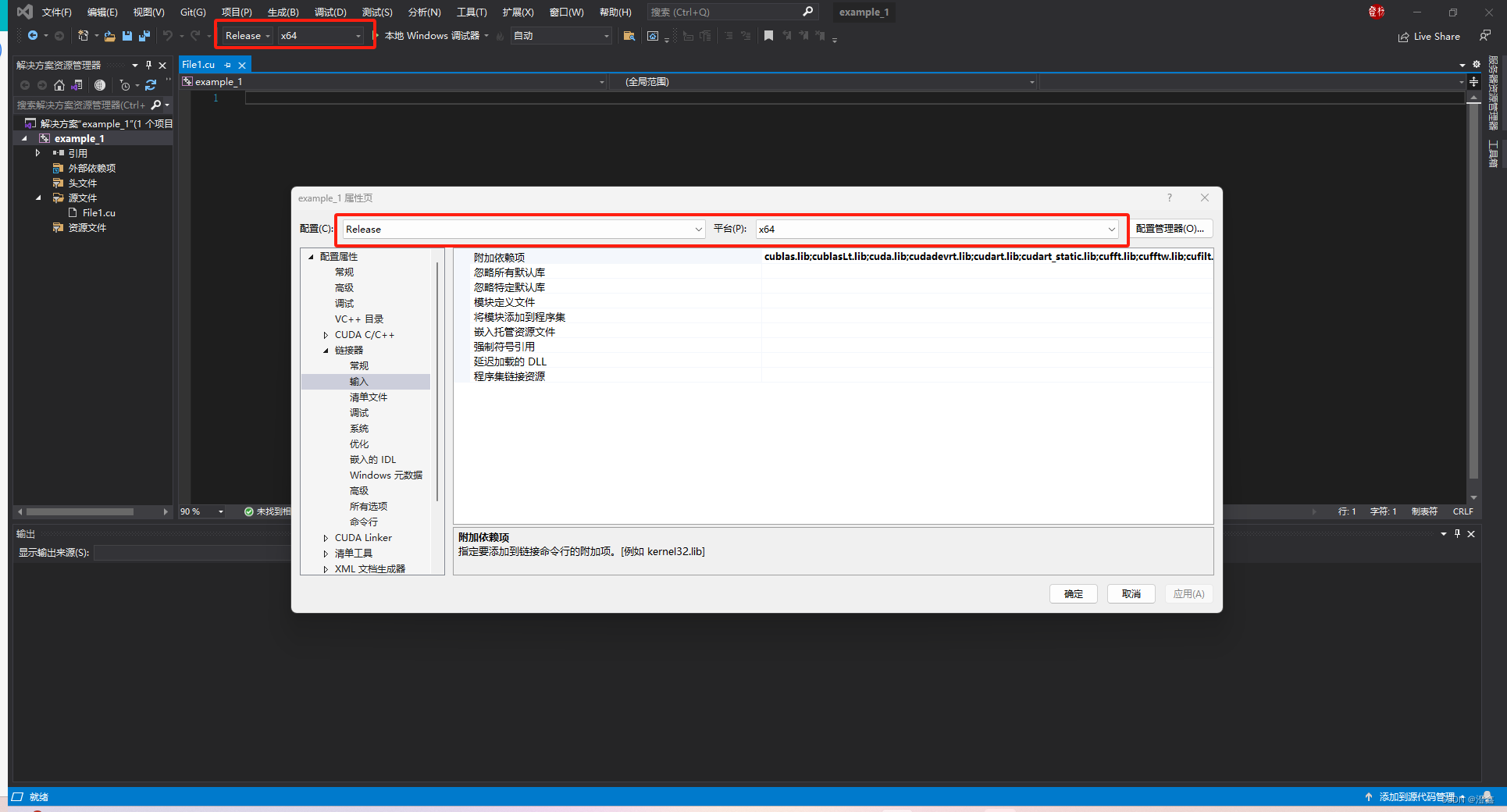
设置debug的方式见方法一的最后。
🍉🍉🍉代码验证
这里我们准备一串基于GPU编程的代码:
#include <device_launch_parameters.h>
#include <cuda_runtime.h>
#include <iostream>
#include <cuda.h>
#include <vector>using namespace std;//基于GPU的矢量求和
#define N 10__global__ void add(int* a_ptr, int* b_ptr, int* c_ptr)
{int tid = blockIdx.x;if (tid < N){c_ptr[tid] = a_ptr[tid] + b_ptr[tid];}
}int main()
{/*std::vector<int> a(N), b(N), c(N);int* a_ = &a[0], * b_ = &b[0], * c_ = &c[0];*/int a[N], b[N], c[N];int* a_ptr, * b_ptr, * c_ptr;//在CPU上分配内存cudaMalloc((void**)&a_ptr, N * sizeof(int));cudaMalloc((void**)&b_ptr, N * sizeof(int));cudaMalloc((void**)&c_ptr, N * sizeof(int));//在cpu上为数组赋值for (int i = 0; i < N; i++){a[i] = -i;b[i] = i * i;}//将数组a和数组b复制到GPU上cudaMemcpy(a_ptr, a, N * sizeof(int), cudaMemcpyHostToDevice);cudaMemcpy(b_ptr, b, N * sizeof(int), cudaMemcpyHostToDevice);//N表示在执行核函数时使用的并行线程块的数量。add << <N, 1 >> > (a_ptr, b_ptr, c_ptr);//将运算结果从GPU拷贝到CPUcudaMemcpy(c, c_ptr, N * sizeof(int), cudaMemcpyDeviceToHost);//显示结果for (int i = 0; i < N; i++){cout << a[i] << "+" << b[i] << "=" << c[i] << endl;}cudaFree(a_ptr);cudaFree(b_ptr);cudaFree(c_ptr);return 0;
}
运行之后可以得到结果:
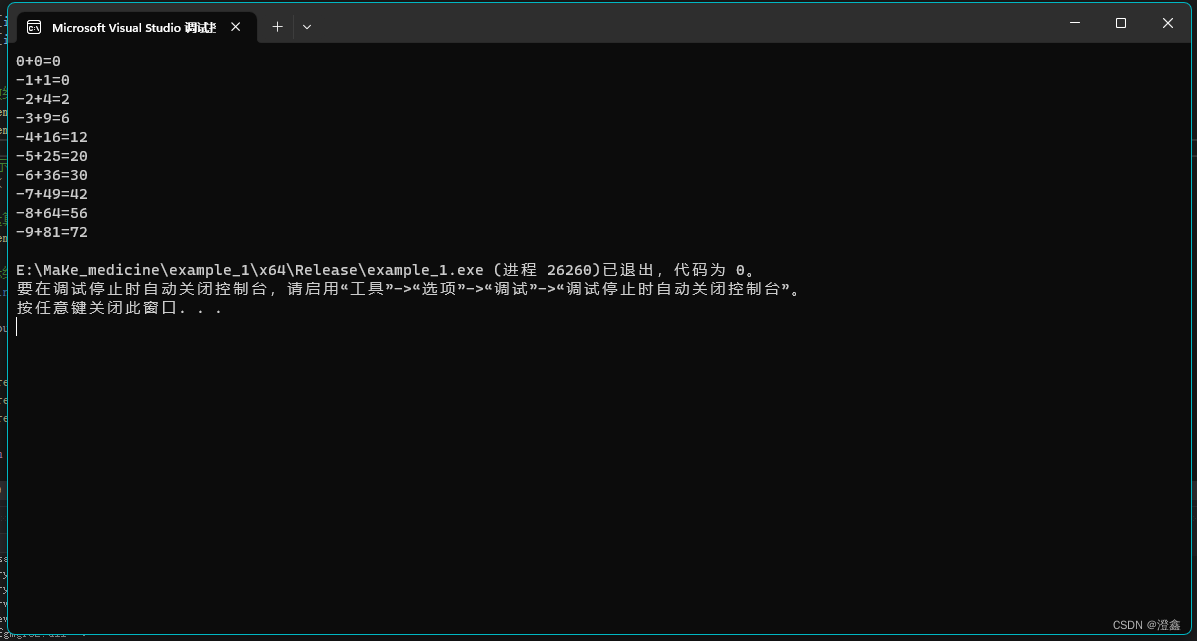
则说明基于GPU编程的项目创建成功了。