python(自4) xpath下载 lxml安装 lxml语法 使用方式
(一)安装 搜索xpath
讲解 XPath 教程 (w3school.com.cn)
一,下载地址 : https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl

二 ,拖拽
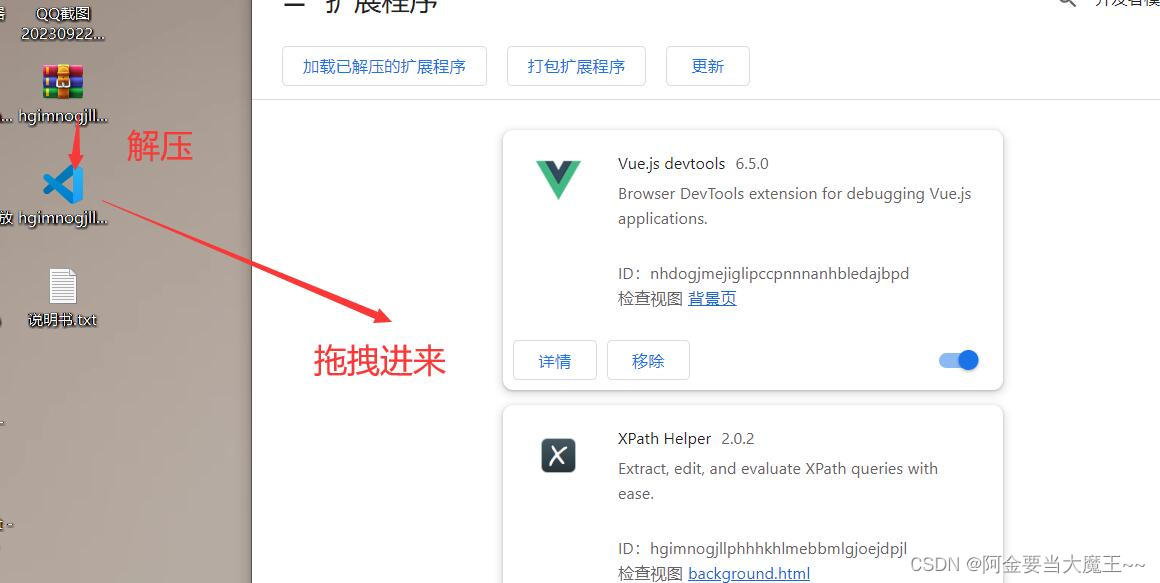
(二)lxml安装
cmd 打开终端
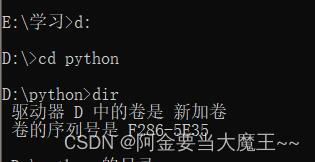
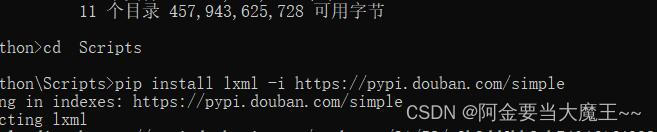
cd pythondircd Scriptspip install lxml -i https://pypi.douban.com/simple一 ,查看是否安装完成打开谷歌随便搜索一个网页按shift +ctrl+X 出现黑框

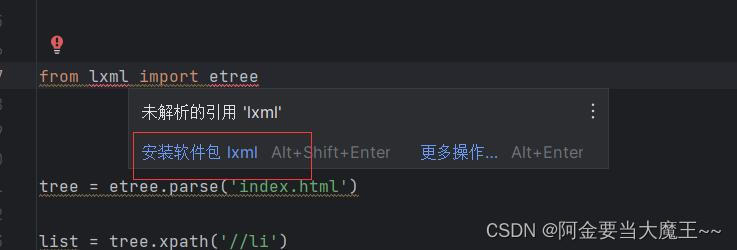
(三) 测试lxml安装成功
打开pyCharm 输入 from lxml import etree 如果报错 就点击安装(我这个就是没安装成功)
lxml基本语法
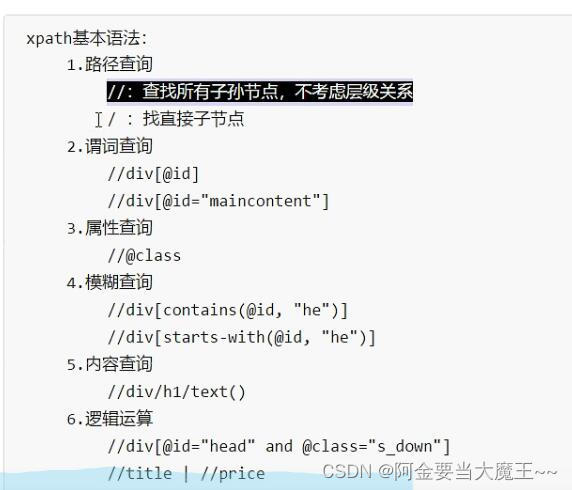
lxml语法使用 需要单独创建一个html文件 然后获取里边的数据
路径的写法:
1. 绝对路径: 用"/"开头的路径 - /标签在树结构中的路径 (路径必须从根节点开始写)
2. 相对路径: 路径开头用"."标签当前节点(xpath前面是谁,'.'就代表谁), ".."表示当前节点的上层节点
3. 全路径: 用"//"开头的路径 - 在整个树中获取标签注意:绝对路径和全路径的写法以及查找方式和是用谁去点的xpath无关
"""
result = root.xpath('/supermarket/staffs/staff/name/text()')
print(result)result = root.xpath('./staffs/staff/name/text()')
print(result)staff1 = root.xpath('./staffs/staff')[0] # 获取第一个员工对应的staff标签
result = staff1.xpath('./name/text()')
print(result) # ['小明']result = staff1.xpath('../staff/name/text()')
print(result) # ['小明', '小花', '张三', '李四', '王五']result = root.xpath('//name/text()')
print(result)result = staff1.xpath('//goods/name/text()')
print(result)# 3)获取标签内容
# 节点对象.xpath(获取标签的路径/text()) - 获取指定路径下所有标签的标签内容
result = root.xpath('//position/text()')
print(result)# 4)获取标签属性值
# 节点对象.xpath(获取标签的路径/@属性名)
result = root.xpath('/supermarket/@name')
print(result) # ['永辉超市']result = root.xpath('//staff/@id')
print(result)# 5)谓语(条件)
# a. 位置相关谓语
"""
[N] - 第N个
[last()] - 最后一个
[last()-N]; [last()-1] - 倒数第2个 、 [last()-2] - 倒数第3个
[position()>N]、[position()<N]、[position()>=N]、[position()<=N]
"""
result = root.xpath('//staff[1]/name/text()')
print(result) # ['小明']result = root.xpath('//staff[last()]/name/text()')
print(result) # ['王五']result = root.xpath('//staff[last()-1]/name/text()')
print(result) # ['李四']result = root.xpath('//staff[position()<3]/name/text()')
print(result) # ['小明', '小花']# b.属性相关谓语
"""
[@属性名=属性值] - 指定属性是指定值的标签
[@属性名] - 拥有指定属性的标签
"""
# staff[@class="c1"] == staff.c1
result = root.xpath('//staff[@class="c1"]/name/text()')
print(result)result = root.xpath('//staff[@id="s003"]/name/text()')
print(result)result = root.xpath('//goods[@discount]/name/text()')
print(result)# c.子标签内容相关谓语 - 根据子标签的内容来筛选标签
"""
[子标签名>数据]
[子标签名<数据]
[子标签名>=数据]
[子标签名<=数据]
[子标签名=数据]
"""
result = root.xpath('//goods[price=2]/name/text()')
print(result)# 6)通配符 - 写路径的时候用*来表示所有标签或者所有属性
result = root.xpath('//staff[1]/*/text()')
print(result)# *[@class="c1"] == .c1
result = root.xpath('//*[@class="c1"]/name/text()')
print(result)result = root.xpath('//goods[@*]/name/text()')
print(result)result = root.xpath('/supermarket/@*')
print(result)# 7)若干路径 - |
# 路径1|路径2 - 同时获取路径1和路径2的内容
result = root.xpath('//goods/name/text()|//staff/position/text()')
print(result)
lxml网页使用 写lxml语法 右边会出现对应的文字数据

参考
【RPA开发】lxml 库之 etree 使用详解_尹煜的博客-CSDN博客
lxml基本语法_顶峰相见_li的博客-CSDN博客