EfficientFormer:高效低延迟的Vision Transformers
我们都知道Transformers相对于CNN的架构效率并不高,这导致在一些边缘设备进行推理时延迟会很高,所以这次介绍的论文EfficientFormer号称在准确率不降低的同时可以达到MobileNet的推理速度。

Transformers能否在获得高性能的同时,跑得和MobileNet一样快?为了回答这个问题,作者首先回顾了基于vit的模型中使用的网络架构和运算,并说明了一些低效的设计。然后引入一个维度一致的纯Transformer(没有MobileNet块)作为设计范例。最后以延迟为目标进行优化设计,获得一系列称为EfficientFormer的最终模型。最后还设计了EfficientFormerV2。
延迟分析

作者在论文中发现:
1、内核大、步幅大的补丁嵌入是移动设备上的速度瓶颈。
2、一致的特征维度对于令牌混合器的选择很重要。MHSA不一定是速度瓶颈。
3、convn - bn比LN (GN)-Linear更有利于延迟,对于延迟的降低,精度的小损失是可以接受的。
4、非线性的延迟取决于硬件和编译器。
EfficientFormer整体架构

该网络由补丁嵌入(PatchEmbed)和元Transformer块堆栈组成,表示为MB:

X0为批大小为B,空间大小为[H, W]的输入图像,Y为期望输出,m为块总数(深度)。MB由未指定的令牌混合器(TokenMixer)组成,后跟一个MLP块:
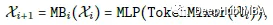
Xi|i>0是第i MB的中间特征。阶段Stage(或S)被定义为几个MetaBlocks的堆栈。该网络包括4个阶段。在每个阶段中,都有一个嵌入操作来投影嵌入维数和下采样令牌长度,表示为嵌入,如上图所示。
也就是说effentformer是一个完全基于transformer的模型,没有集成MobileNet结构。
Dimension-Consistent设计
网络从四维划分开始,后期进行三维划分。首先,输入图像由stem层进行处理,这是两个3 × 3,步幅为2的卷积作为patch嵌入:

其中Cj是第j级的通道号(宽度)。然后网络从MB4D开始,使用简单的Pool mixer提取低级特征:

式中,ConvB,G表示是否有BN和GeLU跟随卷积。在处理完所有MB4D块后,执行一次重塑以转换特征大小并进入3D分区。MB3D使用传统的ViT:

式中,LinearG表示线性后接GeLU, MHSA为:

其中,Q, K, V分别表示查询,键和值,b是参数化的作为位置编码的注意力偏差。

在定义了总体体系结构之后,下一步作者就开始搜索高效的体系结构。
以延迟为目标架构优化
定义了一个搜索高效模型的超级网络MetaPath (MP),它是一些可能块的集合:

其中I表示单位路径。
在网络的S1和S2中,每个区块可以选择MB4D或I,在S3和S4中,每个区块可以选择MB3D、MB4D或I。
在最后两个阶段只启用MB3D的原因有2个:1、由于MHSA的计算相对于令牌长度呈二次增长,因此在早期阶段将其集成将大大增加计算成本。2、网络的早期阶段捕获低级特征,而后期阶段学习长期依赖关系。
搜索空间包括Cj(每个Stage的宽度),Nj(每个Stage的块数,即深度)和最后N个应用MB3D的块。
搜索算法使用Gumbel Softmax采样对超级网络进行训练,以获得每个MP内块的重要性得分:

其中α评估MP中每个块的重要性,因为它表示选择一个块的概率。ε ~ U(0,1)保证探索。对于S1和S2, n∈{4D, I},对于S3和S4, n∈{4D, 3D, I}。
最后通过收集不同宽度的MB4D和MB3D的设备上延迟(16的倍数),构建一个延迟查找表。
也就是说EfficientFormer的架构不是通过人工设计的,而是通过NAS(Neural Architecture Search)搜索出来的。作者通过查找表计算每个动作产生的延迟,并评估每个动作的准确率下降。根据每延迟精度下降(-%/ms)选择动作。这个过程迭代地执行,直到达到目标延迟。(细节见论文附录)
结果展示

ImageNet上与广泛使用的基于cnn的模型相比,EfficientFormer在准确率和延迟之间实现了更好的权衡。
传统的vit在延迟方面仍然表现不佳。EfficientFormer-L3的top-1准确率比PoolFormer-S36高1%,在Nvidia A100 GPU上快3倍,在iPhone NPU上快2.2倍,在iPhone CPU上快6.8倍。
EfficientFormer-L1的Top1精度比MobileViT-XS高4.4%,并且在不同的硬件和编译器上运行得更快。

MS COCO数据集,EfficientFormers的表现始终优于CNN (ResNet)和Transformer (PoolFormer)。
使用ADE20K,在类似的计算预算下,EfficientFormer始终比基于CNN和transformer的主干性能好得多。
论文地址:
EfficientFormer: Vision Transformers at MobileNet Speed
https://avoid.overfit.cn/post/eb0e56c5753942cf8ee70d78e2cd7db7