机器学习第十三课--主成分分析PCA
一.高维数据
除了图片、文本数据,我们在实际工作中也会面临更多高维的数据。比如在评分卡模型构建过程中,我们通常会试着衍生出很多的特征,最后就得到上千维、甚至上完维特征;在广告点击率预测应用中,拥有几个亿特征也是常见的事情;在脑科学或者基因研究中,特征数甚至可能更多;所以,如何更有效地处理这些高维的特征就变成了一个非常重要的问题。
二.数据降维
除了有效利用高维的数据之外,我们也可以思考一个问题:“高维数据,那么多特征真的都有用吗?” 这就类似于一个人的社交质量并不取决于有多少朋友,而在于朋友质量,在建模过程中也适用这个道理。特征越多并不代表学出来的模型越好,我们更需要关注特征对预测任务的相关性或者价值,有些特征甚至可能成为噪声,反而影响模型的效果。
2.1如何降维
2.1.1数据的降维 通过函数的映射关系
2.1.2特征选择
选择子集
三.PCA
PCA(Principal Component Analysis)作为一种重要的降维算法有着非常广泛的应用。PCA经常用来做数据的可视化、或者用来提高预测模型的效果。 对于PCA降维算法来讲,有几个核心问题需要弄清楚:
1。 PCA降维的核心思想是什么? 它是依赖于什么条件做降维?
2。 什么叫主成分(principal component)?
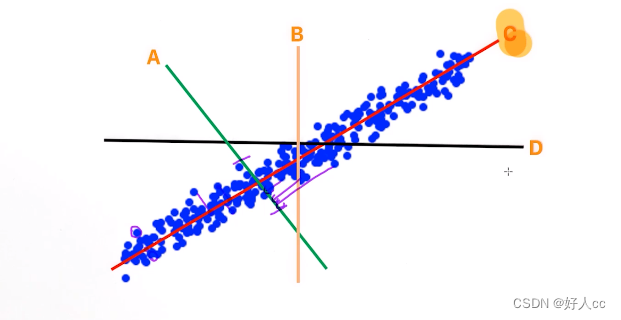
从图中可以看出,沿着C的方向,数据是越分散的,也就说明在这个方向上我们可以看出数据之间的更多差异!相反,沿着直线A的方向,我们可以看到很多数据的差异并不明显,区分度很低。所以,总体来讲,当我们选择C为新的坐标轴时,所有点在这个坐标轴上的值的差异是最大的,也就是最大程度的保留了数据之间的特点(差异性),这就是PCA的核心思想。
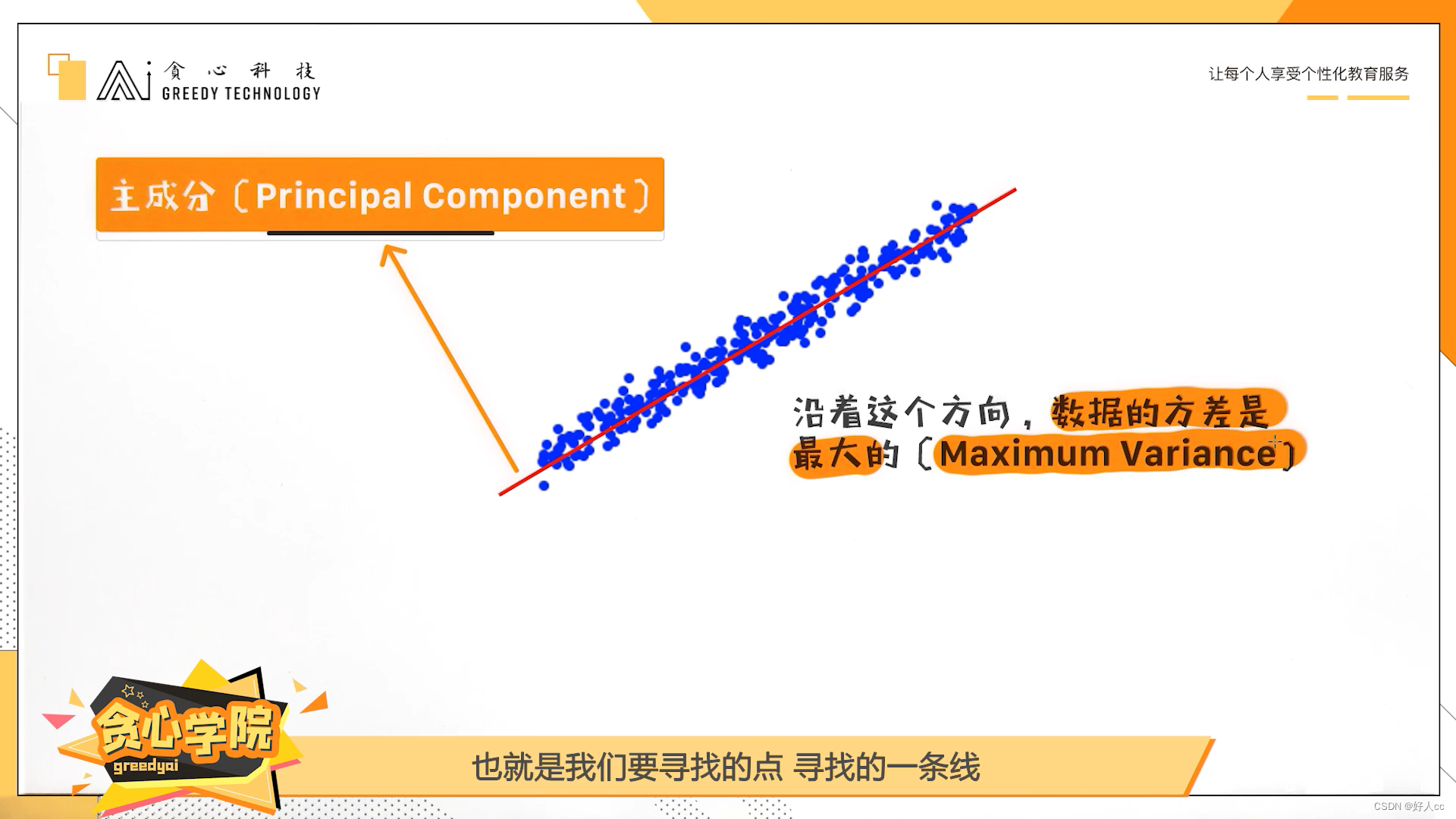
找到第一个主成分,第二个主成分和第一个主成分垂直。
四.PCA的缺点
1.只能针对线性
2.必须做归一化
3.部分信息会丢失(降维)
4.可解释性比较弱
五.其他的降维方法
