使用 PyTorch 的计算机视觉简介 (1/6)

一、说明
二、CV常见的问题
计算机视觉最常见的问题包括:
- 图像分类是最简单的任务,当我们需要将图像分类为许多预定义类别之一时,例如,区分照片上的猫和狗,或识别手写数字。
- 目标检测是一项比较困难的任务,我们需要在图片上找到已知对象并对其进行定位,即返回每个识别对象的边界框。
- 分割类似于对象检测,但我们需要返回一个精确的像素图,概述每个识别的对象,而不是给出边界框。
我们将专注于图像分类任务,以及如何使用神经网络来解决它。与任何其他机器学习任务一样,要训练用于对图像进行分类的模型,我们需要一个标记的数据集,即每个类的大量图像。
三、图像作为张量
计算机视觉适用于图像。您可能知道,图像由像素组成,因此可以将它们视为像素的矩形集合。
在本单元的第一部分中,我们将处理手写数字识别。我们将使用 MNIST 数据集,该数据集由手写数字的灰度图像组成,28x28 像素。每个图像都可以表示为 28x28 数组,该数组的元素将表示相应像素的强度 - 在 0 到 1 范围内(在这种情况下使用浮点数),或者 0 到 255(整数)。一个名为numpy的流行python库通常用于计算机视觉任务,因为它允许有效地操作多维数组。
为了处理彩色图像,我们需要一些方法来表示颜色。在大多数情况下,我们用 3 个强度值表示每个像素,对应于红色 (R)、绿色 (G) 和蓝色 (B) 分量。这种颜色编码称为RGB,因此大小为W×H的彩色图像将表示为大小
为3 × H × W的数组。
使用多维数组来表示图像也有一个优势,因为我们可以使用额外的维度来存储图像序列。
例如,为了表示由 200 帧组成的视频片段,维度为 800 × 600,我们可以使用大小为 200 × 3 × 600 × 800 的张量。
多维数组也称为张量。通常,当我们谈论一些神经网络框架时,我们指的是张量,例如 PyTorch。PyTorch 和 numpy 数组中的张量之间的主要区别在于,张量支持 GPU 上的并行操作(如果可用)。此外,PyTorch 在张量上操作时提供了额外的功能,例如自动微分。
四、导入包并加载 MNIST 数据集
!pip install -r https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/computer-vision-pytorch/requirements.txt#Import the packages needed.
import torch
import torchvision
import matplotlib.pyplot as plt
import numpy as npPyTorch有许多直接从库中可用的数据集。在这里,我们使用众所周知的手写数字MNIST数据集,可通过PyTorch中的torchvison.datasets.MNIST获得。数据集对象以 Python 想象库 (PIL) 图像的形式返回数据,我们通过传递 transform = ToTensor() 参数将其转换为张量。
使用自己的笔记本时,您还可以尝试其他内置数据集,特别是FashionMNIST数据集。
from torchvision.transforms import ToTensordata_train = torchvision.datasets.MNIST('./data',download=True,train=True,transform=ToTensor())
data_test = torchvision.datasets.MNIST('./data',download=True,train=False,transform=ToTensor())五、可视化数据集
现在我们已经下载了数据集,我们可以可视化数字。
fig,ax = plt.subplots(1,7)
for i in range(7):ax[i].imshow(data_train[i][0].view(28,28))ax[i].set_title(data_train[i][1])ax[i].axis('off')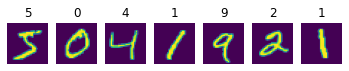
六、数据集结构
我们总共有 6000 张训练图像和 1000 张测试图像。拆分数据以进行训练和测试非常重要。我们还想做一些数据探索,以更好地了解我们的数据是什么样子的。
每个样本都是以下结构的元组:
- 第一个元素是一个数字的实际图像,由形状为 1 × 28 × 28 的张量表示
- 第二个元素是一个标签,用于指定张量表示哪个数字。它是一个张量,包含从 0 到 9 的数字
data_train是一个训练数据集,我们将使用它来训练我们的模型。data_test是一个较小的测试数据集,我们可以用来验证我们的模型。
print('Training samples:',len(data_train))
print('Test samples:',len(data_test))print('Tensor size:',data_train[0][0].size())
print('First 10 digits are:', [data_train[i][1] for i in range(10)])Training samples: 60000
Test samples: 10000
Tensor size: torch.Size([1, 28, 28])
First 10 digits are: [5, 0, 4, 1, 9, 2, 1, 3, 1, 4]图像的所有像素强度都由介于 0 和 1 之间的浮点值表示:
print('Min intensity value: ',data_train[0][0].min().item())
print('Max intensity value: ',data_train[0][0].max().item())Min intensity value: 0.0
Max intensity value: 1.0祝你学习愉快!V笔记本