Python异步编程并发执行爬虫任务,用回调函数解析响应
一、问题:当发送API请求,读写数据库任务较重时,程序运行效率急剧下降。
异步技术是Python编程中对提升性能非常重要的一项技术。在实际应用,经常面临对外发送网络请求,调用外部接口,或者不断更新数据库或文件等操作。 这这些操作,通常90%以上时间是在等待,如通过REST, gRPC向服务器发送请求,通常可能等待几十毫秒至几秒,甚至更长。如果业务较重,按顺序执行编程,会导致大量时间用在等待上,程序运行效率急剧下降。
常见的场景,就是爬虫软件通常会发起很多请求,如果采用同步编程方式工,往往运行时间很长。
二、异步编程的优势
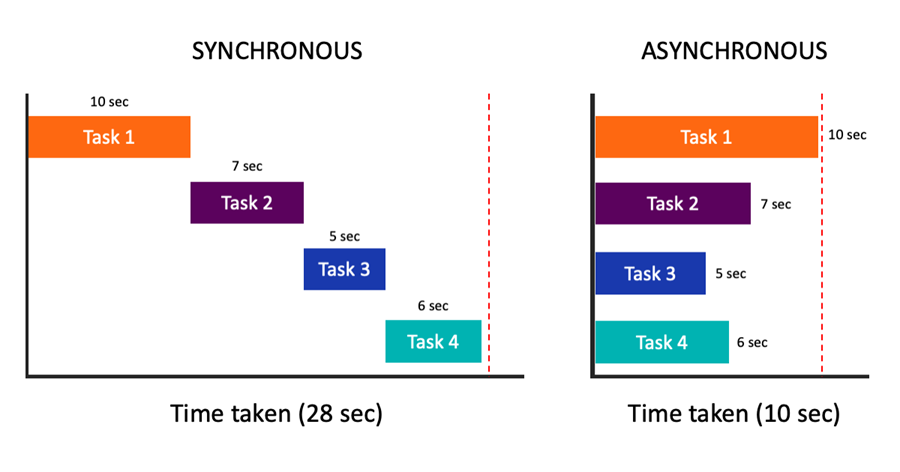
通常的编程,如果有4个任务,采用同步编程模式,4个任务是按顺序执行的,分别用时:10s,7s,5s,6s,共耗时28s; 而异步方式,就是让4个任务同时执行,总耗时降为10s,改善效果是很明显的。
那时异步编程是如何做到的?
异步编程,将每个任务改成协程执行,在遇到需要等待的语句时,即暂时将执行权交还给主程序的控制循环event loop,其它协程可以继续使用CPU等资源。而当该协程收到响应后,会用事件通知event loop,申请继续执行。 这样就避免了由于等待期间还占用CPU资源的情形。 因此程序执行效率大为提高。
但如果任务是计算密集型的,那么异步技术对性能提升帮助不大,需要采用其它方式,如多进程编程。或者Cython 等。
三、用同步编程方式,抓取多个网站数据
先看一下,采用同步编程顺序执行,抓取多个网站数据的耗时。 这些网站中,
其中http://www.google.com 是无响应的,会超时。因此在 requests.get()方法,设置 timeout=3, 即超过3秒,会抛出TimeOutException 异常。
代码如下:
import requests
import time# 测试时将测试网址替换
urls = ["http://www.bxxxx.com","http://www.aaaa.com","http://www.bbbb.com","http://www.cccc.com","http://www.sdddd.com","http://www.jdddd.com","http://www.zeeee.com","http://www.tffff.com","http://www.cgggg.com","http://www.zhhhhh.com.cn","http://www.google.com","https://www.yiiiii.com/",
]def check_one_ip(url):headers = {"user-ageng": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \(KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69"}TIMEOUT = 3result = ()try:response = requests.get(url, headers=headers, timeout=TIMEOUT)print(f"response from {url} is : {response.status_code}")if 200 <= response.status_code < 300:print(f"length of response body is {len(response.text)}")result = (url, response.status_code)except Exception as e:print(f"{url} met timeout error")return (url, 999)return resultdef main():results = []for url in urls:result = check_one_ip(url)results.append(result)if __name__ == "__main__":t1 = time.time()main()t2 = time.time()print(f"total time: {t2-t1:.3f}s")运行代码,向12个网站发送request, 打印response的状态码,总耗时为:6.035s,
response from url is : 200
length of response body is 2381
response from url is : 200
length of response body is 24000
response from url is : 200
length of response body is 106117
response from url is : 403
response from url is : 404
response from url is : 200
length of response body is 177104
response from url is : 200
length of response body is 37989
response from url is : 200
length of response body is 89513
response from url is : 200
length of response body is 32642
response from url is : 403
url met timeout error
response from url is : 200
length of response body is 834
total time: 6.035s
四、用异步方式,同时抓取多个网站数据
现在,采用Asyncio异步编程,以并发的运行方式,向多个网站同时发送request, 总耗时,应该是用时最长那个协程的用时。这里我们使用了timeout, 就是3秒左右。
AsyncIO异步编程步骤:
- 定义异步任务函数
使用 asyc / await 关键字。在耗时操作前加await - 创建asyncio.create_task() 方法创建协程任务
- 在main()方法中用gather() 汇集协程任务,以便并发执行。
gather()方法返回结果是一个由所有返回值聚合而成的迭代器 - 在主线程的event loop中运行main()
asyncio模块提供了1个.run()来启动 event loop 异步控制循环,并执行main()方法, - 可选,给协程添加回调函数来解析网站响应结果
对于每个Task, 可用 add_done_callback(task_callback) 方法添加回调函数,此例中,对显示response的状态码。
其它说明
- 由于requests库的 response对象不支持 await语句,因此这里使用htppx 库来代替requests, 除了异步接口外,其它使用方式完全一致。
完整代码
import asyncio
import httpx
from concurrent.futures import ThreadPoolExecutor, Future
import time
import contextvars# 测试时将测试网址替换
urls = ["http://www.bxxxx.com","http://www.aaaa.com","http://www.bbbb.com","http://www.cccc.com","http://www.sdddd.com","http://www.jdddd.com","http://www.zeeee.com","http://www.tffff.com","http://www.cgggg.com","http://www.zhhhhh.com.cn","http://www.google.com","https://www.yiiiii.com/",
]async def check_one_ip(url):headers = {"user-ageng": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \(KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.69"}TIMEOUT = 3result = ()try:async with httpx.AsyncClient() as client:response = await client.get(url, headers=headers,timeout=TIMEOUT)print(f"response from {url} is : {response.status_code}")if 200 <= response.status_code < 300:print(f"length of response body is {len(response.text)}")result = (url, response.status_code)except Exception as e:print(f"{url} met timeout error")return (url, 999)return result def task_callback(context):# print response.status_code url, code = context.result()print(f"It is callback, got status_code: {code} of {url}")async def main():tasks=[]for url in urls:task = asyncio.create_task(check_one_ip(url))task.add_done_callback(task_callback)tasks.append(task)await asyncio.gather(*tasks) if __name__=="__main__":t1 = time.time()asyncio.run(main())t2 = time.time()print(f"total time: {t2-t1:.3f}s") 运行结果如下,可以看到,总耗时: 3.161s,相比同步编程方式,耗时减少了1半。 随着发送请求量的增加,可以看到更加明显的效果。
response from url is : 302
It is callback, got status_code: 302 of url
response from url is : 302
It is callback, got status_code: 302 of url
response from url is : 200
length of response body is 23508
It is callback, got status_code: 200 of url
response from url is : 302
response from url is : 301
It is callback, got status_code: 302 of url
It is callback, got status_code: 301 of url
response from url is : 301
response from url is : 301
response from url is : 301
response from url is : 200
length of response body is 396837
It is callback, got status_code: 301 of url
It is callback, got status_code: 301 of url
It is callback, got status_code: 301 of url
It is callback, got status_code: 200 of url
response from url is : 404
It is callback, got status_code: 404 of url
response from url is : 200
length of response body is 1151330
It is callback, got status_code: 200 of url
url met timeout error
It is callback, got status_code: 999 of url
total time: 3.161s
五、异步编程注意事项
1)协程不应该执行耗时长的任务
异步event loop执行期间,虽然各个协程是在工作,但主线程是被阻塞的。本例中,异步耗时的总时长与访问google.com超时时长相同,那么意味着,如果协程中如果有1个是耗时很长的任务,那么主线程还将被阻塞,异步解决不了这个问题,这时耗时协程应该拿出来,用子线程、或者子进程来执行。
2) 协程应该汇集后并发执行
遇到一些开发者咨询,为什么采用了异步编程,但性能没有明显提升呢? 创建多个协程任务后,必须按第3步,用gather()方法来汇集创建的协程任务,然后用asyncio.run()方法并发运行。 另外官方文档要求 event loop要在主线程main() 方法中运行。
3)慎用底层编程接口
另外由于官方文档并未清晰说明 event loop、future对象等低层编程接口,除非你很了解异步低层的实现机制,否则不建议使用低层接口,
使用ayncio.run() 来启动evnetloop, 使用 task 对象,而非future 对象。