在已知的二维坐标里找到最接近的点
一、业务场景
最近在研发的项目,在做可视化层,在全球地图上,对我们的国家的陆地地图经纬度按照步长为1的间隔做了二维处理。在得到一组整数的点位信息后,需要将我们已有的数据库数据(业务项目)按照地址的经纬度,映射到这些点位上,找到对应的id建立联系。简化后的处理逻辑如下:

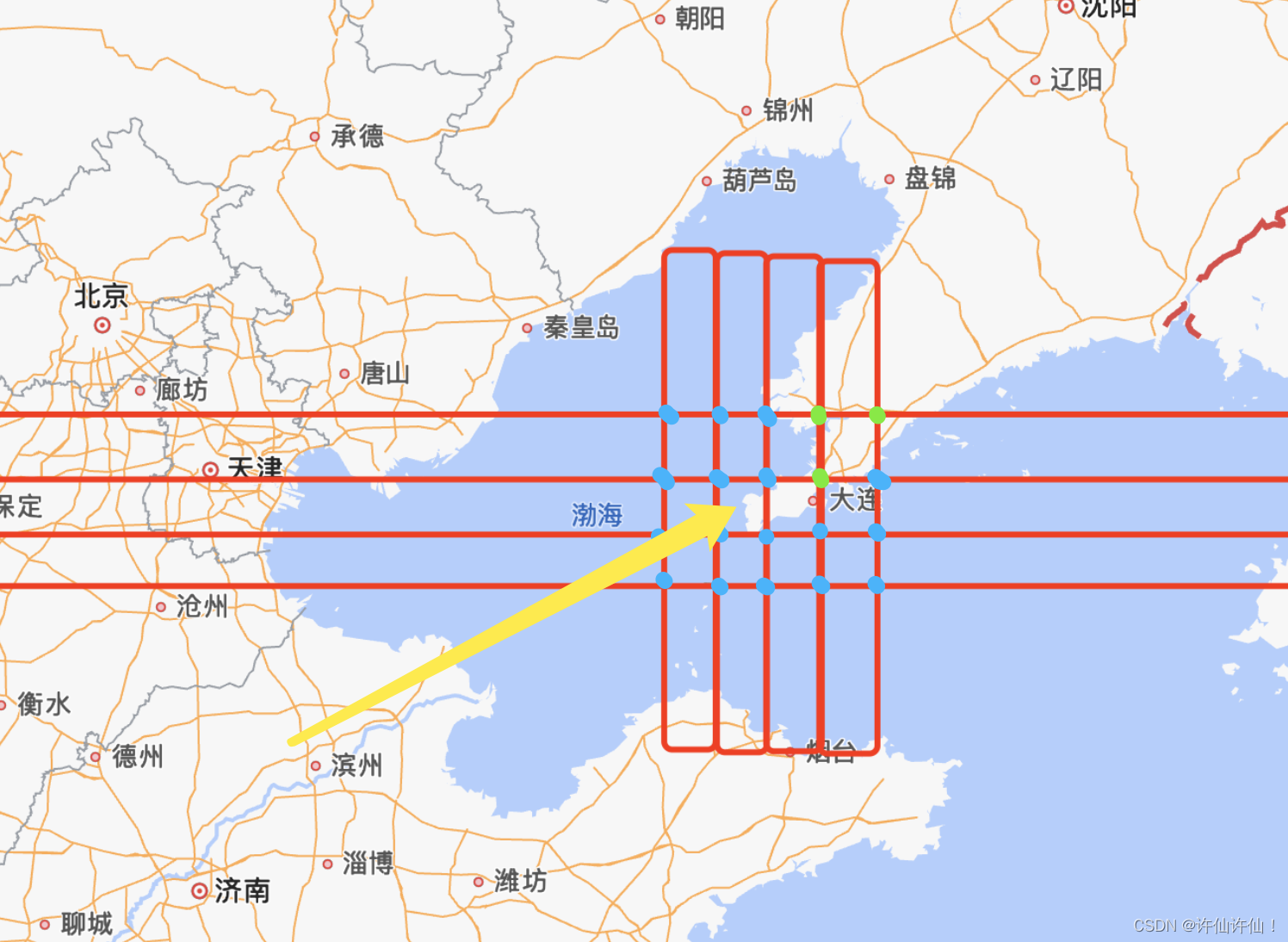
参考上图:
纬度为y轴,跨度为35,间距为1
经度为x轴,跨度为61,间距为1
橙色的点为业务项目对应的经纬度信息(x’,y’)
需要计算出二维坐标中整数点上最靠近的点(利用三角形三边公式)
MIN(aa + bb)
第一层:粉色层
第二层:灰色层
…
由于我们国家的地图存在边界,并不是一个规规矩矩的4方形,且我国的内陆海渤海的包围圈,海洋地区并不计入在二维坐标中,跨度为1的情况下,会出现项目对应的坐标点,需要一层一层对外查找的情况。
二、点位数据
CREATE TABLE `china_grid_map` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主见',`lng` decimal(20,6) NOT NULL COMMENT '经度',`lat` decimal(20,6) NOT NULL COMMENT '纬度',PRIMARY KEY (`id`),KEY `idx_lat` (`lng`),KEY `idx_lng` (`lat`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='自定义中国陆地地图网格经纬度信息';
部分示例数据
INSERT INTO china_grid_map (id, lng, lat) VALUES (1, 74.000000, 39.000000),(3, 74.000000, 40.000000),(4, 75.000000, 37.000000),(5, 75.000000, 38.000000),(7, 75.000000, 39.000000),(9, 75.000000, 40.000000),(11, 76.000000, 37.000000),(13, 76.000000, 38.000000),(15, 76.000000, 39.000000),(17, 76.000000, 40.000000),(18, 77.000000, 36.000000),(20, 77.000000, 37.000000),(22, 77.000000, 38.000000),(24, 77.000000, 39.000000),(26, 77.000000, 40.000000),(28, 77.000000, 41.000000),(30, 78.000000, 36.000000),(32, 78.000000, 37.000000),(34, 78.000000, 38.000000),(36, 78.000000, 39.000000),(38, 78.000000, 40.000000),(40, 78.000000, 41.000000),(42, 79.000000, 32.000000),(44, 79.000000, 34.000000),(46, 79.000000, 35.000000),...
(1911, 131.000000, 44.000000),(1913, 131.000000, 45.000000),(1915, 131.000000, 46.000000),(1917, 131.000000, 47.000000),(1920, 132.000000, 46.000000),(1922, 132.000000, 47.000000),(1925, 133.000000, 46.000000),(1927, 133.000000, 47.000000),(1929, 133.000000, 48.000000),(1930, 134.000000, 47.000000),(1932, 134.000000, 48.000000);
三、实现方式
v1.0 版本 MySQL-直取数据
假设要求的项目坐标点为:
{“lat”: “31.231706”, “lng”: “121.472644”}
第一版本:
直接利用sql,查找出最靠近的四个点,然后再计算距离。
select id, lng, lat
from china_grid_map
where lat <= (select lat as latright from china_grid_map where lat >= 31.231706 order by lat limit 1)and lat >= (select lat as latleft from china_grid_map where lat <= 31.231706 order by lat desc limit 1)and lng <= (select lng as lngright from china_grid_map where lng >= 121.472644 order by lng limit 1)and lng >= (select lng as lngLeft from china_grid_map where lng <= 121.472644 order by lng desc limit 1);
如果查到了点 就求出最小的距离对应的点
如果没查到,重复上面点查询,扩大点数
存在的问题:
1.SQL复杂,如果点位正好在边界上,无论扩充多少层都查不到数据
2.耗时久
v2.0 版本 redis-Zset
{“lat”: “31.231706”, “lng”: “121.472644”}
已经知道步长为1,所以最靠近的点,如图1中所示,直接对x’,y’向下向上取整,组合。
利用redis缓存,使用Zset模型
key存储序列化后的信息,score用经度值
利用Zset的对经度范围取值,score (x,x+1)
对返回的数据再挨个查找,找出映射的id
存在的问题:
1.耗时久,因为按照经度 (x,x+1)取值 还是会得到很多数据,需要循环对比数据 才能得到对应的id
2.批量导入数据时,需要反反复复的从redis中取数据
v3.0 版本 内存-HashMap
Map<String,Long> CACHE = new HashMap<>();
key = lat + “-” + lng
value = id
按照步骤二的模式获取到点列表后,从map中get(key);
如果第一层4个点未命中,扩大到第二层
存在的问题:
1.存在内存中,分布式系统部署,每台服务器上的内存各自独立[好在该点位信息一旦生成后不会修改,在项目初始化后,不存在插入、删除相关的操作,只要考虑查询的时间效率]
2.791个点,消耗的存储比较大:113944
v4.0 版本 内存-二维数组 long[][]
由于点位是提前知道不会变动,且是步长为1的有规则的数据
经度数据区间 : 74 - 134 总个数 61
纬度数据区间 : 19 - 53 总个数 35
private static long[][] GRID_ARRAY = new long[61][35];
在项目启动时初始化缓存数据
public void initCacheByArray() {//先获取到所有的点位数据List<GridMapDO> mapDOS = baseMapper.listAllDO();if (CollectionUtil.isEmpty(mapDOS)) {return;}//循环将数据放入到缓存中for (GridMapDO grid : mapDOS) {int arrayLng = getArrayLng(grid.getLng());int arrayLat = getArrayLat(grid.getLat());if (arrayLng == -1 || arrayLat == -1) {//存在越界的点位log.info(">>>>>>>>>存在越界点位[经度:{},纬度:{}],跳过缓存<<<<<<<", grid.getLng(), grid.getLat());continue;}//找到对应的位置 将id存储为数组的值GRID_ARRAY[arrayLng][arrayLat] = grid.getId();}log.info(">>>> 缓存结束,缓存内容:[{}] <<<<<<", JSONObject.toJSONString(GRID_ARRAY));}private int getArrayLng(BigDecimal lng) {//防止数组下标越界int intLng = lng.intValue();if (intLng < 74 || intLng > 134) {return -1;}return lng.intValue() - 74;}private int getArrayLat(BigDecimal lat) {int intLat = lat.intValue();if (intLat < 19 || intLat > 53) {return -1;}return lat.intValue() - 19;}
用的时候 只需要计算出点位,直接从数组中取对应的下标即可。
如果 GRID_ARRAY[x][y] == 0L 说明点位不是中国的大陆地图
如果 GRID_ARRAY[x][y] != 0L 计算出该点的距离平方
存在的问题:
1.存在内存中,分布式系统部署,每台服务器上的内存各自独立[好在该点位信息一旦生成后不会修改,在项目初始化后,不存在插入、删除相关的操作,只要考虑查询的时间效率]
2.791个点,消耗的存储比V3.0版本减少了1个数量级,但是数组用的是连续的存储空间
四、总结
可以多尝试,找出最合适项目的,结合数据的规律,空间换时间 等等
只有实践了 才能找到最佳的吧…