监控数据的采集方式及原理
采集方法使用频率从高到低依次是读取 /proc目录、执行命令行工具、远程黑盒探测、拉取特定协议的数据、连接到目标对象执行命令、代码埋点、日志解析。
读取 /proc目录
/proc是一个位于内存中的伪文件系统,而在该目录下保存的不是真正的文件和目录,而是一些“运行时”信息,Linux 操作系统层面的很多监控数据,比如内存数据、网卡流量、机器负载等,都是从 /proc中获取的信息。
内存总量、剩余量、可用量、Buffer、Cached 等数据都可以轻易拿到。当然,/proc/meminfo 没有使用率、可用率这样的百分比指标,这类指标需要二次计算,可以在客户端采集器中完成,也可以在服务端查询时现算。内存相关的指标都是 Gauge 类型的。要是不明白什么是Gauge类型,可以参考《监控基本概念》。
执行命令行工具
这种方法调用一下系统命令,解析输出就可以了。比如我们想获取 9090 端口的监听状态,可以使用 ss命令ss -tln|grep 9090,想要拿到各个分区的使用率可以通过df命令 df -k。但是这个方式通用性不好,性能也不好。
就拿ss来说明,不是所有的操作系统都安装了ss,每个Linux发行版的ss版本可能不一致,这样的话就会不好解析输出结果,另外这还需要开启ss一个进程,影响了性能。
远程黑盒探测
典型的手段有HTTP、ICMP和TCP等三种。
ICMP协议,我们可以通过Ping工具做测试,在Linux执行ping -c 3 www.baidu.com可以得到如下图的结果:
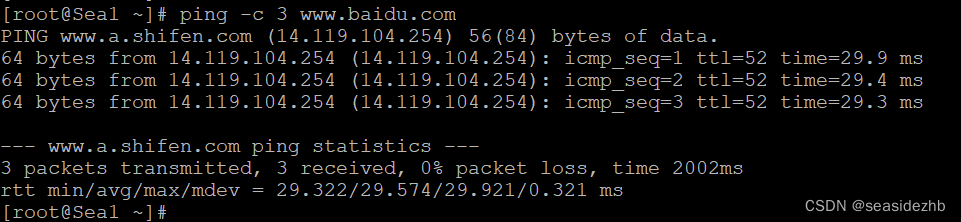
这里我们使用 Ping 工具向 Baidu 发了 3 个数据包,得到了多个指标数据。
丢包率:0%
min rtt:29.322
avg rtt:29.574
max rtt:29.921
ttl:52
监控采集器和手工 Ping 测试的原理是一样的,也是发几个包做统计。不过有些机器是禁 Ping 的,这时候我们就可以通过 TCP 或 HTTP 来探测。对于 Linux 机器,一般是会开放 sshd 的 22 端口,那我们就可以用类似 telnet 的方式探测机器的 22 端口,如果成功就认为机器存活。
对于 HTTP 协议的探测,除了基本的连通性测试,还可以检查协议内容,比如要求返回的 status code 必须是 200,返回的 response body 必须包含 success 字符串,如果任何一个条件没有满足,从监控的角度就认为是异常的。
黑盒监控是把监控对象当成一个黑盒子,不去了解其内部运行机理,只是通过几种协议做简单探测。
拉取特定协议的数据
这是白盒监控的方法。白盒监控收集能够反映监控对象内部运行健康度的指标。但是监控对象的内部指标,从外部其实是无法拿到的,所以它的指标,需要监控对象自身想办法暴露出来。最典型的暴露方式,就是提供一个 HTTP 接口,在 response body 中返回监控指标的数据,比如 Elasticsearch 的 /_cluster/health接口;比如 RabbitMQ,访问/api/overview 可以拿到 Message 数量、Connection 数量等概要信息;再比如 Kubelet,访问/stats/summary可以拿到 Node 和 Pod 等很多概要信息。
不同的接口返回的内容虽然都是指标数据,但是要推给监控服务端,还是要做一次格式转换,比如统一转换为 Prometheus 的文本格式。要是这些组件都直接暴露 Prometheus 的协议数据就好了,使用统一的解析器,就能大大简化监控采集逻辑。
这种拉取监控数据的方式虽然需要做一些数据格式的转换,但并不复杂。因为目标对象会把需要监控的数据直接通过接口暴露出来,监控采集器把数据拉到本地做格式转换即可。
连接到目标对象执行命令
目前最常用的数据库就是 MySQL 和 Redis 了,拿这两个数据库举个例子。
连接到MySQL命令行之后,可以执行show global status like '%onn%';来看一下相关数据:
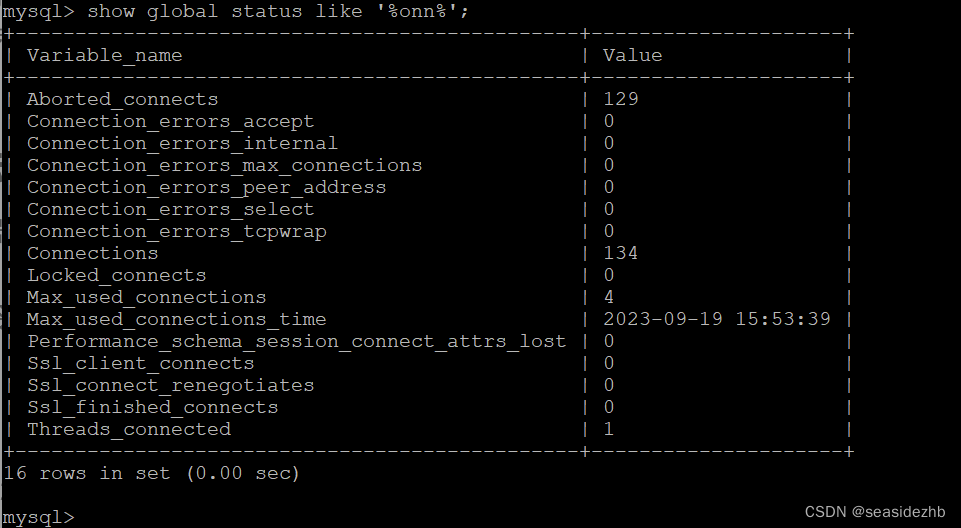
Threads_connected 表示当前有多少连接,Max_used_connections 表示曾经最多有多少连接,Connections 表示总计接收过多少连接。
Redis 也是类似的,比如我们通过 redis-cli 登录到命令行,执行 info memory 命令,就可以看到很多内存相关的指标。
127.0.0.1:6379> info memory
# Memory
used_memory:1345568
used_memory_human:1.28M
used_memory_rss:3653632
used_memory_rss_human:3.48M
used_memory_peak:1504640
used_memory_peak_human:1.43M
used_memory_peak_perc:89.43%
used_memory_overhead:1103288
used_memory_startup:1095648
used_memory_dataset:242280
used_memory_dataset_perc:96.94%
代码埋点
所谓的代码埋点方式,是指应用程序内嵌一些监控相关的 SDK,在请求的关键链路上调用 SDK 的方法,告诉 SDK 当前是个什么请求、耗时多少、是否成功之类的,SDK 汇总这些数据并二次计算,最终推给监控服务端。
日志解析
很多程序可能是外采的,我们没法修改它的源代码,这时候就要使用日志解析的方式了。一般程序都会打印日志,我们可以写日志解析程序,从日志中提取一些关键信息,比如从业务日志中很容易拿到 Exception 关键字出现的次数,从接入层日志中很容易就能拿到某个接口的访问次数。
此文章为9月Day 20学习笔记,内容来源于极客时间《运维监控系统实战笔记》。