全量数据采集:不同网站的方法与挑战
简介
在当今数字化时代中,有数据就能方便我们做出很多决策。数据的获取与分析已经成为学术研究、商业分析、战略决策以及个人好奇心的关键驱动力。本文将分享不同网站的全量数据采集方法,以及在这一过程中可能会遇到的挑战。
部分全量采集方法
1. 撞店铺ID(限店铺ID是数字)
通过循环店铺ID,我们能够收集店铺内所有在售商品的信息。这一方法对于电商分析、竞品研究以及市场趋势分析非常有用。我们可以获取商品的价格、销量、评价等数据,以更好地理解市场动态。
2. 撞商品ID(限商品ID是数字)
通过循环商品ID采集全量商品数据,这对于深入研究特定商品或产品线非常有帮助。我们可以获取商品的详细信息,包括描述、规格、库存情况等,以便于进行进一步的分析和比较。
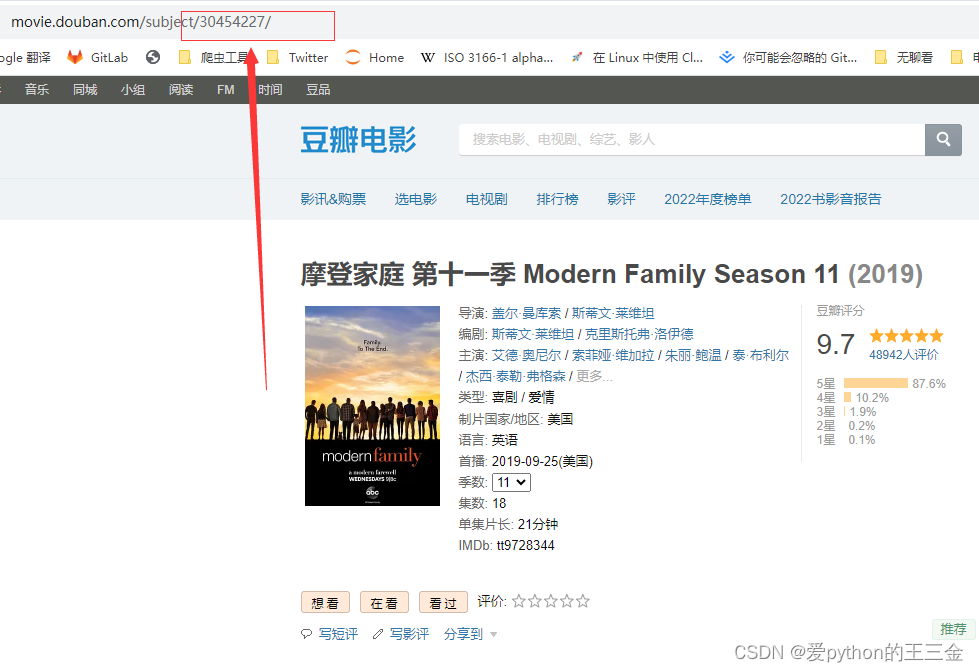
3. 分类入口(适合商品较少的平台)
采集网站的分类数据,利用一级和二级分类作为入口,我们可以采集不同类目的商品数据。这种方法适用于对广泛市场进行概述和对比分析。通过不同分类的数据,我们可以洞察到不同领域的销售趋势和特点。
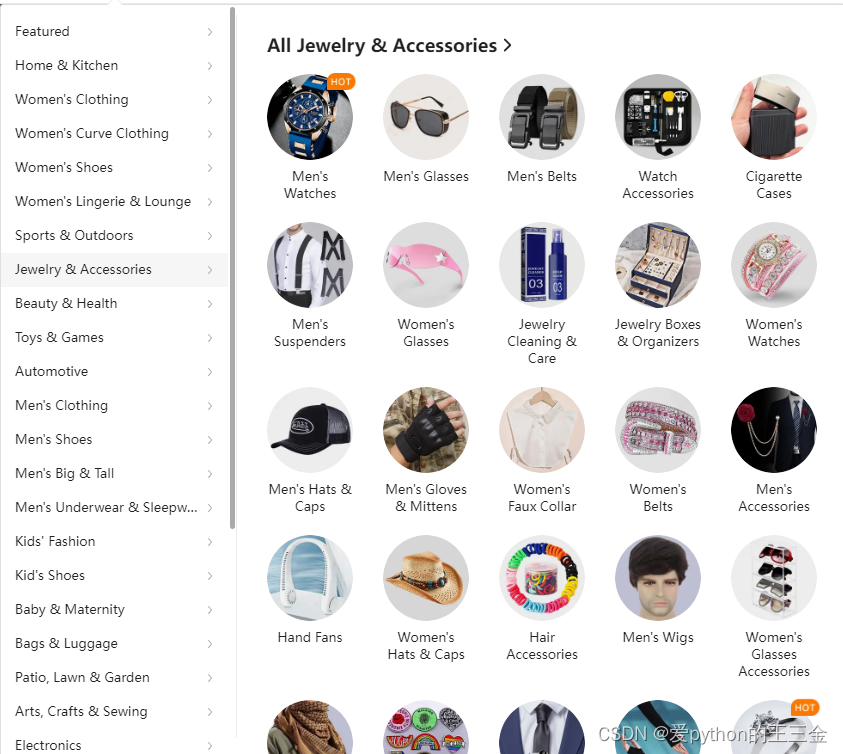
4. 搜索关键词
使用关键词搜索引擎,可以根据用户的搜索需求采集数据。这对于了解用户兴趣和需求非常有用。例如,在电商平台上,我们可以通过热门关键词来追踪热销产品或季节性趋势。

挑战与解决方案
在进行全量数据采集时,我们会面临一些挑战,包括但不限于:
反爬虫机制:网站通常设置了反爬虫机制来限制数据采集,我们需要设计合适的爬虫策略以规避这些机制。
速率限制:网站可能对请求速率进行限制,需要合理控制请求频率,以避免被封禁或限制。
合规性和伦理:我们必须始终遵守数据采集的法律法规和伦理原则,尊重用户隐私和网站的使用政策。
数据处理和存储:采集到的数据需要进行适当的处理和存储,以便后续分析和使用。
解决这些挑战的方法包括:设计智能的爬虫算法、合理控制请求速率、确保数据匿名化、符合法规和政策等。
结语
数据采集是探索数字世界的关键一步。通过了解不同网站的全量数据采集方法,我们能够更深入地了解特定领域、市场和用户行为。然而,我们要谨慎行事,遵守法律和伦理规定,以确保数据采集的合法性和合规性。
爬虫工具是有用的,但思路更加重要,它们可以帮助我们解决数据获取和分析中的各种问题。在我们的数据探索旅程中,让我们永远保持好奇心,同时尊重数据和隐私。